



Daniel Musekamp
@danielmusekamp.bsky.social
PhD student @ University of Stuttgart
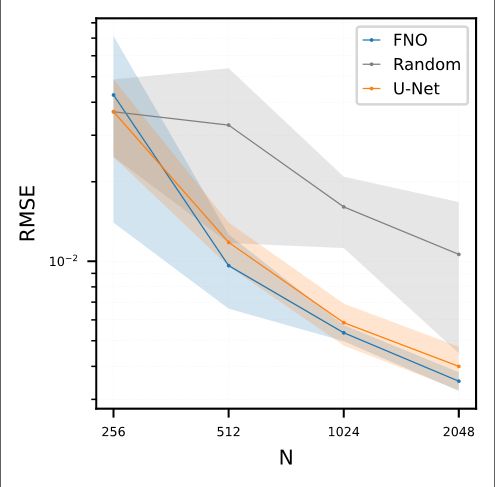
The generated data is also beneficial for surrogate models which have not been used to select the data. Here, we compare the accuracy of a U-Net with data selected randomly or using an FNO or the U-Net itself as the base model. 7/
December 11, 2024 at 6:22 PM
The generated data is also beneficial for surrogate models which have not been used to select the data. Here, we compare the accuracy of a U-Net with data selected randomly or using an FNO or the U-Net itself as the base model. 7/
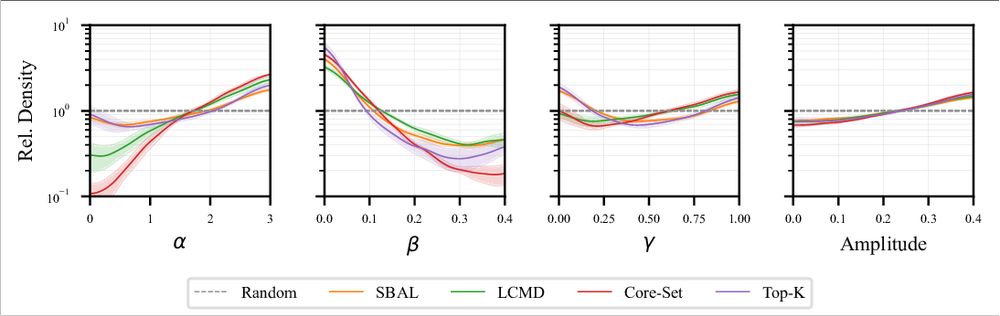
A look at the distribution of the selected parameters shows that the standard deviation between random repetitions is small, indicating that the AL procedure reliably produces very similar datasets. 6/
December 11, 2024 at 6:22 PM
A look at the distribution of the selected parameters shows that the standard deviation between random repetitions is small, indicating that the AL procedure reliably produces very similar datasets. 6/
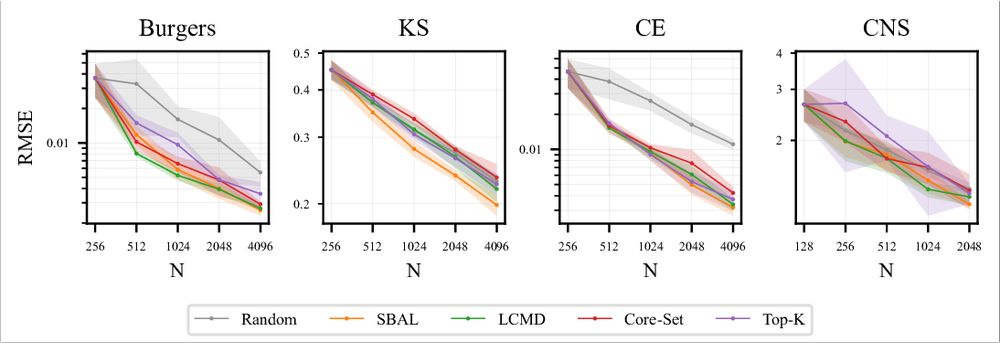
The experiments show that AL reduces the average errors by up to 71% compared to random sampling for the same amount of selected data. Especially, Stochastic Batch Active Learning and LCMD perform well. 5/
December 11, 2024 at 6:22 PM
The experiments show that AL reduces the average errors by up to 71% compared to random sampling for the same amount of selected data. Especially, Stochastic Batch Active Learning and LCMD perform well. 5/
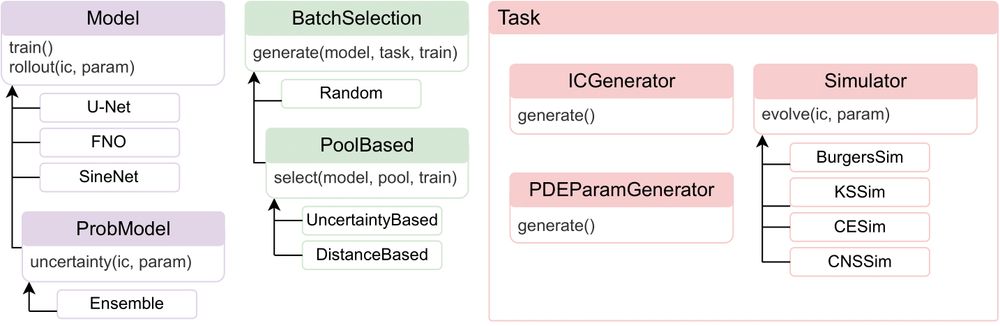
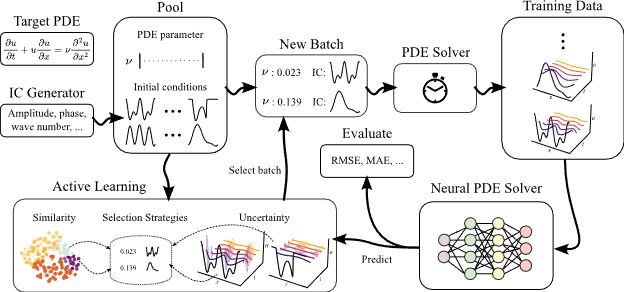
To facilitate the research of AL on autoregressive neural PDE solvers, we introduce AL4PDE, an extensible, modular benchmark framework. It provides:
- Parametric PDEs such as incompressible Navier-Stokes
- Surrogate models (U-Net, FNO, SineNet).
- AL algorithms such as SBAL, CoreSet, or LCMD. 4/
- Parametric PDEs such as incompressible Navier-Stokes
- Surrogate models (U-Net, FNO, SineNet).
- AL algorithms such as SBAL, CoreSet, or LCMD. 4/
December 11, 2024 at 6:22 PM
To facilitate the research of AL on autoregressive neural PDE solvers, we introduce AL4PDE, an extensible, modular benchmark framework. It provides:
- Parametric PDEs such as incompressible Navier-Stokes
- Surrogate models (U-Net, FNO, SineNet).
- AL algorithms such as SBAL, CoreSet, or LCMD. 4/
- Parametric PDEs such as incompressible Navier-Stokes
- Surrogate models (U-Net, FNO, SineNet).
- AL algorithms such as SBAL, CoreSet, or LCMD. 4/
Neural surrogates can accelerate PDE solving but need expensive ground-truth training data. Can we reduce the training data size with active learning (AL)? In our NeurIPS D3S3 poster, we introduce AL4PDE, an extensible AL benchmark for autoregressive neural PDE solvers. 🧵
December 11, 2024 at 6:22 PM
Neural surrogates can accelerate PDE solving but need expensive ground-truth training data. Can we reduce the training data size with active learning (AL)? In our NeurIPS D3S3 poster, we introduce AL4PDE, an extensible AL benchmark for autoregressive neural PDE solvers. 🧵