


@causalwizard.bsky.social
The original HRM paper by Wang et al can be found here:
arxiv.org/abs/2506.21734
arxiv.org/abs/2506.21734

Hierarchical Reasoning Model
Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current large language models (LLMs) primarily employ Chain-of-Thought (CoT...
arxiv.org
October 29, 2025 at 7:36 AM
The original HRM paper by Wang et al can be found here:
arxiv.org/abs/2506.21734
arxiv.org/abs/2506.21734
Our paper is simply a proof-of-concept and our model is the simplest possible RL agent version of HRM. We're looking forward to working with more sophisticated recurrent reasoning models like HRM and TRM on more complex problems.
Code:
github.com/LongDangHoan...
Code:
github.com/LongDangHoan...

GitHub - LongDangHoang/HRM_RL_Agent: HRM Agent repo
HRM Agent repo. Contribute to LongDangHoang/HRM_RL_Agent development by creating an account on GitHub.
github.com
October 29, 2025 at 7:36 AM
Our paper is simply a proof-of-concept and our model is the simplest possible RL agent version of HRM. We're looking forward to working with more sophisticated recurrent reasoning models like HRM and TRM on more complex problems.
Code:
github.com/LongDangHoan...
Code:
github.com/LongDangHoan...
In addition, by analyzing the divergence of the latent state we found evidence that the resulting plans (paths) are more consistent over time.

October 29, 2025 at 7:35 AM
In addition, by analyzing the divergence of the latent state we found evidence that the resulting plans (paths) are more consistent over time.
In dynamic environments, it's important for plan continuity and efficiency to reuse computation from previous environment time-steps. We found that the recurrent process in the HRM-Agent model converges more quickly when the latent state is copied across from previous time-steps.
October 29, 2025 at 7:33 AM
In dynamic environments, it's important for plan continuity and efficiency to reuse computation from previous environment time-steps. We found that the recurrent process in the HRM-Agent model converges more quickly when the latent state is copied across from previous time-steps.
The ARC-prize team came to similar conclusions about the importance of recurrence during inference:
arcprize.org/blog/hrm-ana...
arcprize.org/blog/hrm-ana...

The Hidden Drivers of HRM's Performance on ARC-AGI
We scored on hidden tasks, ran ablations, and found that performance from the Hierarchical Reasoning Model comes from an unexpected source
arcprize.org
October 29, 2025 at 7:33 AM
The ARC-prize team came to similar conclusions about the importance of recurrence during inference:
arcprize.org/blog/hrm-ana...
arcprize.org/blog/hrm-ana...
Why is HRM so efficient at reasoning tasks? Check out "Less is More: Recursive Reasoning with Tiny Networks" by Alexia Jolicoeur-Martineau. Her simplified model explores the recurrent concept introduced in HRM which seems to be responsible for much of the performance.
arxiv.org/abs/2510.04871
arxiv.org/abs/2510.04871
Less is More: Recursive Reasoning with Tiny Networks
Hierarchical Reasoning Model (HRM) is a novel approach using two small neural networks recursing at different frequencies. This biologically inspired method beats Large Language models (LLMs) on hard ...
arxiv.org
October 29, 2025 at 7:32 AM
Why is HRM so efficient at reasoning tasks? Check out "Less is More: Recursive Reasoning with Tiny Networks" by Alexia Jolicoeur-Martineau. Her simplified model explores the recurrent concept introduced in HRM which seems to be responsible for much of the performance.
arxiv.org/abs/2510.04871
arxiv.org/abs/2510.04871
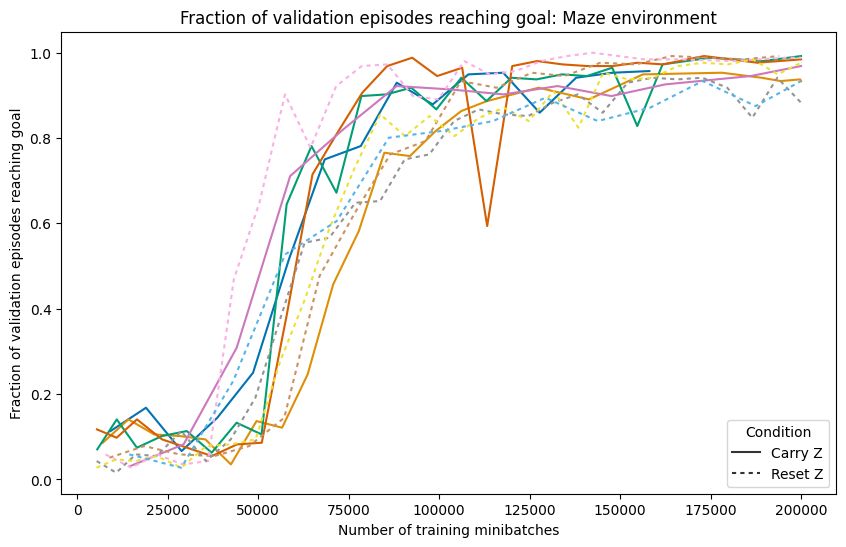
We found that the HRM-Agent can learn to navigate in dynamic and uncertain maze environments, with doors which open and close randomly.
October 29, 2025 at 7:31 AM
We found that the HRM-Agent can learn to navigate in dynamic and uncertain maze environments, with doors which open and close randomly.
The Hierarchical Reasoning Model (HRM) has impressive reasoning abilities given its small size, but has only been applied to supervised, static, fully-observable problems.
We wanted to see if we could train a HRM to navigate in a maze using only reinforcement learning.
We wanted to see if we could train a HRM to navigate in a maze using only reinforcement learning.

October 29, 2025 at 7:30 AM
The Hierarchical Reasoning Model (HRM) has impressive reasoning abilities given its small size, but has only been applied to supervised, static, fully-observable problems.
We wanted to see if we could train a HRM to navigate in a maze using only reinforcement learning.
We wanted to see if we could train a HRM to navigate in a maze using only reinforcement learning.
I couldn't find Conf_CLeaR or any existing post on BlueSky...
March 30, 2025 at 6:05 AM
I couldn't find Conf_CLeaR or any existing post on BlueSky...
Can we make this the official way to draw the set of unobserved confounders...?
December 13, 2024 at 3:11 AM
Can we make this the official way to draw the set of unobserved confounders...?
That feeling when you've carefully embedded the figures in the right place and the journal has a template which insists they all have to go at the end 😭
December 8, 2024 at 6:44 AM
That feeling when you've carefully embedded the figures in the right place and the journal has a template which insists they all have to go at the end 😭