




Andreas Kirsch
@blackhc.bsky.social
My opinions only here.
👨🔬 RS DeepMind
Past:
👨🔬 R Midjourney 1y 🧑🎓 DPhil AIMS Uni of Oxford 4.5y
🧙♂️ RE DeepMind 1y 📺 SWE Google 3y 🎓 TUM
👤 @nwspk
👨🔬 RS DeepMind
Past:
👨🔬 R Midjourney 1y 🧑🎓 DPhil AIMS Uni of Oxford 4.5y
🧙♂️ RE DeepMind 1y 📺 SWE Google 3y 🎓 TUM
👤 @nwspk
Because the urban warfare during the counterinsurgency, 60% of the buildings were destroyed during fighting in the course of a couple of months. This is in line with the report you cited above.
How is this war in Gaza different to that war?
en.m.wikipedia.org/wiki/Falluja...
How is this war in Gaza different to that war?
en.m.wikipedia.org/wiki/Falluja...

June 29, 2025 at 8:19 AM
Because the urban warfare during the counterinsurgency, 60% of the buildings were destroyed during fighting in the course of a couple of months. This is in line with the report you cited above.
How is this war in Gaza different to that war?
en.m.wikipedia.org/wiki/Falluja...
How is this war in Gaza different to that war?
en.m.wikipedia.org/wiki/Falluja...
I want to point to one more claim which is already outdated (the relevant paper was only published a few days ago so hardly anyone's fault):
The ProRL paper by Nvidia has shown that RL-based models can truly learn new things - if you run RL long enough!
arxiv.org/abs/2505.24864
The ProRL paper by Nvidia has shown that RL-based models can truly learn new things - if you run RL long enough!
arxiv.org/abs/2505.24864

June 9, 2025 at 9:49 PM
I want to point to one more claim which is already outdated (the relevant paper was only published a few days ago so hardly anyone's fault):
The ProRL paper by Nvidia has shown that RL-based models can truly learn new things - if you run RL long enough!
arxiv.org/abs/2505.24864
The ProRL paper by Nvidia has shown that RL-based models can truly learn new things - if you run RL long enough!
arxiv.org/abs/2505.24864
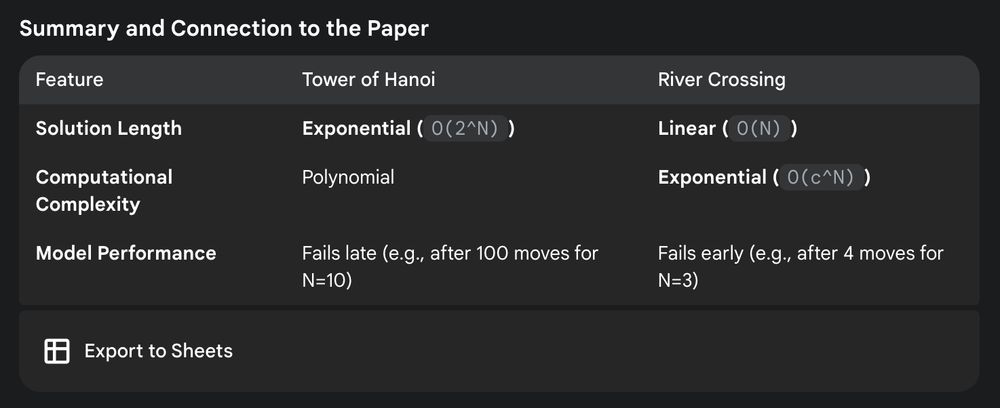
But as Gemini 2.5 Pro explains, River Crossing's optimal solutions are rather short, but they have a high branching factor and number of possible states with dead-ends.
That models fail here is a lot more interesting and points towards areas of improvements.
That models fail here is a lot more interesting and points towards areas of improvements.
June 9, 2025 at 9:49 PM
But as Gemini 2.5 Pro explains, River Crossing's optimal solutions are rather short, but they have a high branching factor and number of possible states with dead-ends.
That models fail here is a lot more interesting and points towards areas of improvements.
That models fail here is a lot more interesting and points towards areas of improvements.
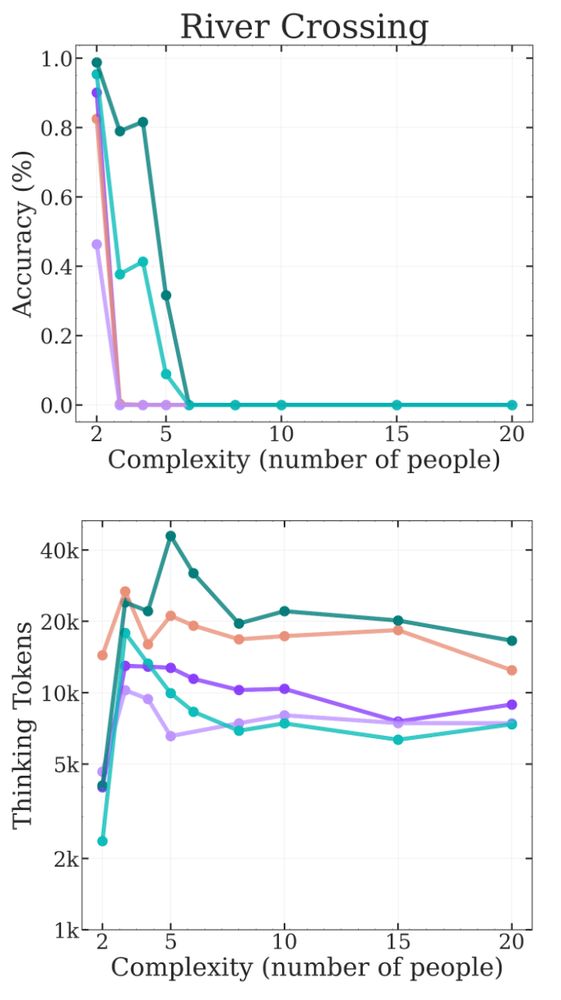
All in all, the Tower of Hanoi results cannot be given any credence because it seems there are many confounders and simpler explanations.
However, I don't think the other games hit the same issues. If we look at River Crossing it seems to hit high token counts very quickly:
However, I don't think the other games hit the same issues. If we look at River Crossing it seems to hit high token counts very quickly:
June 9, 2025 at 9:49 PM
All in all, the Tower of Hanoi results cannot be given any credence because it seems there are many confounders and simpler explanations.
However, I don't think the other games hit the same issues. If we look at River Crossing it seems to hit high token counts very quickly:
However, I don't think the other games hit the same issues. If we look at River Crossing it seems to hit high token counts very quickly:
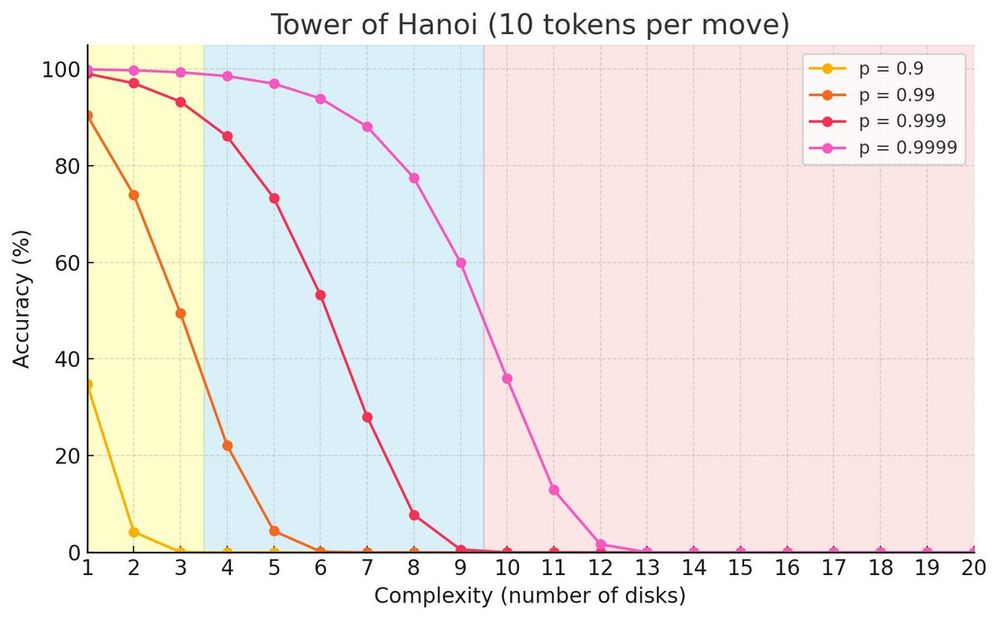
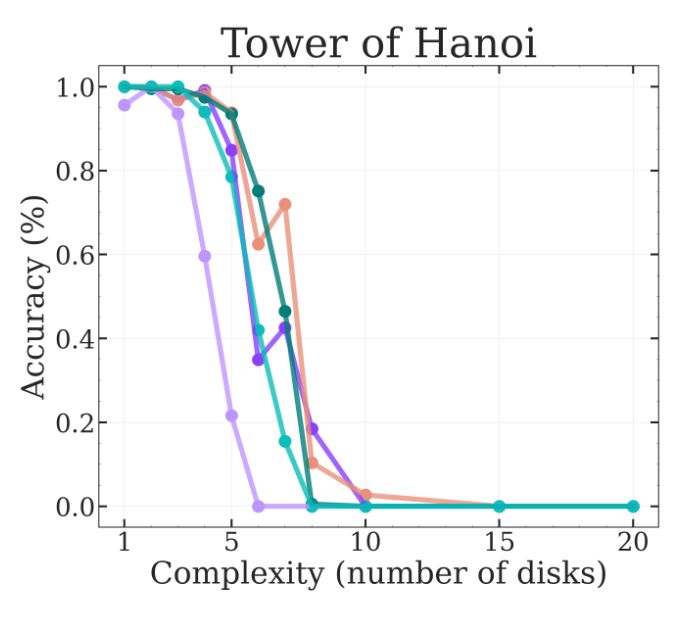
We use top-p or top-k sampling with a temperature of 0.7 after all. Thus, there is a chance the model gets unlucky and the wrong token is sampled, resulting in failure. (They should really try min-p 😀)
@scaling01 has a nice toy model that matches the paper results:
@scaling01 has a nice toy model that matches the paper results:
June 9, 2025 at 9:49 PM
We use top-p or top-k sampling with a temperature of 0.7 after all. Thus, there is a chance the model gets unlucky and the wrong token is sampled, resulting in failure. (They should really try min-p 😀)
@scaling01 has a nice toy model that matches the paper results:
@scaling01 has a nice toy model that matches the paper results:
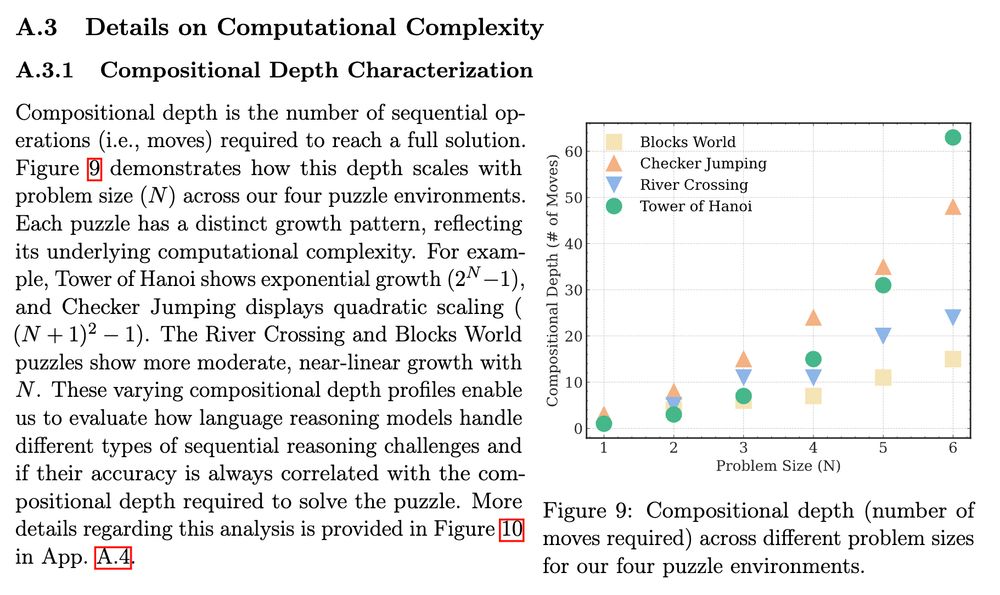
Otoh, Tower of Hanoi is rather straightforward. BUT it requires many steps (2^N - 1, where N is the number of disks). LLMs already know the optimal algorithm to solve it, so the only problem is writing out all those steps! Performing well on ToH is not about reasoning at all 🫠
June 9, 2025 at 9:49 PM
Otoh, Tower of Hanoi is rather straightforward. BUT it requires many steps (2^N - 1, where N is the number of disks). LLMs already know the optimal algorithm to solve it, so the only problem is writing out all those steps! Performing well on ToH is not about reasoning at all 🫠
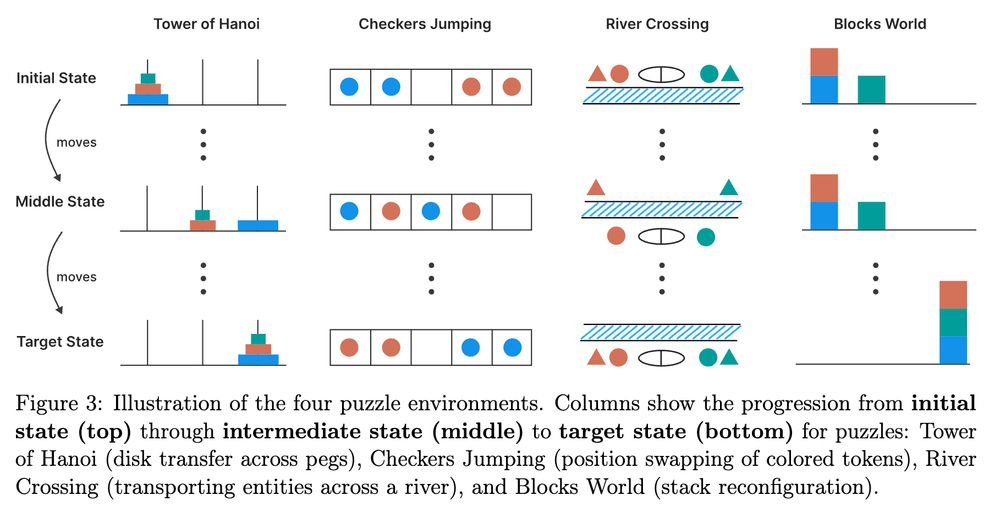
The paper explores four puzzle environments: Tower of Hanoi, Checkers Jumping, River Crossing, and Blocks World.
It finds some "surprising" behavior of LRMs: they can perform 100 correct steps on the Tower of Hanoi, but only 4 steps on River Crossing.
x.com/MFarajtabar...
It finds some "surprising" behavior of LRMs: they can perform 100 correct steps on the Tower of Hanoi, but only 4 steps on River Crossing.
x.com/MFarajtabar...
June 9, 2025 at 9:49 PM
The paper explores four puzzle environments: Tower of Hanoi, Checkers Jumping, River Crossing, and Blocks World.
It finds some "surprising" behavior of LRMs: they can perform 100 correct steps on the Tower of Hanoi, but only 4 steps on River Crossing.
x.com/MFarajtabar...
It finds some "surprising" behavior of LRMs: they can perform 100 correct steps on the Tower of Hanoi, but only 4 steps on River Crossing.
x.com/MFarajtabar...
Important Caveat:
Real-world scenarios introduce complexities—approximation errors, model dynamics, and training stochasticity can affect submodularity assumptions.
Practical methods must balance theoretical ideals with these realities.
8/11
Real-world scenarios introduce complexities—approximation errors, model dynamics, and training stochasticity can affect submodularity assumptions.
Practical methods must balance theoretical ideals with these realities.
8/11

May 17, 2025 at 11:47 AM
Important Caveat:
Real-world scenarios introduce complexities—approximation errors, model dynamics, and training stochasticity can affect submodularity assumptions.
Practical methods must balance theoretical ideals with these realities.
8/11
Real-world scenarios introduce complexities—approximation errors, model dynamics, and training stochasticity can affect submodularity assumptions.
Practical methods must balance theoretical ideals with these realities.
8/11
Practical Example:
An active learning experiment on MNIST using a LeNet-5 model with Monte Carlo dropout selecting via BALD scores (expected information gain).
We can visualize how sample informativeness evolves dynamically during training (w/ EMA for visualization):
6/11
An active learning experiment on MNIST using a LeNet-5 model with Monte Carlo dropout selecting via BALD scores (expected information gain).
We can visualize how sample informativeness evolves dynamically during training (w/ EMA for visualization):
6/11
May 17, 2025 at 11:47 AM
Practical Example:
An active learning experiment on MNIST using a LeNet-5 model with Monte Carlo dropout selecting via BALD scores (expected information gain).
We can visualize how sample informativeness evolves dynamically during training (w/ EMA for visualization):
6/11
An active learning experiment on MNIST using a LeNet-5 model with Monte Carlo dropout selecting via BALD scores (expected information gain).
We can visualize how sample informativeness evolves dynamically during training (w/ EMA for visualization):
6/11
Data Filtering leverages submodularity explicitly:
It confidently rejects samples early, knowing that initially uninformative samples rarely become valuable later. This makes early filtering safe and efficient.
5/11
It confidently rejects samples early, knowing that initially uninformative samples rarely become valuable later. This makes early filtering safe and efficient.
5/11

May 17, 2025 at 11:47 AM
Data Filtering leverages submodularity explicitly:
It confidently rejects samples early, knowing that initially uninformative samples rarely become valuable later. This makes early filtering safe and efficient.
5/11
It confidently rejects samples early, knowing that initially uninformative samples rarely become valuable later. This makes early filtering safe and efficient.
5/11
Active Learning leverages submodularity implicitly:
It continuously re-evaluates sample informativeness during training. A sample highly informative initially might become redundant after training on similar examples.
4/11
It continuously re-evaluates sample informativeness during training. A sample highly informative initially might become redundant after training on similar examples.
4/11

May 17, 2025 at 11:47 AM
Active Learning leverages submodularity implicitly:
It continuously re-evaluates sample informativeness during training. A sample highly informative initially might become redundant after training on similar examples.
4/11
It continuously re-evaluates sample informativeness during training. A sample highly informative initially might become redundant after training on similar examples.
4/11
Because sample informativeness typically exhibits **submodularity**: each additional data point provides diminishing returns in terms of new information.
3/11
3/11

May 17, 2025 at 11:47 AM
Because sample informativeness typically exhibits **submodularity**: each additional data point provides diminishing returns in terms of new information.
3/11
3/11
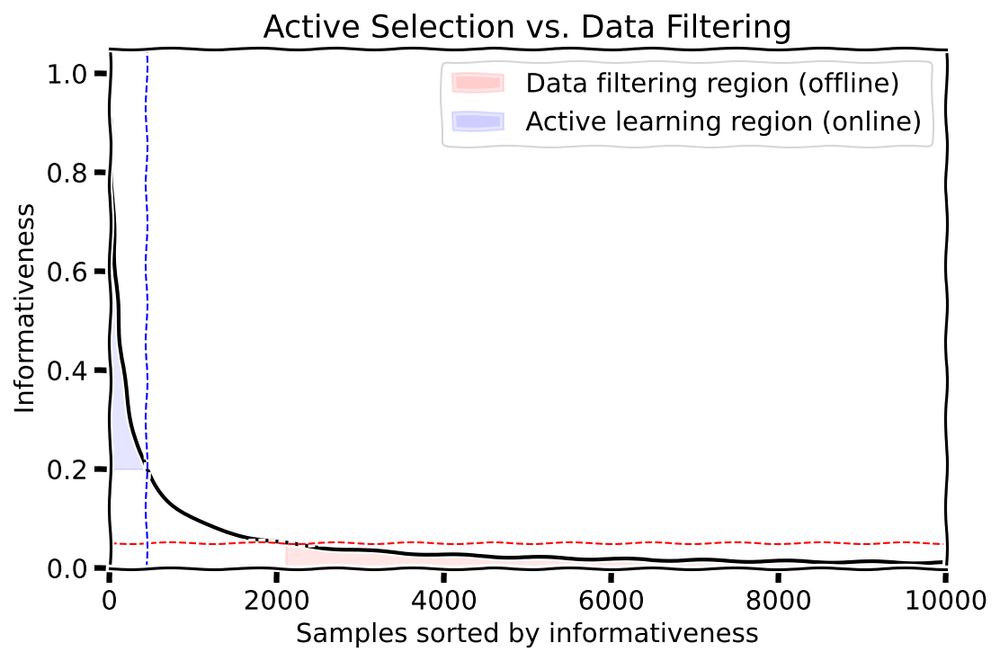
Active Learning selects samples iteratively during training (online), while
Data Filtering rejects samples upfront before training starts (offline).
This significantly impacts how we approach data selection, but why should we phrase this as "selection vs. rejection"?
2/11
Data Filtering rejects samples upfront before training starts (offline).
This significantly impacts how we approach data selection, but why should we phrase this as "selection vs. rejection"?
2/11
May 17, 2025 at 11:47 AM
Active Learning selects samples iteratively during training (online), while
Data Filtering rejects samples upfront before training starts (offline).
This significantly impacts how we approach data selection, but why should we phrase this as "selection vs. rejection"?
2/11
Data Filtering rejects samples upfront before training starts (offline).
This significantly impacts how we approach data selection, but why should we phrase this as "selection vs. rejection"?
2/11
I want to share my latest (very short) blog post: "Active Learning vs. Data Filtering: Selection vs. Rejection."
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
May 17, 2025 at 11:47 AM
I want to share my latest (very short) blog post: "Active Learning vs. Data Filtering: Selection vs. Rejection."
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
💡 Key empirical insight: We can estimate the single parameter (ε) of our model without requiring ground truth labels, making it highly practical.

April 23, 2025 at 11:20 AM
💡 Key empirical insight: We can estimate the single parameter (ε) of our model without requiring ground truth labels, making it highly practical.
📈 Exciting finding: With a simplified probabilistic model that's technically misspecified, we achieve excellent results across diverse datasets and model collections.

April 23, 2025 at 11:20 AM
📈 Exciting finding: With a simplified probabilistic model that's technically misspecified, we achieve excellent results across diverse datasets and model collections.
🤓 The method is theoretically grounded in information theory and optimal experiment design, treating the identity of the best model as a random variable we want to learn about.

April 23, 2025 at 11:20 AM
🤓 The method is theoretically grounded in information theory and optimal experiment design, treating the identity of the best model as a random variable we want to learn about.
🚀 Results are impressive:
- Up to 94% reduction in labeling costs compared to baselines
- Consistently identifies the best model with significantly fewer labels
- Even in worst-case scenarios, selects models very close to the best
- Up to 94% reduction in labeling costs compared to baselines
- Consistently identifies the best model with significantly fewer labels
- Even in worst-case scenarios, selects models very close to the best

April 23, 2025 at 11:20 AM
🚀 Results are impressive:
- Up to 94% reduction in labeling costs compared to baselines
- Consistently identifies the best model with significantly fewer labels
- Even in worst-case scenarios, selects models very close to the best
- Up to 94% reduction in labeling costs compared to baselines
- Consistently identifies the best model with significantly fewer labels
- Even in worst-case scenarios, selects models very close to the best
🔍 Key Problem:
With thousands of pre-trained models available on platforms like @huggingface, how do we select the BEST one for a custom task when labeling data is expensive?
Blog post with details: www.blackhc.net/blog/2025/m...
With thousands of pre-trained models available on platforms like @huggingface, how do we select the BEST one for a custom task when labeling data is expensive?
Blog post with details: www.blackhc.net/blog/2025/m...

April 23, 2025 at 11:20 AM
🔍 Key Problem:
With thousands of pre-trained models available on platforms like @huggingface, how do we select the BEST one for a custom task when labeling data is expensive?
Blog post with details: www.blackhc.net/blog/2025/m...
With thousands of pre-trained models available on platforms like @huggingface, how do we select the BEST one for a custom task when labeling data is expensive?
Blog post with details: www.blackhc.net/blog/2025/m...
I want to share a blog post on our paper "All Models are Wrong, Some are Useful: Model Selection with Limited Labels" which we will present at AISTATS 2025 next week
With @pokanovic.bsky.social, Jannes Kasper, @thoefler.bsky.social, @arkrause.bsky.social, and @nmervegurel.bsky.social
With @pokanovic.bsky.social, Jannes Kasper, @thoefler.bsky.social, @arkrause.bsky.social, and @nmervegurel.bsky.social

April 23, 2025 at 11:20 AM
I want to share a blog post on our paper "All Models are Wrong, Some are Useful: Model Selection with Limited Labels" which we will present at AISTATS 2025 next week
With @pokanovic.bsky.social, Jannes Kasper, @thoefler.bsky.social, @arkrause.bsky.social, and @nmervegurel.bsky.social
With @pokanovic.bsky.social, Jannes Kasper, @thoefler.bsky.social, @arkrause.bsky.social, and @nmervegurel.bsky.social
💻 Computational benefits:
* Selection requires 2τn forward passes (fully parallelizable)
* 5× reduction in total compute when matching baseline performance
* Selection requires 2τn forward passes (fully parallelizable)
* 5× reduction in total compute when matching baseline performance

April 5, 2025 at 12:05 PM
💻 Computational benefits:
* Selection requires 2τn forward passes (fully parallelizable)
* 5× reduction in total compute when matching baseline performance
* Selection requires 2τn forward passes (fully parallelizable)
* 5× reduction in total compute when matching baseline performance
🔬 Technical details:
* Small auxiliary models (150M params) effectively select data for larger models (1.2B params)
* Continues improving even when selecting just 1 in 64 candidates from the training data
* Small auxiliary models (150M params) effectively select data for larger models (1.2B params)
* Continues improving even when selecting just 1 in 64 candidates from the training data
April 5, 2025 at 12:05 PM
🔬 Technical details:
* Small auxiliary models (150M params) effectively select data for larger models (1.2B params)
* Continues improving even when selecting just 1 in 64 candidates from the training data
* Small auxiliary models (150M params) effectively select data for larger models (1.2B params)
* Continues improving even when selecting just 1 in 64 candidates from the training data
📈 Fascinating finding: Batch-wise selection performs as well as (or slightly better than) global selection, aligning with recent active learning literature on stochastic batch acquisition.

April 5, 2025 at 12:05 PM
📈 Fascinating finding: Batch-wise selection performs as well as (or slightly better than) global selection, aligning with recent active learning literature on stochastic batch acquisition.
🤓 The method is theoretically grounded in empirical Bayes and can be interpreted through the pointwise mutual information (PMI) between the training data and downstream tasks.

April 5, 2025 at 12:04 PM
🤓 The method is theoretically grounded in empirical Bayes and can be interpreted through the pointwise mutual information (PMI) between the training data and downstream tasks.
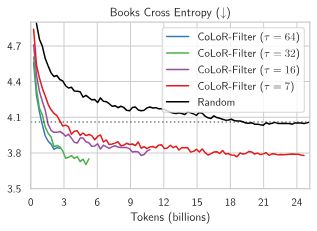
🚀 Results are striking:
25× data reduction for Books domain adaptation
11× data reduction for downstream tasks
All while maintaining the same performance levels!
25× data reduction for Books domain adaptation
11× data reduction for downstream tasks
All while maintaining the same performance levels!

April 5, 2025 at 12:04 PM
🚀 Results are striking:
25× data reduction for Books domain adaptation
11× data reduction for downstream tasks
All while maintaining the same performance levels!
25× data reduction for Books domain adaptation
11× data reduction for downstream tasks
All while maintaining the same performance levels!