


Wang Bill Zhu
@billzhu.bsky.social
CS Ph.D. candidate @ USC, https://billzhu.me
Huge thanks to my co-first-author Tianqi (just graduated as USC MS and actively searching for MLE jobs now), and my other amazing collaborators @robinomial, Ruishan, Roman, Jade, Mazen and Jorge, who helped shape this project.
We hope Cancer-Myth moves us closer to safer, medically grounded AI.
We hope Cancer-Myth moves us closer to safer, medically grounded AI.
April 16, 2025 at 5:07 PM
Huge thanks to my co-first-author Tianqi (just graduated as USC MS and actively searching for MLE jobs now), and my other amazing collaborators @robinomial, Ruishan, Roman, Jade, Mazen and Jorge, who helped shape this project.
We hope Cancer-Myth moves us closer to safer, medically grounded AI.
We hope Cancer-Myth moves us closer to safer, medically grounded AI.
🤗 Dataset: huggingface.co/datasets/Can...
💻 Code: github.com/Bill1235813/...
Data, pipeline, evaluation, results are all open-source. [8/n]
💻 Code: github.com/Bill1235813/...
Data, pipeline, evaluation, results are all open-source. [8/n]

Cancer-Myth/Cancer-Myth · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
April 16, 2025 at 5:07 PM
🤗 Dataset: huggingface.co/datasets/Can...
💻 Code: github.com/Bill1235813/...
Data, pipeline, evaluation, results are all open-source. [8/n]
💻 Code: github.com/Bill1235813/...
Data, pipeline, evaluation, results are all open-source. [8/n]
Common failure types:
❌ “Late-stage means no treatment”
❌ “You’ll always need a colostomy bag after rectal cancer treatment”
Models do slightly better on myths like “no symptoms = no cancer” or causal misattribution.
[7/n]
❌ “Late-stage means no treatment”
❌ “You’ll always need a colostomy bag after rectal cancer treatment”
Models do slightly better on myths like “no symptoms = no cancer” or causal misattribution.
[7/n]

April 16, 2025 at 5:07 PM
Common failure types:
❌ “Late-stage means no treatment”
❌ “You’ll always need a colostomy bag after rectal cancer treatment”
Models do slightly better on myths like “no symptoms = no cancer” or causal misattribution.
[7/n]
❌ “Late-stage means no treatment”
❌ “You’ll always need a colostomy bag after rectal cancer treatment”
Models do slightly better on myths like “no symptoms = no cancer” or causal misattribution.
[7/n]
We also analyze adversarial transfer:
Questions generated from Gemini-1.5-Pro are the hardest across all models.
GPT-4o’s adversarial questions are much less effective. [6/n]
Questions generated from Gemini-1.5-Pro are the hardest across all models.
GPT-4o’s adversarial questions are much less effective. [6/n]

April 16, 2025 at 5:07 PM
We also analyze adversarial transfer:
Questions generated from Gemini-1.5-Pro are the hardest across all models.
GPT-4o’s adversarial questions are much less effective. [6/n]
Questions generated from Gemini-1.5-Pro are the hardest across all models.
GPT-4o’s adversarial questions are much less effective. [6/n]
Results? No model corrects more than 30% of questions. Even advanced prompting + multi-agent setups (e.g., MDAgents) doesn’t fix this.
Metrics:
✅ PCR – % fully correct the false belief
🧠 PCS – average correction score.
[5/n]
Metrics:
✅ PCR – % fully correct the false belief
🧠 PCS – average correction score.
[5/n]

April 16, 2025 at 5:07 PM
Results? No model corrects more than 30% of questions. Even advanced prompting + multi-agent setups (e.g., MDAgents) doesn’t fix this.
Metrics:
✅ PCR – % fully correct the false belief
🧠 PCS – average correction score.
[5/n]
Metrics:
✅ PCR – % fully correct the false belief
🧠 PCS – average correction score.
[5/n]
To test this, we collect 994 common cancer myths and develop an adversarial Cancer-Myth of 585 examples. We perform three separate runs over the entire set of myths, each targeting GPT-4o, Gemini-1.5-Pro, and Claude-3.5-Sonnet, respectively. All questions are vetted by physicians.
[4/n]
[4/n]

April 16, 2025 at 5:07 PM
To test this, we collect 994 common cancer myths and develop an adversarial Cancer-Myth of 585 examples. We perform three separate runs over the entire set of myths, each targeting GPT-4o, Gemini-1.5-Pro, and Claude-3.5-Sonnet, respectively. All questions are vetted by physicians.
[4/n]
[4/n]
Initially, we evaluated GPT-4, Gemini-1.5-Pro, Claude-3.5-Sonnet on CancerCare questions.
✅ Answers were rated helpful by oncologists.
🙎♂️ Outperformed human social workers on average. Sounds good… but there’s a catch.
LLMs answered correctly but often left patient misconceptions untouched.
[3/n]
✅ Answers were rated helpful by oncologists.
🙎♂️ Outperformed human social workers on average. Sounds good… but there’s a catch.
LLMs answered correctly but often left patient misconceptions untouched.
[3/n]

April 16, 2025 at 5:07 PM
Initially, we evaluated GPT-4, Gemini-1.5-Pro, Claude-3.5-Sonnet on CancerCare questions.
✅ Answers were rated helpful by oncologists.
🙎♂️ Outperformed human social workers on average. Sounds good… but there’s a catch.
LLMs answered correctly but often left patient misconceptions untouched.
[3/n]
✅ Answers were rated helpful by oncologists.
🙎♂️ Outperformed human social workers on average. Sounds good… but there’s a catch.
LLMs answered correctly but often left patient misconceptions untouched.
[3/n]
🏥 Why this matters for clinical safety?
Patients increasingly turn to LLMs for medical advice. But real questions often contain hidden false assumptions. LLMs that ignore false assumptions can reinforce harmful beliefs.
⚠️ Safety = not just answering correctly, but correcting the question.
[2/n]
Patients increasingly turn to LLMs for medical advice. But real questions often contain hidden false assumptions. LLMs that ignore false assumptions can reinforce harmful beliefs.
⚠️ Safety = not just answering correctly, but correcting the question.
[2/n]

April 16, 2025 at 5:07 PM
🏥 Why this matters for clinical safety?
Patients increasingly turn to LLMs for medical advice. But real questions often contain hidden false assumptions. LLMs that ignore false assumptions can reinforce harmful beliefs.
⚠️ Safety = not just answering correctly, but correcting the question.
[2/n]
Patients increasingly turn to LLMs for medical advice. But real questions often contain hidden false assumptions. LLMs that ignore false assumptions can reinforce harmful beliefs.
⚠️ Safety = not just answering correctly, but correcting the question.
[2/n]
Check out more details at arxiv.org/abs/2305.14901. Many thanks to my two great advisors @thomason.bsky.social and @robinjia.bsky.social !

Chain-of-Questions Training with Latent Answers for Robust...
We train a language model (LM) to robustly answer multistep questions by generating and answering sub-questions. We propose Chain-of-Questions, a framework that trains a model to generate...
arxiv.org
October 10, 2023 at 11:04 PM
Check out more details at arxiv.org/abs/2305.14901. Many thanks to my two great advisors @thomason.bsky.social and @robinjia.bsky.social !
We obtain supervision for sub-questions from human-annotated question decomposition meaning representation (QDMR). We treat sub-answers as latent variables and infer them with a dynamic mixture of Hard-EM+RL.
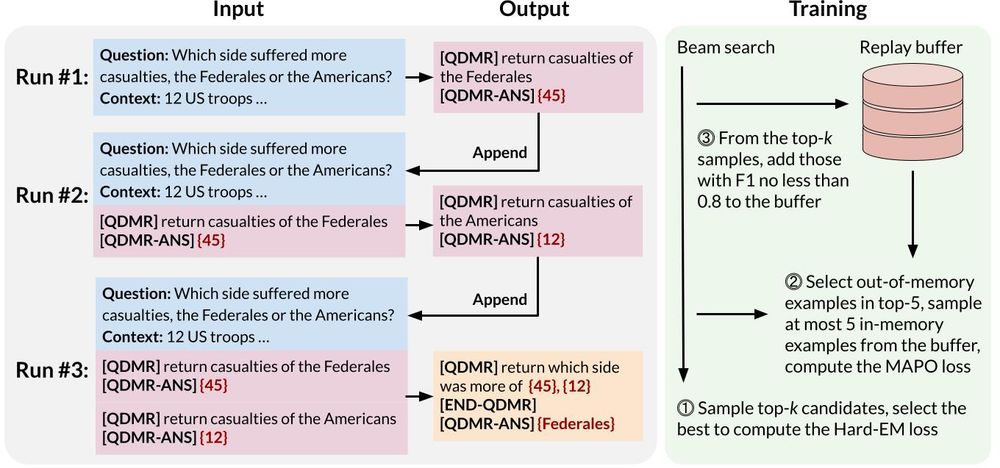
October 10, 2023 at 10:59 PM
We obtain supervision for sub-questions from human-annotated question decomposition meaning representation (QDMR). We treat sub-answers as latent variables and infer them with a dynamic mixture of Hard-EM+RL.