


Wang Bill Zhu
@billzhu.bsky.social
CS Ph.D. candidate @ USC, https://billzhu.me
At @naaclmeeting.bsky.social this week! I’ll be presenting our work on LLM domain induction with @thomason.bsky.social on Thu (5/1) at 4pm in Hall 3, Section I.
Would love to connect and chat about LLM planning, reasoning, AI4Science, multimodal stuff, or anything else. Feel free to DM!
Would love to connect and chat about LLM planning, reasoning, AI4Science, multimodal stuff, or anything else. Feel free to DM!

April 30, 2025 at 6:38 PM
At @naaclmeeting.bsky.social this week! I’ll be presenting our work on LLM domain induction with @thomason.bsky.social on Thu (5/1) at 4pm in Hall 3, Section I.
Would love to connect and chat about LLM planning, reasoning, AI4Science, multimodal stuff, or anything else. Feel free to DM!
Would love to connect and chat about LLM planning, reasoning, AI4Science, multimodal stuff, or anything else. Feel free to DM!
🚨 New work!
LLMs often sound helpful—but fail to challenge dangerous medical misconceptions in real patient questions.
We test how well LLMs handle false assumptions in oncology Q&A.
📝 Paper: arxiv.org/abs/2504.11373
🌐 Website: cancermyth.github.io
👇 [1/n]
LLMs often sound helpful—but fail to challenge dangerous medical misconceptions in real patient questions.
We test how well LLMs handle false assumptions in oncology Q&A.
📝 Paper: arxiv.org/abs/2504.11373
🌐 Website: cancermyth.github.io
👇 [1/n]

Cancer-Myth: Evaluating AI Chatbot on Patient Questions with False Presuppositions
Cancer patients are increasingly turning to large language models (LLMs) as a new form of internet search for medical information, making it critical to assess how well these models handle complex, pe...
arxiv.org
April 16, 2025 at 5:07 PM
🚨 New work!
LLMs often sound helpful—but fail to challenge dangerous medical misconceptions in real patient questions.
We test how well LLMs handle false assumptions in oncology Q&A.
📝 Paper: arxiv.org/abs/2504.11373
🌐 Website: cancermyth.github.io
👇 [1/n]
LLMs often sound helpful—but fail to challenge dangerous medical misconceptions in real patient questions.
We test how well LLMs handle false assumptions in oncology Q&A.
📝 Paper: arxiv.org/abs/2504.11373
🌐 Website: cancermyth.github.io
👇 [1/n]
Reposted by Wang Bill Zhu

I'll be at #NeurIPS2024! My group has papers analyzing how LLMs use Fourier Features for arithmetic and how TFs learn higher-order optimization for ICL (led by @deqing.bsky.social), plus workshop papers on backdoor detection and LLMs + PDDL (led by @billzhu.bsky.social)
December 9, 2024 at 10:21 PM
I'll be at #NeurIPS2024! My group has papers analyzing how LLMs use Fourier Features for arithmetic and how TFs learn higher-order optimization for ICL (led by @deqing.bsky.social), plus workshop papers on backdoor detection and LLMs + PDDL (led by @billzhu.bsky.social)
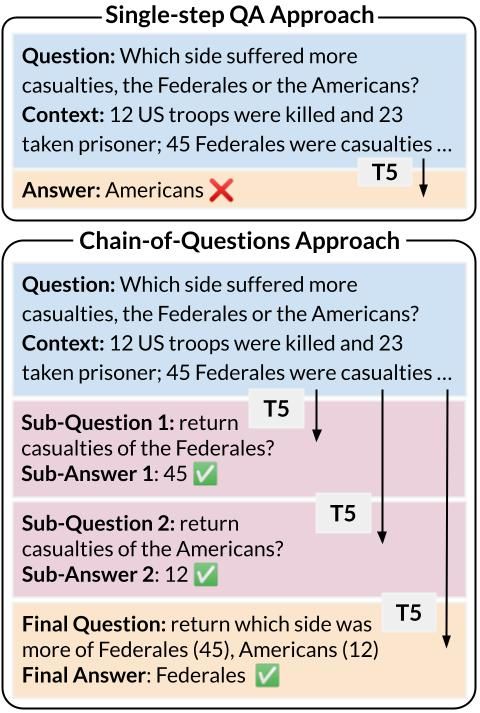
✨ Excited to share our Chain-of-Questions paper #EMNLP2023: we develop a framework that trains *one T5 model* to robustly answer multistep questions by generating and answering sub-questions. Outperforms ChatGPT on DROP, HotpotQA and their contrast/adversarial sets.
October 10, 2023 at 10:57 PM
✨ Excited to share our Chain-of-Questions paper #EMNLP2023: we develop a framework that trains *one T5 model* to robustly answer multistep questions by generating and answering sub-questions. Outperforms ChatGPT on DROP, HotpotQA and their contrast/adversarial sets.