



Dawid Ostrowski
@avedave.com
Developer Relations, AI, Local LLMs, Technology, Startups, Dup15q, Rare Diseases, Genetics, Switzerland, Poland, Google
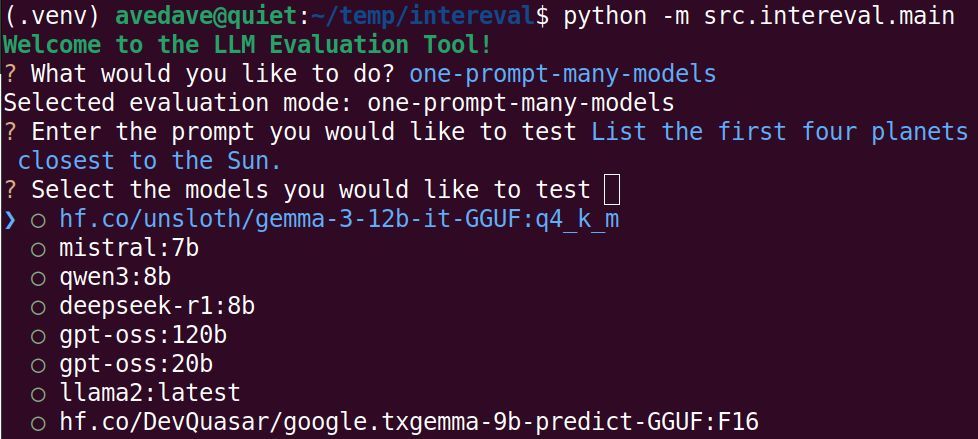
I created Intereval - a command-line tool designed to streamline the evaluation and comparison of Large Language Models (LLMs) available locally through Ollama.
- Interactively test prompt against multiple models.
- Test multiple prompts against the same model
github.com/avedave/inte...
- Interactively test prompt against multiple models.
- Test multiple prompts against the same model
github.com/avedave/inte...



September 11, 2025 at 8:37 PM
I created Intereval - a command-line tool designed to streamline the evaluation and comparison of Large Language Models (LLMs) available locally through Ollama.
- Interactively test prompt against multiple models.
- Test multiple prompts against the same model
github.com/avedave/inte...
- Interactively test prompt against multiple models.
- Test multiple prompts against the same model
github.com/avedave/inte...
A few benchmarks of running various models on my 2 x NVIDIA RTX 5060ti 16GB setup.
Results (Model, Total Duration, Response Processing)
Gemma:
- 1B (0m:4s, 212 t/s)
- 4B (0m:8s, 108 t/s)
- 12B (0m:18s, 44 t/s)
- 27B (0m:42s, 22 t/s)
DeepSeek R1 70B (7m:31s, 3.04 t/s)
Results (Model, Total Duration, Response Processing)
Gemma:
- 1B (0m:4s, 212 t/s)
- 4B (0m:8s, 108 t/s)
- 12B (0m:18s, 44 t/s)
- 27B (0m:42s, 22 t/s)
DeepSeek R1 70B (7m:31s, 3.04 t/s)




August 20, 2025 at 10:56 PM
A few benchmarks of running various models on my 2 x NVIDIA RTX 5060ti 16GB setup.
Results (Model, Total Duration, Response Processing)
Gemma:
- 1B (0m:4s, 212 t/s)
- 4B (0m:8s, 108 t/s)
- 12B (0m:18s, 44 t/s)
- 27B (0m:42s, 22 t/s)
DeepSeek R1 70B (7m:31s, 3.04 t/s)
Results (Model, Total Duration, Response Processing)
Gemma:
- 1B (0m:4s, 212 t/s)
- 4B (0m:8s, 108 t/s)
- 12B (0m:18s, 44 t/s)
- 27B (0m:42s, 22 t/s)
DeepSeek R1 70B (7m:31s, 3.04 t/s)
7 years, -40kg (-88lbs)
Today marks a special milestone on my journey towards a healthier life!
If you are interested in learning how I did it, leave a comment. I might turn my notes into an actual PDF and share with you.
Today marks a special milestone on my journey towards a healthier life!
If you are interested in learning how I did it, leave a comment. I might turn my notes into an actual PDF and share with you.

July 8, 2025 at 8:27 PM
7 years, -40kg (-88lbs)
Today marks a special milestone on my journey towards a healthier life!
If you are interested in learning how I did it, leave a comment. I might turn my notes into an actual PDF and share with you.
Today marks a special milestone on my journey towards a healthier life!
If you are interested in learning how I did it, leave a comment. I might turn my notes into an actual PDF and share with you.
Very insightful talk! How AI and synthetic biology can be used for a lot of good, but also cause harm - and what precautions we can take as a society.

KEYNOTE: The Bioweapons Are Coming
YouTube video by World Summit AI
youtu.be
July 7, 2025 at 8:56 AM
Very insightful talk! How AI and synthetic biology can be used for a lot of good, but also cause harm - and what precautions we can take as a society.
Intensive but rewarding week in Berlin! 3 events, keynote highlight of the project I'm involved in, MC-ing AI stage, leading feedback roundtables but most importantly, reconnecting with the team and the community!




June 27, 2025 at 5:52 AM
Intensive but rewarding week in Berlin! 3 events, keynote highlight of the project I'm involved in, MC-ing AI stage, leading feedback roundtables but most importantly, reconnecting with the team and the community!
I love being a host, so it was a real pleasure to be the host and MC at the AI Stage of Google I/O Connect Berlin event!


June 25, 2025 at 12:26 PM
I love being a host, so it was a real pleasure to be the host and MC at the AI Stage of Google I/O Connect Berlin event!
Google I/O Connect Berlin begins!!!




June 25, 2025 at 8:48 AM
Google I/O Connect Berlin begins!!!
As I delivered a workshop on ADK + Cloud Run in Hamburg yesterday, the rest of Google decided to make Gemini 2.5 Pro and Flash Generally Available! Yay! There's also a new Gemini Flash-Lite available in preview




June 18, 2025 at 6:50 AM
As I delivered a workshop on ADK + Cloud Run in Hamburg yesterday, the rest of Google decided to make Gemini 2.5 Pro and Flash Generally Available! Yay! There's also a new Gemini Flash-Lite available in preview
I had a chance to host at Google an incredible event - 4th Polish Economic and Technology Forum in Switzerland! On top of leading a panel, I also had a chance to deliver a workshop showcasing Google's AI models and tools!




May 28, 2025 at 8:19 PM
I had a chance to host at Google an incredible event - 4th Polish Economic and Technology Forum in Switzerland! On top of leading a panel, I also had a chance to deliver a workshop showcasing Google's AI models and tools!
Stay tuned for Gemma updates!
Next week is Google IO and there are many cool things happening! 🎉🎉🎉
One of them is this presentation I'll give with my college Omar talking about Gemma models
It will be recorded and streamed!
io.google/2025/explore...
One of them is this presentation I'll give with my college Omar talking about Gemma models
It will be recorded and streamed!
io.google/2025/explore...

Google I/O 2025: What's new in the Gemmaverse
Don’t miss Google I/O, featuring product launches, innovations, and insights. Tune in for the live keynotes and sessions.
io.google
May 18, 2025 at 4:38 PM
Stay tuned for Gemma updates!
Solid crowd today at the GDG Cloud Zurich!


May 15, 2025 at 4:34 PM
Solid crowd today at the GDG Cloud Zurich!
Reposted by Dawid Ostrowski

Run Gemma 3 27B on your desktop GPU 🔥
Our new QAT-optimized int4 models slash VRAM needs (54GB -> 14.1GB) while maintaining quality.
Now accessible on consumer cards like the NVIDIA RTX 3090 via ollama, hugging face, lmstudio, kaggle and llama.cpp
developers.googleblog.com/en/gemma-3-q...
Our new QAT-optimized int4 models slash VRAM needs (54GB -> 14.1GB) while maintaining quality.
Now accessible on consumer cards like the NVIDIA RTX 3090 via ollama, hugging face, lmstudio, kaggle and llama.cpp
developers.googleblog.com/en/gemma-3-q...

April 18, 2025 at 4:09 PM
Run Gemma 3 27B on your desktop GPU 🔥
Our new QAT-optimized int4 models slash VRAM needs (54GB -> 14.1GB) while maintaining quality.
Now accessible on consumer cards like the NVIDIA RTX 3090 via ollama, hugging face, lmstudio, kaggle and llama.cpp
developers.googleblog.com/en/gemma-3-q...
Our new QAT-optimized int4 models slash VRAM needs (54GB -> 14.1GB) while maintaining quality.
Now accessible on consumer cards like the NVIDIA RTX 3090 via ollama, hugging face, lmstudio, kaggle and llama.cpp
developers.googleblog.com/en/gemma-3-q...
Reposted by Dawid Ostrowski
Simplify running Gemma 3 locally! 🐳+💎
Docker now supports Gemma 3 via the Docker Model Runner. Learn how to leverage these powerful models on your machine using familiar tools. Great for dev/testing!
www.docker.com/blog/run-gem...
Docker now supports Gemma 3 via the Docker Model Runner. Learn how to leverage these powerful models on your machine using familiar tools. Great for dev/testing!
www.docker.com/blog/run-gem...

How to Run Gemma 3 Locally with Docker Model Runner | Docker
Explore how to run Gemma 3 models locally using Docker Model Runner, alongside a Comment Processing System as a practical case study.
www.docker.com
April 16, 2025 at 11:00 AM
Simplify running Gemma 3 locally! 🐳+💎
Docker now supports Gemma 3 via the Docker Model Runner. Learn how to leverage these powerful models on your machine using familiar tools. Great for dev/testing!
www.docker.com/blog/run-gem...
Docker now supports Gemma 3 via the Docker Model Runner. Learn how to leverage these powerful models on your machine using familiar tools. Great for dev/testing!
www.docker.com/blog/run-gem...
If you are an individual domiciled in, or a company with a principal place of business in the European Union, make sure to check with your lawyers the Llama 4 Use Policy: www.llama.com/llama4/use-p...

April 7, 2025 at 7:50 AM
If you are an individual domiciled in, or a company with a principal place of business in the European Union, make sure to check with your lawyers the Llama 4 Use Policy: www.llama.com/llama4/use-p...
I had the pleasure to be a guest of the Angular Master podcast led by the famous @ngkalbarczyk.bsky.social
We talked about the Google Developer Experts program and Developer Relations in general. Lots of fun!
www.youtube.com/watch?v=fHjZ...
We talked about the Google Developer Experts program and Developer Relations in general. Lots of fun!
www.youtube.com/watch?v=fHjZ...

AMP 69: GDE Deep Dive: Building a Program That Developers Love by Dawid Ostrowski
YouTube video by NG Poland Conf
www.youtube.com
March 31, 2025 at 11:21 AM
I had the pleasure to be a guest of the Angular Master podcast led by the famous @ngkalbarczyk.bsky.social
We talked about the Google Developer Experts program and Developer Relations in general. Lots of fun!
www.youtube.com/watch?v=fHjZ...
We talked about the Google Developer Experts program and Developer Relations in general. Lots of fun!
www.youtube.com/watch?v=fHjZ...
TxGemma is a collection of open models designed to improve the efficiency of therapeutic development by leveraging the power of LLMs! Trained to assist throughout the entire discovery process, from identifying promising targets to helping predict clinical trial outcomes.
Learn more: bit.ly/3E14JP1
Learn more: bit.ly/3E14JP1
March 28, 2025 at 2:47 PM
TxGemma is a collection of open models designed to improve the efficiency of therapeutic development by leveraging the power of LLMs! Trained to assist throughout the entire discovery process, from identifying promising targets to helping predict clinical trial outcomes.
Learn more: bit.ly/3E14JP1
Learn more: bit.ly/3E14JP1
Gemini 2.5 Pro is out there and you should really try it in Google's AI Studio.
What used to be a full-weekend project can now be generated within seconds!
My prompt: "p5js (no HTML) colorful implementation of the game of life"
Worked on the first attempt :)
What used to be a full-weekend project can now be generated within seconds!
My prompt: "p5js (no HTML) colorful implementation of the game of life"
Worked on the first attempt :)
March 26, 2025 at 4:59 PM
Gemini 2.5 Pro is out there and you should really try it in Google's AI Studio.
What used to be a full-weekend project can now be generated within seconds!
My prompt: "p5js (no HTML) colorful implementation of the game of life"
Worked on the first attempt :)
What used to be a full-weekend project can now be generated within seconds!
My prompt: "p5js (no HTML) colorful implementation of the game of life"
Worked on the first attempt :)
I had a great time hosting "Shaping the future" event and learning from the top industry experts about Legal, Tax and Regulatory Insights in New Technologies




March 26, 2025 at 2:48 PM
I had a great time hosting "Shaping the future" event and learning from the top industry experts about Legal, Tax and Regulatory Insights in New Technologies
Reposted by Dawid Ostrowski

Śliwka w chmurze! ☁️ Zobacz, jak uruchomić Polish Large Language Model (PLLuM) na Google Cloud. Mój nowy film - www.youtube.com/watch?v=fJcC...
#PLLuM #GoogleCloud #AI #ML #LLM
#PLLuM #GoogleCloud #AI #ML #LLM

Polish Large Language Model (PLLuM) na Google Cloud
YouTube video by Remigiusz Samborski
www.youtube.com
March 25, 2025 at 8:04 AM
Śliwka w chmurze! ☁️ Zobacz, jak uruchomić Polish Large Language Model (PLLuM) na Google Cloud. Mój nowy film - www.youtube.com/watch?v=fJcC...
#PLLuM #GoogleCloud #AI #ML #LLM
#PLLuM #GoogleCloud #AI #ML #LLM
Reposted by Dawid Ostrowski

📝 Friendly reminder that Google Meet can automatically transcribe, summarize, and identify action items in your meetings (no plug-ins required):

March 24, 2025 at 3:44 PM
📝 Friendly reminder that Google Meet can automatically transcribe, summarize, and identify action items in your meetings (no plug-ins required):
Full house at the GDG Cloud Zurich event yesterday!

March 21, 2025 at 8:12 AM
Full house at the GDG Cloud Zurich event yesterday!
It's nice to see out-of-the box Gemma 3 27B to be leading the pack for the Polish LLM mt-bench-pl benchmark :)

March 20, 2025 at 4:25 PM
It's nice to see out-of-the box Gemma 3 27B to be leading the pack for the Polish LLM mt-bench-pl benchmark :)
I recorded a video on how to run Gemma 3 locally on a laptop, but the procedure is so simple, that an animated GIF is a better format :)
1. Download Llama: ollama.com
2. Install Llama
3. Pull Gemma 3 1B from the repository: ollama pull gemma3:1b
4. Run the model locally: ollama run gemma3:1b
1. Download Llama: ollama.com
2. Install Llama
3. Pull Gemma 3 1B from the repository: ollama pull gemma3:1b
4. Run the model locally: ollama run gemma3:1b
March 20, 2025 at 1:58 PM
I recorded a video on how to run Gemma 3 locally on a laptop, but the procedure is so simple, that an animated GIF is a better format :)
1. Download Llama: ollama.com
2. Install Llama
3. Pull Gemma 3 1B from the repository: ollama pull gemma3:1b
4. Run the model locally: ollama run gemma3:1b
1. Download Llama: ollama.com
2. Install Llama
3. Pull Gemma 3 1B from the repository: ollama pull gemma3:1b
4. Run the model locally: ollama run gemma3:1b
Gemma 3 was announced on March 12th, at a very nice event in Paris :) I led a feedback session with the product team :)
Details:
- 1B, 4B, 12B, 27B sizes
- support for 140+ languages
- multimodal inputs
- 128k context window
- currently the best model that can run on a single GPU or TPU
Details:
- 1B, 4B, 12B, 27B sizes
- support for 140+ languages
- multimodal inputs
- 128k context window
- currently the best model that can run on a single GPU or TPU




March 16, 2025 at 8:57 PM
Gemma 3 was announced on March 12th, at a very nice event in Paris :) I led a feedback session with the product team :)
Details:
- 1B, 4B, 12B, 27B sizes
- support for 140+ languages
- multimodal inputs
- 128k context window
- currently the best model that can run on a single GPU or TPU
Details:
- 1B, 4B, 12B, 27B sizes
- support for 140+ languages
- multimodal inputs
- 128k context window
- currently the best model that can run on a single GPU or TPU