



Amadeus
@amadeusz.bsky.social
hacker @hsp.sh | mlops | ai builder | socdem | 🇵🇱
Reposted by Amadeus

“Continuous Thought Machines”
Blog → sakana.ai/ctm
Modern AI is powerful, but it's still distinct from human-like flexible intelligence. We believe neural timing is key. Our Continuous Thought Machine is built from the ground up to use neural dynamics as a powerful representation for intelligence.
Blog → sakana.ai/ctm
Modern AI is powerful, but it's still distinct from human-like flexible intelligence. We believe neural timing is key. Our Continuous Thought Machine is built from the ground up to use neural dynamics as a powerful representation for intelligence.
May 12, 2025 at 2:33 AM
“Continuous Thought Machines”
Blog → sakana.ai/ctm
Modern AI is powerful, but it's still distinct from human-like flexible intelligence. We believe neural timing is key. Our Continuous Thought Machine is built from the ground up to use neural dynamics as a powerful representation for intelligence.
Blog → sakana.ai/ctm
Modern AI is powerful, but it's still distinct from human-like flexible intelligence. We believe neural timing is key. Our Continuous Thought Machine is built from the ground up to use neural dynamics as a powerful representation for intelligence.
Reposted by Amadeus

Kimi-Audio 🚀🎧 an OPEN audio foundation model released by Moonshot AI
huggingface.co/moonshotai/K...
✨ 7B
✨ 13M+ hours of pretraining data
✨ Novel hybrid input architecture
✨ Universal audio capabilities (ASR, AQA, AAC, SER, SEC/ASC, end-to-end conversation)
huggingface.co/moonshotai/K...
✨ 7B
✨ 13M+ hours of pretraining data
✨ Novel hybrid input architecture
✨ Universal audio capabilities (ASR, AQA, AAC, SER, SEC/ASC, end-to-end conversation)

moonshotai/Kimi-Audio-7B-Instruct · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
April 28, 2025 at 7:34 AM
Kimi-Audio 🚀🎧 an OPEN audio foundation model released by Moonshot AI
huggingface.co/moonshotai/K...
✨ 7B
✨ 13M+ hours of pretraining data
✨ Novel hybrid input architecture
✨ Universal audio capabilities (ASR, AQA, AAC, SER, SEC/ASC, end-to-end conversation)
huggingface.co/moonshotai/K...
✨ 7B
✨ 13M+ hours of pretraining data
✨ Novel hybrid input architecture
✨ Universal audio capabilities (ASR, AQA, AAC, SER, SEC/ASC, end-to-end conversation)
Reposted by Amadeus

🚨New DeepSeek Model Incoming🚨
but first they release the paper describing generative reward modeling (GRM) via Self-Principled Critique Tuning (SPCT)
looking forward to DeepSeek-GRM!
arxiv.org/abs/2504.02495
but first they release the paper describing generative reward modeling (GRM) via Self-Principled Critique Tuning (SPCT)
looking forward to DeepSeek-GRM!
arxiv.org/abs/2504.02495

April 4, 2025 at 10:45 AM
🚨New DeepSeek Model Incoming🚨
but first they release the paper describing generative reward modeling (GRM) via Self-Principled Critique Tuning (SPCT)
looking forward to DeepSeek-GRM!
arxiv.org/abs/2504.02495
but first they release the paper describing generative reward modeling (GRM) via Self-Principled Critique Tuning (SPCT)
looking forward to DeepSeek-GRM!
arxiv.org/abs/2504.02495
Reposted by Amadeus

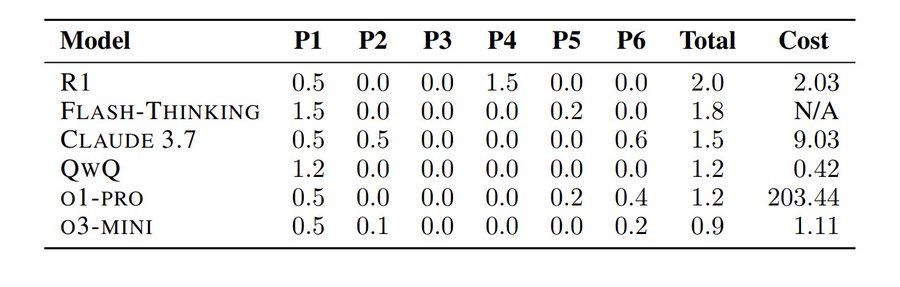
You’ve probably heard about how AI/LLMs can solve Math Olympiad problems ( deepmind.google/discover/blo... ).
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
March 31, 2025 at 8:33 PM
You’ve probably heard about how AI/LLMs can solve Math Olympiad problems ( deepmind.google/discover/blo... ).
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
Reposted by Amadeus

February 27, 2025 at 10:53 PM
Reposted by Amadeus
This is new - Moonshot AI (i.e., kimi.ai) released the two open-weigh models.
Moonlight: 3B/16B MoE model trained with Muon on 5.7T tokens, advancing the Pareto frontier with better performance at fewer FLOPs.
huggingface.co/moonshotai
Moonlight: 3B/16B MoE model trained with Muon on 5.7T tokens, advancing the Pareto frontier with better performance at fewer FLOPs.
huggingface.co/moonshotai

February 22, 2025 at 8:20 PM
This is new - Moonshot AI (i.e., kimi.ai) released the two open-weigh models.
Moonlight: 3B/16B MoE model trained with Muon on 5.7T tokens, advancing the Pareto frontier with better performance at fewer FLOPs.
huggingface.co/moonshotai
Moonlight: 3B/16B MoE model trained with Muon on 5.7T tokens, advancing the Pareto frontier with better performance at fewer FLOPs.
huggingface.co/moonshotai
Reposted by Amadeus
The paper below describes Huawei's cloud AI platform designed to efficiently serve LLMs.
It uses four major design components: serverless abstraction and infrastructure, serving engine, scheduling algorithms, and scaling optimizations.
It uses four major design components: serverless abstraction and infrastructure, serving engine, scheduling algorithms, and scaling optimizations.

February 18, 2025 at 1:43 PM
The paper below describes Huawei's cloud AI platform designed to efficiently serve LLMs.
It uses four major design components: serverless abstraction and infrastructure, serving engine, scheduling algorithms, and scaling optimizations.
It uses four major design components: serverless abstraction and infrastructure, serving engine, scheduling algorithms, and scaling optimizations.
Reposted by Amadeus

RAG is dead. Long live RAG.
LLMs suck at long context.
This paper shows what I have seen in most deployments.
With longer contexts, performance degrades.
LLMs suck at long context.
This paper shows what I have seen in most deployments.
With longer contexts, performance degrades.

February 13, 2025 at 6:11 AM
RAG is dead. Long live RAG.
LLMs suck at long context.
This paper shows what I have seen in most deployments.
With longer contexts, performance degrades.
LLMs suck at long context.
This paper shows what I have seen in most deployments.
With longer contexts, performance degrades.
Reposted by Amadeus

🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!

February 12, 2025 at 5:33 PM
🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
Reposted by Amadeus

can we scale small, open LMs to o1 level? Using classical probabilistic inference methods, YES!
Particle filtering approach to Improved inference w/o any training!
Check out probabilistic-inference-scaling.github.io
By Aisha Puri et al📈🤖
Joint MIT-CSAIL & RedHat
Particle filtering approach to Improved inference w/o any training!
Check out probabilistic-inference-scaling.github.io
By Aisha Puri et al📈🤖
Joint MIT-CSAIL & RedHat
Probabilistic Inference Scaling
Probabilistic Inference Scaling
probabilistic-inference-scaling.github.io
February 7, 2025 at 8:05 PM
can we scale small, open LMs to o1 level? Using classical probabilistic inference methods, YES!
Particle filtering approach to Improved inference w/o any training!
Check out probabilistic-inference-scaling.github.io
By Aisha Puri et al📈🤖
Joint MIT-CSAIL & RedHat
Particle filtering approach to Improved inference w/o any training!
Check out probabilistic-inference-scaling.github.io
By Aisha Puri et al📈🤖
Joint MIT-CSAIL & RedHat
Reposted by Amadeus
Post training an LLM for reasoning with GRPO in TRL by @sergiopaniego.bsky.social
A guide to post-training a LLM using GRPO. It's particularly effective for scaling test-time compute for extended reasoning, making it an ideal approach for solving complex tasks, such as mathematical problem-solving
A guide to post-training a LLM using GRPO. It's particularly effective for scaling test-time compute for extended reasoning, making it an ideal approach for solving complex tasks, such as mathematical problem-solving

February 7, 2025 at 5:15 AM
Post training an LLM for reasoning with GRPO in TRL by @sergiopaniego.bsky.social
A guide to post-training a LLM using GRPO. It's particularly effective for scaling test-time compute for extended reasoning, making it an ideal approach for solving complex tasks, such as mathematical problem-solving
A guide to post-training a LLM using GRPO. It's particularly effective for scaling test-time compute for extended reasoning, making it an ideal approach for solving complex tasks, such as mathematical problem-solving
Reposted by Amadeus

Dzisiaj spotkanie z załogą misji Ax-4 w Centrum Nauki Kopernik. Trzymamy kciuki za lot Sławosza Uznańskiego!
z @polsa.studenci @astro_peggy @astro_slawosz @tibor_to_orbit
z @polsa.studenci @astro_peggy @astro_slawosz @tibor_to_orbit


February 5, 2025 at 9:57 PM
Dzisiaj spotkanie z załogą misji Ax-4 w Centrum Nauki Kopernik. Trzymamy kciuki za lot Sławosza Uznańskiego!
z @polsa.studenci @astro_peggy @astro_slawosz @tibor_to_orbit
z @polsa.studenci @astro_peggy @astro_slawosz @tibor_to_orbit
Reposted by Amadeus

Tiny TIL: I just figured out how to run pytest with a different Python version against my pyproject.toml/setup.py projects using uv run
uv run --python 3.12 --with '.[test]' pytest
https://til.simonwillison.net/pytest/pytest-uv
uv run --python 3.12 --with '.[test]' pytest
https://til.simonwillison.net/pytest/pytest-uv

Running pytest against a specific Python version with uv run
While working on this issue I figured out a neat pattern for running the tests for my project locally against a specific Python version using uv run :
til.simonwillison.net
February 4, 2025 at 10:59 PM
Tiny TIL: I just figured out how to run pytest with a different Python version against my pyproject.toml/setup.py projects using uv run
uv run --python 3.12 --with '.[test]' pytest
https://til.simonwillison.net/pytest/pytest-uv
uv run --python 3.12 --with '.[test]' pytest
https://til.simonwillison.net/pytest/pytest-uv
Reposted by Amadeus
R1-V: teaching a VLM how to count with RL with verifiable rewards
Starting with Qwen2VL-Instruct-2B, they spent $3 on compute and got it to outperform the 72B
github.com/Deep-Agent/R...
Starting with Qwen2VL-Instruct-2B, they spent $3 on compute and got it to outperform the 72B
github.com/Deep-Agent/R...

GitHub - Deep-Agent/R1-V: Witness the aha moment of VLM with less than $3.
Witness the aha moment of VLM with less than $3. Contribute to Deep-Agent/R1-V development by creating an account on GitHub.
github.com
February 3, 2025 at 12:27 PM
R1-V: teaching a VLM how to count with RL with verifiable rewards
Starting with Qwen2VL-Instruct-2B, they spent $3 on compute and got it to outperform the 72B
github.com/Deep-Agent/R...
Starting with Qwen2VL-Instruct-2B, they spent $3 on compute and got it to outperform the 72B
github.com/Deep-Agent/R...
Reposted by Amadeus
Alibaba Qwen2.5-1M ! 💥 Now supporting a 1 MILLION TOKEN CONTEXT LENGTH 🔥
📄 Blog: qwenlm.github.io/blog/qwen2.5...
📄 Blog: qwenlm.github.io/blog/qwen2.5...

January 26, 2025 at 5:56 PM
Alibaba Qwen2.5-1M ! 💥 Now supporting a 1 MILLION TOKEN CONTEXT LENGTH 🔥
📄 Blog: qwenlm.github.io/blog/qwen2.5...
📄 Blog: qwenlm.github.io/blog/qwen2.5...
Reposted by Amadeus
Explainer: What's R1 and Everything Else
This is an attempt to consolidate the dizzying rate of AI developments since Christmas. If you're into AI but not deep enough, this should get you oriented again.
timkellogg.me/blog/2025/01...
This is an attempt to consolidate the dizzying rate of AI developments since Christmas. If you're into AI but not deep enough, this should get you oriented again.
timkellogg.me/blog/2025/01...

January 26, 2025 at 3:17 AM
Explainer: What's R1 and Everything Else
This is an attempt to consolidate the dizzying rate of AI developments since Christmas. If you're into AI but not deep enough, this should get you oriented again.
timkellogg.me/blog/2025/01...
This is an attempt to consolidate the dizzying rate of AI developments since Christmas. If you're into AI but not deep enough, this should get you oriented again.
timkellogg.me/blog/2025/01...
Reposted by Amadeus

The “Active Enum” Pattern
Enums are objects, why not give them attributes?
https://blog.glyph.im/2025/01/active-enum.html
Enums are objects, why not give them attributes?
https://blog.glyph.im/2025/01/active-enum.html
January 26, 2025 at 5:15 AM
The “Active Enum” Pattern
Enums are objects, why not give them attributes?
https://blog.glyph.im/2025/01/active-enum.html
Enums are objects, why not give them attributes?
https://blog.glyph.im/2025/01/active-enum.html
Reposted by Amadeus
Aider reports that R1+Sonnet (R1 Thinking + Sonnet) set a new SOTA on the aider polyglot benchmark at 14X less cost compared to o1.
64% R1+Sonnet
62% o1
57% R1
52% Sonnet
48% DeepSeek V3
aider.chat/2025/01/24/r...
64% R1+Sonnet
62% o1
57% R1
52% Sonnet
48% DeepSeek V3
aider.chat/2025/01/24/r...
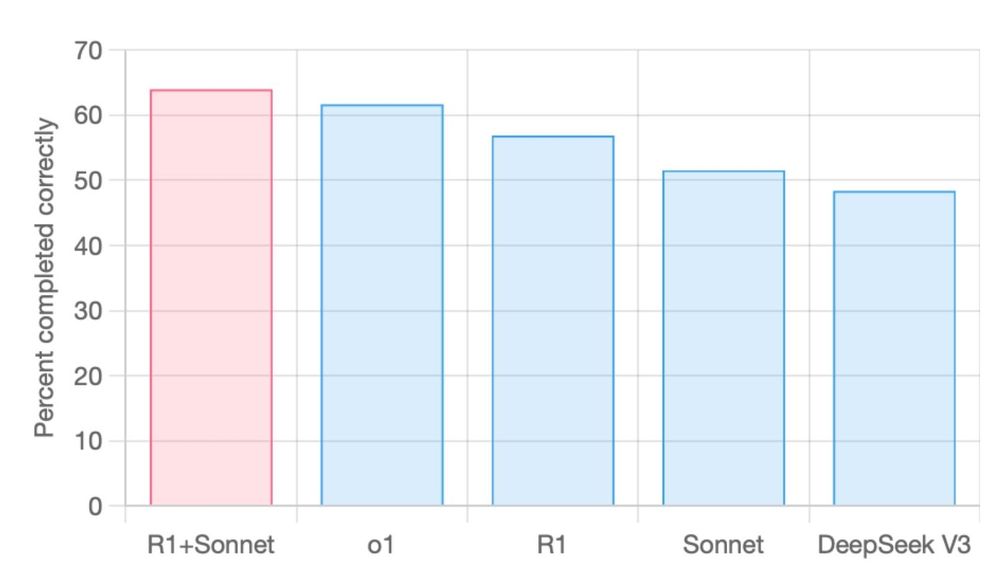
R1+Sonnet set SOTA on aider’s polyglot benchmark
R1+Sonnet has set a new SOTA on the aider polyglot benchmark. At 14X less cost compared to o1.
aider.chat
January 24, 2025 at 5:46 PM
Aider reports that R1+Sonnet (R1 Thinking + Sonnet) set a new SOTA on the aider polyglot benchmark at 14X less cost compared to o1.
64% R1+Sonnet
62% o1
57% R1
52% Sonnet
48% DeepSeek V3
aider.chat/2025/01/24/r...
64% R1+Sonnet
62% o1
57% R1
52% Sonnet
48% DeepSeek V3
aider.chat/2025/01/24/r...
Reposted by Amadeus
MiniMax-01 supports a 4M (!!!) context width
That’s 100% on needle in the haystack all the way through 4M, as i understand (seems like a benchmark mistake tbqh, it’s too good)
www.minimaxi.com/en/news/mini...
That’s 100% on needle in the haystack all the way through 4M, as i understand (seems like a benchmark mistake tbqh, it’s too good)
www.minimaxi.com/en/news/mini...

MiniMax - Intelligence with everyone
MiniMax is a leading global technology company and one of the pioneers of large language models (LLMs) in Asia. Our mission is to build a world where intelligence thrives with everyone.
www.minimaxi.com
January 15, 2025 at 3:10 AM
MiniMax-01 supports a 4M (!!!) context width
That’s 100% on needle in the haystack all the way through 4M, as i understand (seems like a benchmark mistake tbqh, it’s too good)
www.minimaxi.com/en/news/mini...
That’s 100% on needle in the haystack all the way through 4M, as i understand (seems like a benchmark mistake tbqh, it’s too good)
www.minimaxi.com/en/news/mini...
Reposted by Amadeus
InternLM v3
- Performance surpasses models like Llama3.1-8B and Qwen2.5-7B
- Capable of deep reasoning with system prompts
- Trained only on 4T high-quality tokens
huggingface.co/collections/...
- Performance surpasses models like Llama3.1-8B and Qwen2.5-7B
- Capable of deep reasoning with system prompts
- Trained only on 4T high-quality tokens
huggingface.co/collections/...

January 15, 2025 at 8:24 AM
InternLM v3
- Performance surpasses models like Llama3.1-8B and Qwen2.5-7B
- Capable of deep reasoning with system prompts
- Trained only on 4T high-quality tokens
huggingface.co/collections/...
- Performance surpasses models like Llama3.1-8B and Qwen2.5-7B
- Capable of deep reasoning with system prompts
- Trained only on 4T high-quality tokens
huggingface.co/collections/...
Reposted by Amadeus

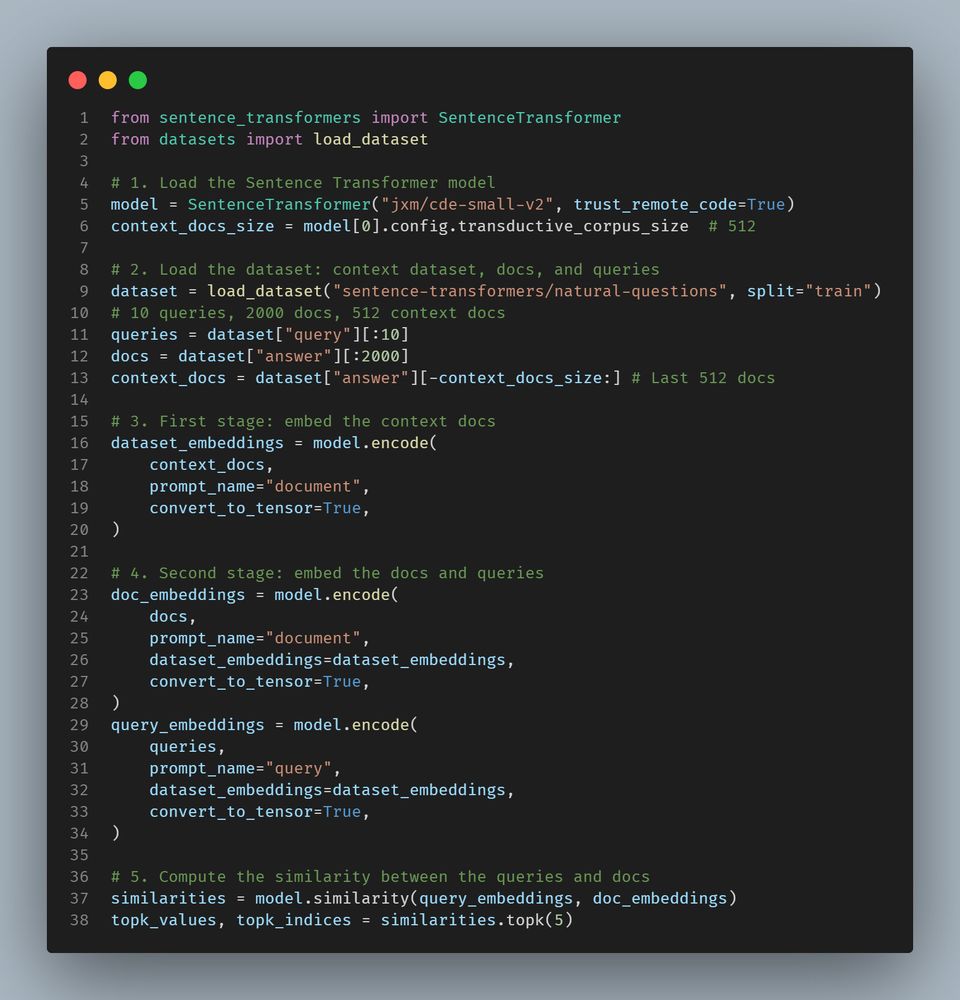
The newest extremely strong embedding model based on ModernBERT-base is out: `cde-small-v2`. Both faster and stronger than its predecessor, this one tops the MTEB leaderboard for its tiny size!
Details in 🧵
Details in 🧵
January 14, 2025 at 1:21 PM
The newest extremely strong embedding model based on ModernBERT-base is out: `cde-small-v2`. Both faster and stronger than its predecessor, this one tops the MTEB leaderboard for its tiny size!
Details in 🧵
Details in 🧵
Reposted by Amadeus

"Sky-T1-32B-Preview, our reasoning model that performs on par with o1-preview on popular reasoning and coding benchmarks."
That was quick! Is this already the Alpaca moment for reasoning models?
Source: novasky-ai.github.io/posts/sky-t1/
That was quick! Is this already the Alpaca moment for reasoning models?
Source: novasky-ai.github.io/posts/sky-t1/

January 14, 2025 at 12:34 AM
"Sky-T1-32B-Preview, our reasoning model that performs on par with o1-preview on popular reasoning and coding benchmarks."
That was quick! Is this already the Alpaca moment for reasoning models?
Source: novasky-ai.github.io/posts/sky-t1/
That was quick! Is this already the Alpaca moment for reasoning models?
Source: novasky-ai.github.io/posts/sky-t1/
Reposted by Amadeus
Google's Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time as presented by one of the author - @alibehrouz.bsky.social

January 13, 2025 at 7:53 PM
Google's Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time as presented by one of the author - @alibehrouz.bsky.social
Reposted by Amadeus

What a week to open the year in open ML, all the things released at @hf.co 🤠
Here's everything released, find text-readable version here huggingface.co/posts/merve/...
All models are here huggingface.co/collections/...
Here's everything released, find text-readable version here huggingface.co/posts/merve/...
All models are here huggingface.co/collections/...

January 10, 2025 at 2:51 PM
What a week to open the year in open ML, all the things released at @hf.co 🤠
Here's everything released, find text-readable version here huggingface.co/posts/merve/...
All models are here huggingface.co/collections/...
Here's everything released, find text-readable version here huggingface.co/posts/merve/...
All models are here huggingface.co/collections/...
Reposted by Amadeus
Contemplative LLMs: Anxiety is all you need? by Maharshi
Let the LLM 'contemplate' for a bit before answering using this simple system prompt, which might (in most cases) lead to the correct final answer!
maharshi.bearblog.dev/contemplativ...
Let the LLM 'contemplate' for a bit before answering using this simple system prompt, which might (in most cases) lead to the correct final answer!
maharshi.bearblog.dev/contemplativ...

Contemplative LLMs: Anxiety is all you need?
Let the LLM 'contemplate' before answering
maharshi.bearblog.dev
January 10, 2025 at 3:44 AM
Contemplative LLMs: Anxiety is all you need? by Maharshi
Let the LLM 'contemplate' for a bit before answering using this simple system prompt, which might (in most cases) lead to the correct final answer!
maharshi.bearblog.dev/contemplativ...
Let the LLM 'contemplate' for a bit before answering using this simple system prompt, which might (in most cases) lead to the correct final answer!
maharshi.bearblog.dev/contemplativ...