


Weijie Su
@wjsu.bsky.social
Associate Professor at University of Pennsylvania
We're excited to announce the call for papers for #ICML 2026:
icml.cc/Conferences/...
See you in Seoul next summer!
icml.cc/Conferences/...
See you in Seoul next summer!
November 7, 2025 at 3:05 PM
We're excited to announce the call for papers for #ICML 2026:
icml.cc/Conferences/...
See you in Seoul next summer!
icml.cc/Conferences/...
See you in Seoul next summer!
Great minds think alike!
Alan Turing cracked Enigma in WWII; Brad Efron asked how many words Shakespeare knew. They used the same method.
We use this method for LLM evaluation—to evaluate certain unseen capabilities of LLMs:
arxiv.org/abs/2506.02058
Alan Turing cracked Enigma in WWII; Brad Efron asked how many words Shakespeare knew. They used the same method.
We use this method for LLM evaluation—to evaluate certain unseen capabilities of LLMs:
arxiv.org/abs/2506.02058

Evaluating the Unseen Capabilities: How Many Theorems Do LLMs Know?
Accurate evaluation of large language models (LLMs) is crucial for understanding their capabilities and guiding their development. However, current evaluations often inconsistently reflect the actual ...
arxiv.org
June 4, 2025 at 3:47 PM
Great minds think alike!
Alan Turing cracked Enigma in WWII; Brad Efron asked how many words Shakespeare knew. They used the same method.
We use this method for LLM evaluation—to evaluate certain unseen capabilities of LLMs:
arxiv.org/abs/2506.02058
Alan Turing cracked Enigma in WWII; Brad Efron asked how many words Shakespeare knew. They used the same method.
We use this method for LLM evaluation—to evaluate certain unseen capabilities of LLMs:
arxiv.org/abs/2506.02058
A (not so) new paper on #LLM alignment from a social choice theory viewpoint:
arxiv.org/abs/2503.10990
It reveals fundamental impossibility results concerning representing (diverse) human preferences.
arxiv.org/abs/2503.10990
It reveals fundamental impossibility results concerning representing (diverse) human preferences.
Statistical Impossibility and Possibility of Aligning LLMs with Human Preferences: From Condorcet Paradox to Nash Equilibrium
Aligning large language models (LLMs) with diverse human preferences is critical for ensuring fairness and informed outcomes when deploying these models for decision-making. In this paper, we seek to ...
arxiv.org
May 30, 2025 at 3:59 PM
A (not so) new paper on #LLM alignment from a social choice theory viewpoint:
arxiv.org/abs/2503.10990
It reveals fundamental impossibility results concerning representing (diverse) human preferences.
arxiv.org/abs/2503.10990
It reveals fundamental impossibility results concerning representing (diverse) human preferences.
We posted a paper on optimization for deep learning:
arxiv.org/abs/2505.21799
Recently there's a surge of interest in *structure-aware* optimizers: Muon, Shampoo, Soap. In this paper, we propose a unifying preconditioning perspective, offer insights into these matrix-gradient methods.
arxiv.org/abs/2505.21799
Recently there's a surge of interest in *structure-aware* optimizers: Muon, Shampoo, Soap. In this paper, we propose a unifying preconditioning perspective, offer insights into these matrix-gradient methods.
PolarGrad: A Class of Matrix-Gradient Optimizers from a Unifying Preconditioning Perspective
The ever-growing scale of deep learning models and datasets underscores the critical importance of efficient optimization methods. While preconditioned gradient methods such as Adam and AdamW are the ...
arxiv.org
May 29, 2025 at 5:12 PM
We posted a paper on optimization for deep learning:
arxiv.org/abs/2505.21799
Recently there's a surge of interest in *structure-aware* optimizers: Muon, Shampoo, Soap. In this paper, we propose a unifying preconditioning perspective, offer insights into these matrix-gradient methods.
arxiv.org/abs/2505.21799
Recently there's a surge of interest in *structure-aware* optimizers: Muon, Shampoo, Soap. In this paper, we propose a unifying preconditioning perspective, offer insights into these matrix-gradient methods.
I just wrote a position paper on the relation between statistics and large language models:
Do Large Language Models (Really) Need Statistical Foundations?
arxiv.org/abs/2505.19145
Any comments are welcome. Thx!
Do Large Language Models (Really) Need Statistical Foundations?
arxiv.org/abs/2505.19145
Any comments are welcome. Thx!
Do Large Language Models (Really) Need Statistical Foundations?
Large language models (LLMs) represent a new paradigm for processing unstructured data, with applications across an unprecedented range of domains. In this paper, we address, through two arguments, wh...
arxiv.org
May 29, 2025 at 1:16 PM
I just wrote a position paper on the relation between statistics and large language models:
Do Large Language Models (Really) Need Statistical Foundations?
arxiv.org/abs/2505.19145
Any comments are welcome. Thx!
Do Large Language Models (Really) Need Statistical Foundations?
arxiv.org/abs/2505.19145
Any comments are welcome. Thx!
Our paper "The ICML 2023 Ranking Experiment: Examining Author Self-Assessment in ML/AI Peer Review" will appear in JASA as a Discussion Paper:
arxiv.org/abs/2408.13430
It's a privilege to work with such a wonderful team: Buxin, Jiayao, Natalie, Yuling, Didong, Kyunghyun, Jianqing, and Aaroth.
arxiv.org/abs/2408.13430
It's a privilege to work with such a wonderful team: Buxin, Jiayao, Natalie, Yuling, Didong, Kyunghyun, Jianqing, and Aaroth.
The ICML 2023 Ranking Experiment: Examining Author Self-Assessment in ML/AI Peer Review
We conducted an experiment during the review process of the 2023 International Conference on Machine Learning (ICML), asking authors with multiple submissions to rank their papers based on perceived q...
arxiv.org
May 27, 2025 at 5:01 PM
Our paper "The ICML 2023 Ranking Experiment: Examining Author Self-Assessment in ML/AI Peer Review" will appear in JASA as a Discussion Paper:
arxiv.org/abs/2408.13430
It's a privilege to work with such a wonderful team: Buxin, Jiayao, Natalie, Yuling, Didong, Kyunghyun, Jianqing, and Aaroth.
arxiv.org/abs/2408.13430
It's a privilege to work with such a wonderful team: Buxin, Jiayao, Natalie, Yuling, Didong, Kyunghyun, Jianqing, and Aaroth.
We're hiring a postdoc focused on the statistical foundations of large language models, starting this fall. Join our team exploring the theoretical and statistical underpinnings of LLMs. If interested, check our work: weijie-su.com/llm/ and drop me an email. #AIResearch #PostdocPosition
Statistical Foundations of Large Language Models
weijie-su.com
May 13, 2025 at 12:51 AM
We're hiring a postdoc focused on the statistical foundations of large language models, starting this fall. Join our team exploring the theoretical and statistical underpinnings of LLMs. If interested, check our work: weijie-su.com/llm/ and drop me an email. #AIResearch #PostdocPosition
Reposted by Weijie Su

I wrote a post on how to connect with people (i.e., make friends) at CS conferences. These events can be intimidating so here's some suggestions on how to navigate them
I'm late for #ICLR2025 #NAACL2025, but in time for #AISTATS2025 #ICML2025! 1/3
kamathematics.wordpress.com/2025/05/01/t...
I'm late for #ICLR2025 #NAACL2025, but in time for #AISTATS2025 #ICML2025! 1/3
kamathematics.wordpress.com/2025/05/01/t...

Tips on How to Connect at Academic Conferences
I was a kinda awkward teenager. If you are a CS researcher reading this post, then chances are, you were too. How to navigate social situations and make friends is not always intuitive, and has to …
kamathematics.wordpress.com
May 1, 2025 at 12:57 PM
I wrote a post on how to connect with people (i.e., make friends) at CS conferences. These events can be intimidating so here's some suggestions on how to navigate them
I'm late for #ICLR2025 #NAACL2025, but in time for #AISTATS2025 #ICML2025! 1/3
kamathematics.wordpress.com/2025/05/01/t...
I'm late for #ICLR2025 #NAACL2025, but in time for #AISTATS2025 #ICML2025! 1/3
kamathematics.wordpress.com/2025/05/01/t...
The #ICML2025 @icmlconf.bsky.social deadline has just passed!
Peer review is vital to advancing AI research. We've been conducting a survey experiment at ICML since 2023. Pls take a few minutes to participate in it, sent via email with the subject "[ICML 2025] Author Survey". Thx!
Peer review is vital to advancing AI research. We've been conducting a survey experiment at ICML since 2023. Pls take a few minutes to participate in it, sent via email with the subject "[ICML 2025] Author Survey". Thx!
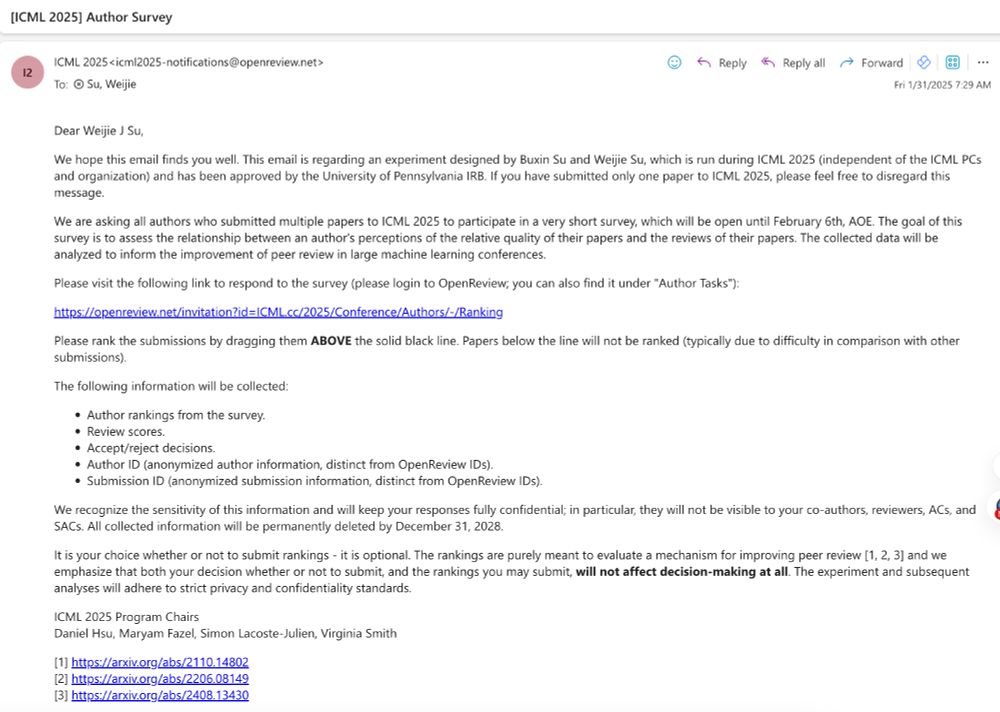
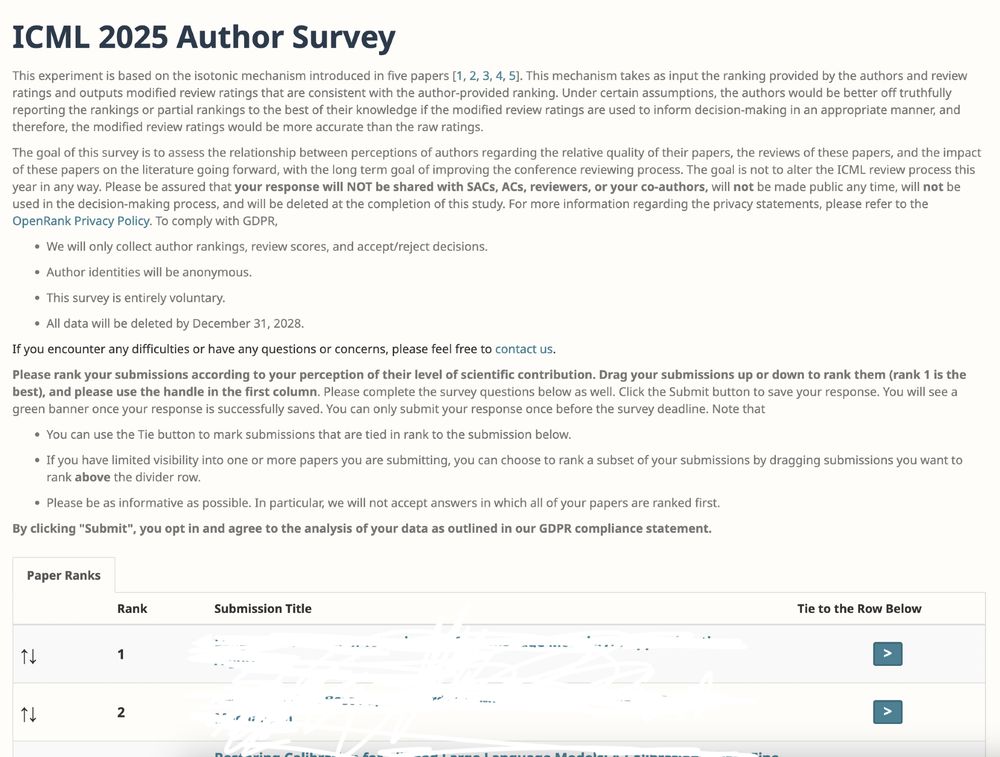
January 31, 2025 at 4:04 PM
The #ICML2025 @icmlconf.bsky.social deadline has just passed!
Peer review is vital to advancing AI research. We've been conducting a survey experiment at ICML since 2023. Pls take a few minutes to participate in it, sent via email with the subject "[ICML 2025] Author Survey". Thx!
Peer review is vital to advancing AI research. We've been conducting a survey experiment at ICML since 2023. Pls take a few minutes to participate in it, sent via email with the subject "[ICML 2025] Author Survey". Thx!
A special issue on large language models (LLMs) and statistics at Stat (onlinelibrary.wiley.com/journal/2049...). We're seeking submissions examining LLMs' impact on statistical methods, practice, education, and many more @amstatnews.bsky.social

Stat
Click on the title to browse this journal
onlinelibrary.wiley.com
December 19, 2024 at 10:25 AM
A special issue on large language models (LLMs) and statistics at Stat (onlinelibrary.wiley.com/journal/2049...). We're seeking submissions examining LLMs' impact on statistical methods, practice, education, and many more @amstatnews.bsky.social
A departmental postdoc position opening in my dept: statistics.wharton.upenn.edu/recruiting/d...

Departmental Postdoctoral Researcher Position
statistics.wharton.upenn.edu
December 11, 2024 at 8:04 PM
A departmental postdoc position opening in my dept: statistics.wharton.upenn.edu/recruiting/d...
Heading to Vancouver tomorrow for #NeurIPS2024, Dec 10-14! Excited to reconnect with colleagues and enjoy Vancouver's seafood! 🦐
December 9, 2024 at 7:46 PM
Heading to Vancouver tomorrow for #NeurIPS2024, Dec 10-14! Excited to reconnect with colleagues and enjoy Vancouver's seafood! 🦐
Reposted by Weijie Su
Machine learning has led to predictive algorithms so obscure that they resist analysis. Where does the field of traditional statistics fit into all of this? Emmanuel Candès asks the question, “Can I trust this?” Tune in to this week’s episode of “The Joy of Why” listen.quantamagazine.org/jow-321-s

How Is AI Changing the Science of Prediction?
Podcast Episode · The Joy of Why · 11/07/2024 · 37m
listen.quantamagazine.org
November 7, 2024 at 4:49 PM
Machine learning has led to predictive algorithms so obscure that they resist analysis. Where does the field of traditional statistics fit into all of this? Emmanuel Candès asks the question, “Can I trust this?” Tune in to this week’s episode of “The Joy of Why” listen.quantamagazine.org/jow-321-s
Knew nothing about bluesky until today. Immediately stop using X or gradually migrate to bluesky? Is there an optimal switching strategy?
November 28, 2024 at 1:22 AM
Knew nothing about bluesky until today. Immediately stop using X or gradually migrate to bluesky? Is there an optimal switching strategy?