




Swair
@swair.bsky.social
ML at Amazon. Interested in Math, Computers and Paintings. 🦋
Reposted by Swair

Thrilled to release Gaperon, an open LLM suite for French, English and Coding 🧀
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social

November 7, 2025 at 9:11 PM
Thrilled to release Gaperon, an open LLM suite for French, English and Coding 🧀
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
Reposted by Swair

New YouTube video uploaded on connections between Riemann zeta and Brownian motion!
What does Riemann Zeta have to do with Brownian Motion?
youtu.be/YTQKbgxbtiw
What does Riemann Zeta have to do with Brownian Motion?
youtu.be/YTQKbgxbtiw

What does Riemann Zeta have to do with Brownian Motion?
YouTube video by Almost Sure
youtu.be
November 9, 2025 at 8:19 PM
New YouTube video uploaded on connections between Riemann zeta and Brownian motion!
What does Riemann Zeta have to do with Brownian Motion?
youtu.be/YTQKbgxbtiw
What does Riemann Zeta have to do with Brownian Motion?
youtu.be/YTQKbgxbtiw
Reposted by Swair

Moonshot AI's Kosong, the LLM abstraction layer powering Kimi CLI.
It unifies message structures, asynchronous tool orchestration, and pluggable chat providers so you can build agents with ease and avoid vendor lock-in.
GitHub: github.com/MoonshotAI/k...
Docs: moonshotai.github.io/kosong/
It unifies message structures, asynchronous tool orchestration, and pluggable chat providers so you can build agents with ease and avoid vendor lock-in.
GitHub: github.com/MoonshotAI/k...
Docs: moonshotai.github.io/kosong/

November 10, 2025 at 1:13 AM
Moonshot AI's Kosong, the LLM abstraction layer powering Kimi CLI.
It unifies message structures, asynchronous tool orchestration, and pluggable chat providers so you can build agents with ease and avoid vendor lock-in.
GitHub: github.com/MoonshotAI/k...
Docs: moonshotai.github.io/kosong/
It unifies message structures, asynchronous tool orchestration, and pluggable chat providers so you can build agents with ease and avoid vendor lock-in.
GitHub: github.com/MoonshotAI/k...
Docs: moonshotai.github.io/kosong/
Reposted by Swair

Some interesting stuff here on measuring writing quality and improving on qualitative tasks:
www.dbreunig.com/2025/07/31/h...
www.dbreunig.com/2025/07/31/h...
November 10, 2025 at 3:11 AM
Some interesting stuff here on measuring writing quality and improving on qualitative tasks:
www.dbreunig.com/2025/07/31/h...
www.dbreunig.com/2025/07/31/h...
Reposted by Swair

Not enough technical AI researchers are criticizing the string of system failures around Grok. I ended this post with my very transparent thoughts on the complete failure of Grok’s recent behavior ($). www.interconnects.ai/p/grok-4-an-...

xAI's Grok 4: The tension of frontier performance with a side of Elon favoritism
An o3 class model, the possibility of progress, chatbot beige, and the illusiveness of taste.
www.interconnects.ai
July 12, 2025 at 4:13 PM
Not enough technical AI researchers are criticizing the string of system failures around Grok. I ended this post with my very transparent thoughts on the complete failure of Grok’s recent behavior ($). www.interconnects.ai/p/grok-4-an-...
Reposted by Swair

Off to ICML next week?
Check out my student Annabelle’s paper in collaboration with @lestermackey.bsky.social and colleagues on low-rank thinning!
New theory, dataset compression, efficient attention and more:
arxiv.org/abs/2502.12063
Check out my student Annabelle’s paper in collaboration with @lestermackey.bsky.social and colleagues on low-rank thinning!
New theory, dataset compression, efficient attention and more:
arxiv.org/abs/2502.12063

Low-Rank Thinning
The goal in thinning is to summarize a dataset using a small set of representative points. Remarkably, sub-Gaussian thinning algorithms like Kernel Halving and Compress can match the quality of unifor...
arxiv.org
July 12, 2025 at 4:27 PM
Off to ICML next week?
Check out my student Annabelle’s paper in collaboration with @lestermackey.bsky.social and colleagues on low-rank thinning!
New theory, dataset compression, efficient attention and more:
arxiv.org/abs/2502.12063
Check out my student Annabelle’s paper in collaboration with @lestermackey.bsky.social and colleagues on low-rank thinning!
New theory, dataset compression, efficient attention and more:
arxiv.org/abs/2502.12063
Reposted by Swair


Reposted by Swair

⚛️📝 New on Overreacted: React for Two Computers
React for Two Computers — overreacted
Two things, one origin.
overreacted.io
April 9, 2025 at 8:46 AM
⚛️📝 New on Overreacted: React for Two Computers
Reposted by Swair

Have you ever thought about interacting with Blender and controlling it directly through Claude, enabling prompt - based 3D modeling, scene creation, and manipulation?
BlenderMCP is a tool that connects Blender with Claude AI via the Model Context Protocol (MCP).
BlenderMCP is a tool that connects Blender with Claude AI via the Model Context Protocol (MCP).
March 13, 2025 at 5:31 AM
Have you ever thought about interacting with Blender and controlling it directly through Claude, enabling prompt - based 3D modeling, scene creation, and manipulation?
BlenderMCP is a tool that connects Blender with Claude AI via the Model Context Protocol (MCP).
BlenderMCP is a tool that connects Blender with Claude AI via the Model Context Protocol (MCP).
Reposted by Swair

The Excavation of Hob's Barrow is 40% off in The Storyteller's Festival on Steam! ⛏️💀
It's an honour to be part of such a great event with our folk horror adventure game set on the misty moors of Victorian England.
store.steampowered.com/app/1182310/...
It's an honour to be part of such a great event with our folk horror adventure game set on the misty moors of Victorian England.
store.steampowered.com/app/1182310/...




February 18, 2025 at 4:48 PM
The Excavation of Hob's Barrow is 40% off in The Storyteller's Festival on Steam! ⛏️💀
It's an honour to be part of such a great event with our folk horror adventure game set on the misty moors of Victorian England.
store.steampowered.com/app/1182310/...
It's an honour to be part of such a great event with our folk horror adventure game set on the misty moors of Victorian England.
store.steampowered.com/app/1182310/...
Reposted by Swair

It’s a very Byron Birdsall sort of light and shadow day out in the forest!



February 8, 2025 at 9:22 PM
It’s a very Byron Birdsall sort of light and shadow day out in the forest!
Reposted by Swair

I'll get straight to the point.
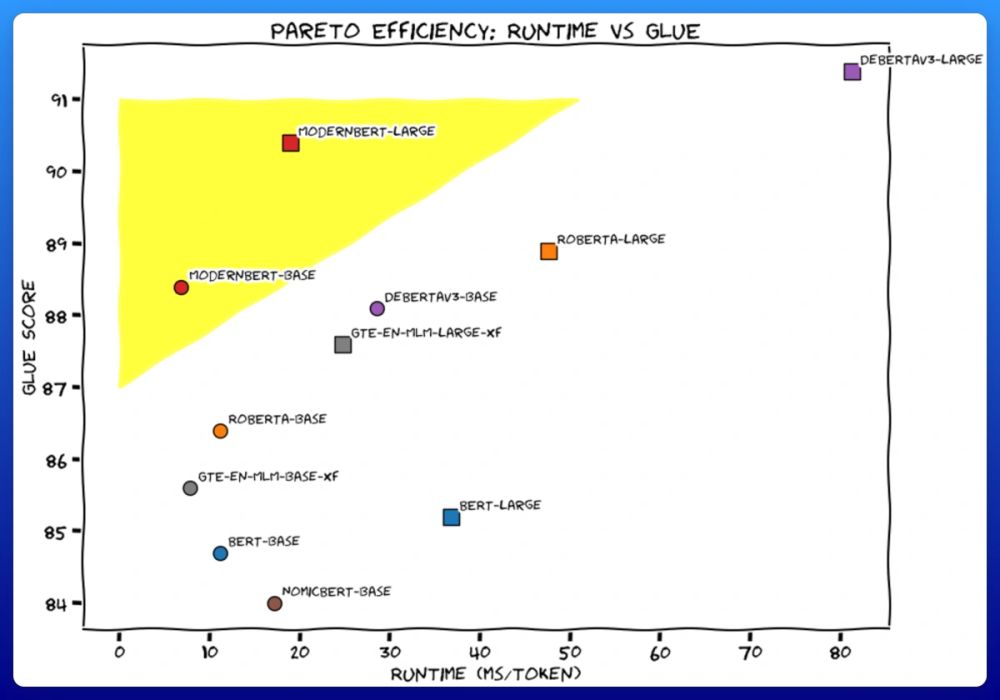
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
Reposted by Swair

What counts as in-context learning (ICL)? Typically, you might think of it as learning a task from a few examples. However, we’ve just written a perspective (arxiv.org/abs/2412.03782) suggesting interpreting a much broader spectrum of behaviors as ICL! Quick summary thread: 1/7

The broader spectrum of in-context learning
The ability of language models to learn a task from a few examples in context has generated substantial interest. Here, we provide a perspective that situates this type of supervised few-shot learning...
arxiv.org
December 10, 2024 at 6:17 PM
What counts as in-context learning (ICL)? Typically, you might think of it as learning a task from a few examples. However, we’ve just written a perspective (arxiv.org/abs/2412.03782) suggesting interpreting a much broader spectrum of behaviors as ICL! Quick summary thread: 1/7
Reposted by Swair

How are Kernel Smoothing in statistics, Data-Adaptive Filters in image processing, and Attention in Machine Learning related?
My goal is not to argue who should get credit for what, but to show a progression of closely related ideas over time and across neighboring fields.
1/n
My goal is not to argue who should get credit for what, but to show a progression of closely related ideas over time and across neighboring fields.
1/n

December 8, 2024 at 9:45 PM
How are Kernel Smoothing in statistics, Data-Adaptive Filters in image processing, and Attention in Machine Learning related?
My goal is not to argue who should get credit for what, but to show a progression of closely related ideas over time and across neighboring fields.
1/n
My goal is not to argue who should get credit for what, but to show a progression of closely related ideas over time and across neighboring fields.
1/n
Reposted by Swair

And if you want the non-paywalled version: arxiv.org/abs/2407.14315
December 5, 2024 at 7:49 PM
And if you want the non-paywalled version: arxiv.org/abs/2407.14315
Reposted by Swair

🧵 Today with @polymathicai.bsky.social and others we're releasing two massive datasets that span dozens of fields - from bacterial growth to supernova!
We want this to enable multi-disciplinary foundation model research.
We want this to enable multi-disciplinary foundation model research.
December 2, 2024 at 7:46 PM
🧵 Today with @polymathicai.bsky.social and others we're releasing two massive datasets that span dozens of fields - from bacterial growth to supernova!
We want this to enable multi-disciplinary foundation model research.
We want this to enable multi-disciplinary foundation model research.
Reposted by Swair

Generating 3D worlds by generating 3D geometry instead of pixels www.worldlabs.ai/blog
About a month ago I told some students that one could do geometry instead of pixels and solve persistence/hallucination issues. But they only had a week runway because someone else was probably working on it too
About a month ago I told some students that one could do geometry instead of pixels and solve persistence/hallucination issues. But they only had a week runway because someone else was probably working on it too

Generating Worlds
Today we're sharing our first step towards spatial intelligence: an AI system that generates 3D worlds from a single image.
www.worldlabs.ai
December 2, 2024 at 6:49 PM
Generating 3D worlds by generating 3D geometry instead of pixels www.worldlabs.ai/blog
About a month ago I told some students that one could do geometry instead of pixels and solve persistence/hallucination issues. But they only had a week runway because someone else was probably working on it too
About a month ago I told some students that one could do geometry instead of pixels and solve persistence/hallucination issues. But they only had a week runway because someone else was probably working on it too
Reposted by Swair

I defended my PhD dissertation back in May. I didn't have time to share it widely then (newborn baby), but I think some of you might enjoy it, especially the opening chapters: benjaminedelman.com/assets/disse...

December 2, 2024 at 12:21 AM
I defended my PhD dissertation back in May. I didn't have time to share it widely then (newborn baby), but I think some of you might enjoy it, especially the opening chapters: benjaminedelman.com/assets/disse...
Reposted by Swair

How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
November 20, 2024 at 4:35 PM
How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Reposted by Swair

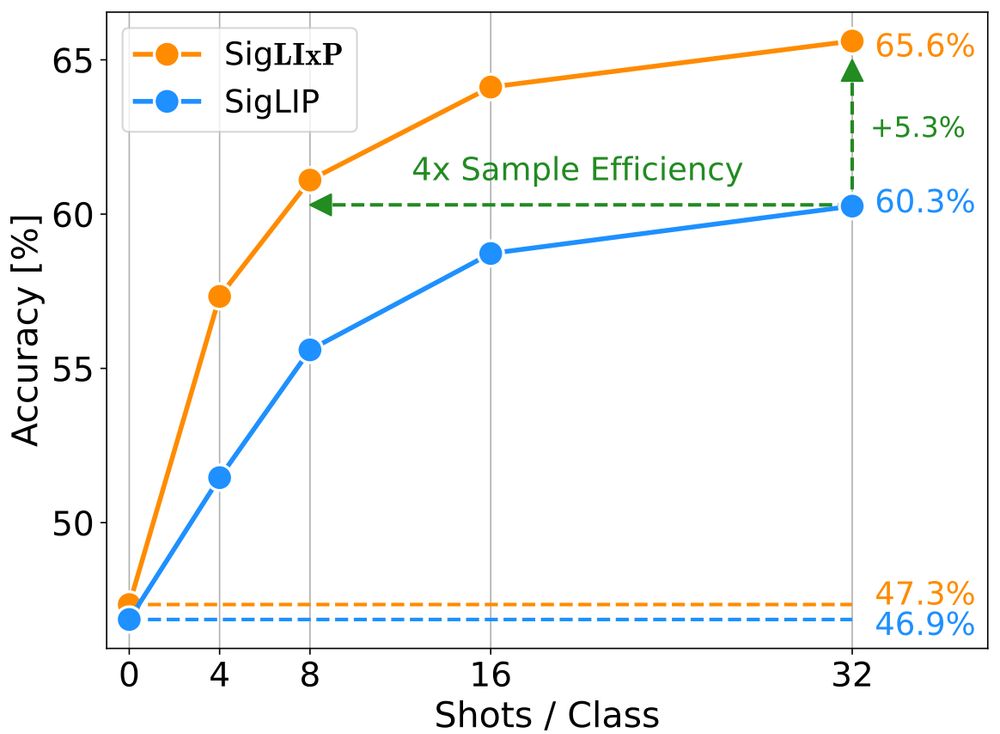
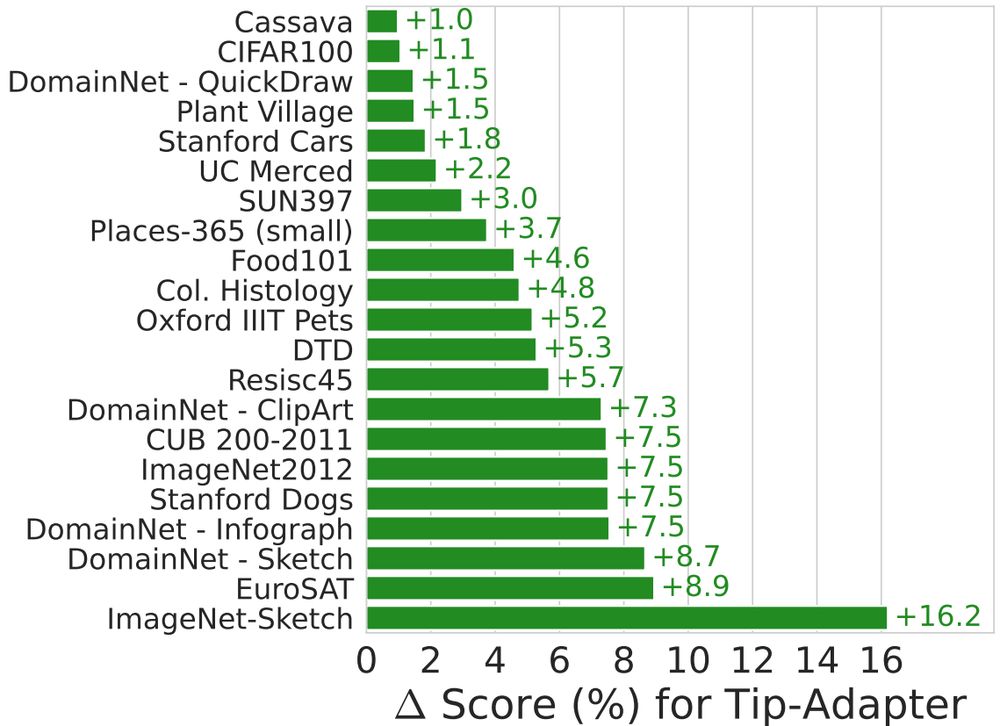
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:

November 28, 2024 at 2:33 PM
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Reposted by Swair

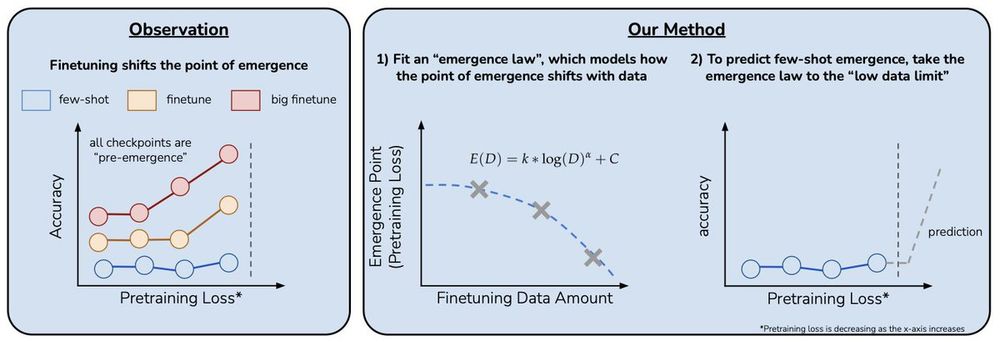
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
November 26, 2024 at 10:37 PM
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
Reposted by Swair

Amazing blog post on flow matching, stunning visuals! It also makes the connection with normalising flows crystal clear. Incredible effort!

Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
November 27, 2024 at 6:31 PM
Amazing blog post on flow matching, stunning visuals! It also makes the connection with normalising flows crystal clear. Incredible effort!
Reposted by Swair

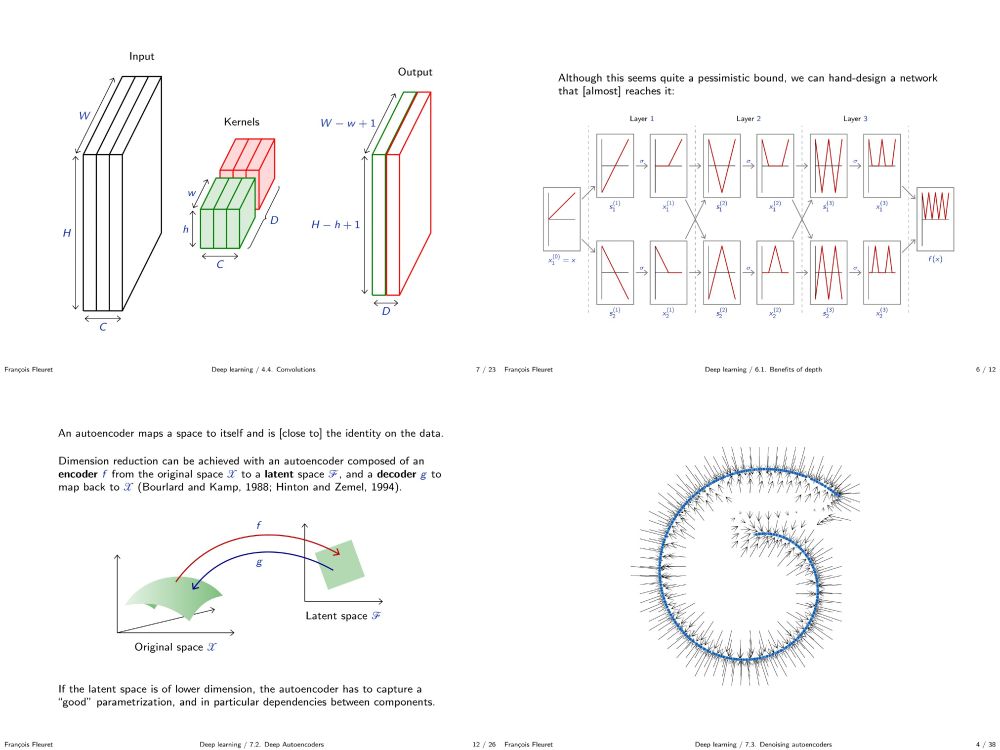
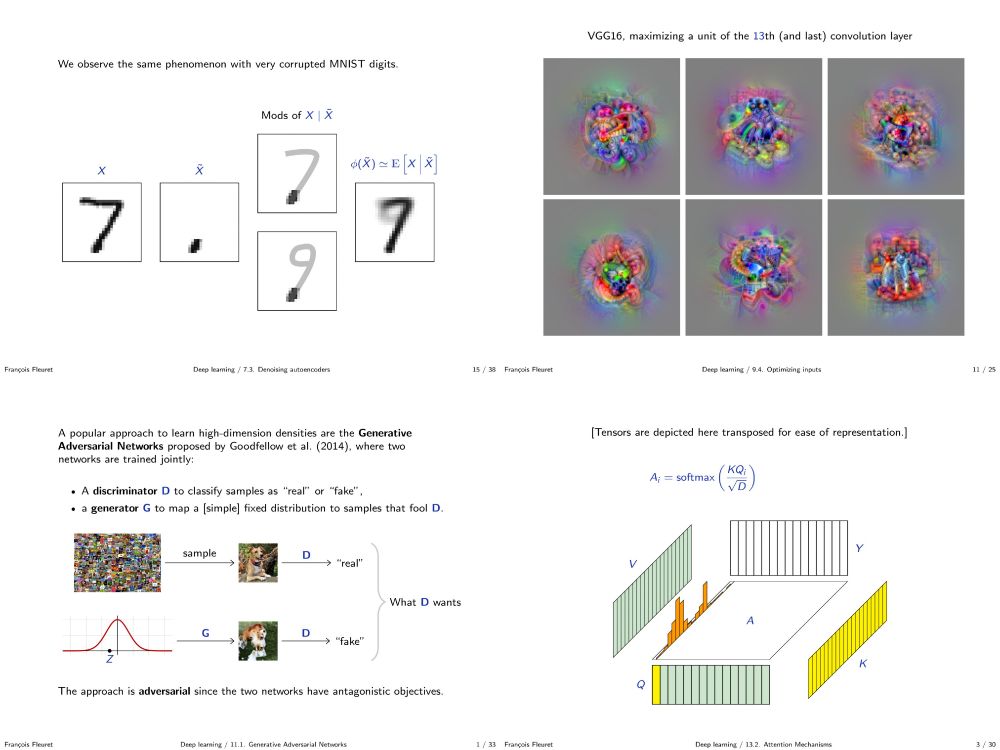
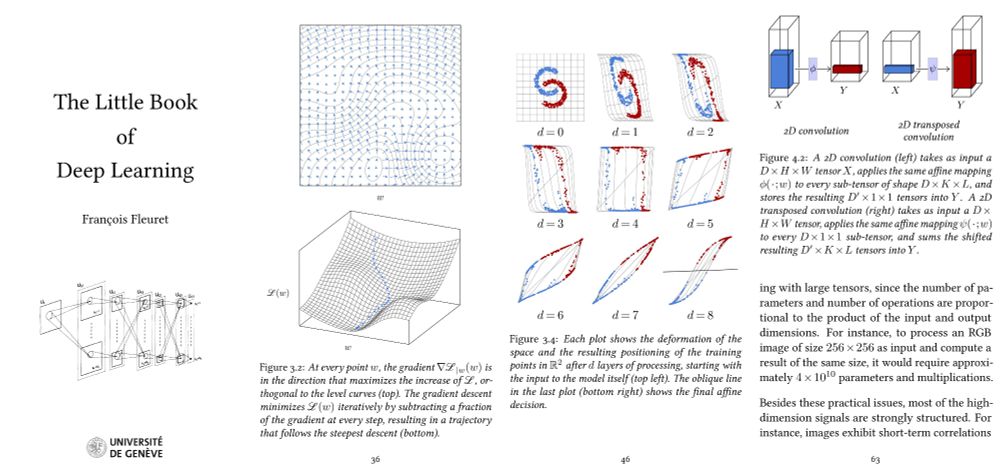
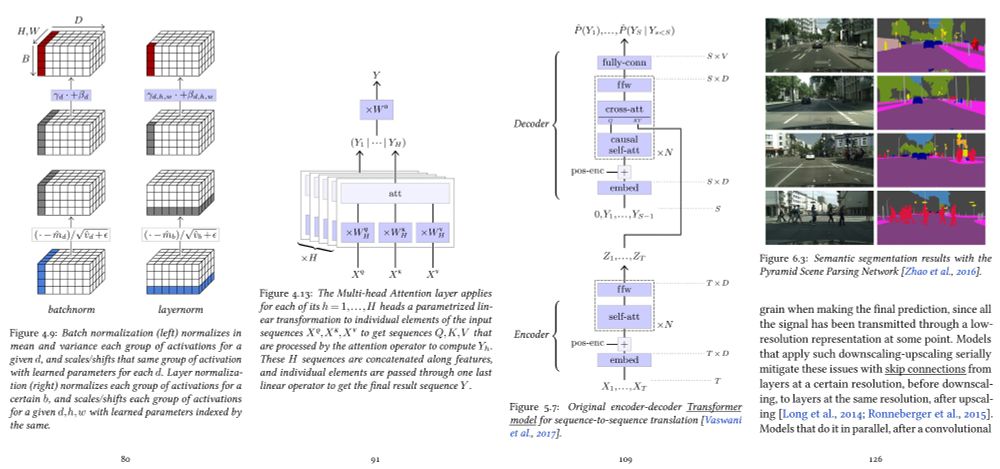
My deep learning course at the University of Geneva is available on-line. 1000+ slides, ~20h of screen-casts. Full of examples in PyTorch.
fleuret.org/dlc/
And my "Little Book of Deep Learning" is available as a phone-formatted pdf (nearing 700k downloads!)
fleuret.org/lbdl/
fleuret.org/dlc/
And my "Little Book of Deep Learning" is available as a phone-formatted pdf (nearing 700k downloads!)
fleuret.org/lbdl/
November 26, 2024 at 6:15 AM
My deep learning course at the University of Geneva is available on-line. 1000+ slides, ~20h of screen-casts. Full of examples in PyTorch.
fleuret.org/dlc/
And my "Little Book of Deep Learning" is available as a phone-formatted pdf (nearing 700k downloads!)
fleuret.org/lbdl/
fleuret.org/dlc/
And my "Little Book of Deep Learning" is available as a phone-formatted pdf (nearing 700k downloads!)
fleuret.org/lbdl/
Reposted by Swair

A paper a day, episode 13.
Consider a non-abelian group. Take two elements at random. What is the probability that they commute? 🧵
doi.org/10.1080/0002...
Consider a non-abelian group. Take two elements at random. What is the probability that they commute? 🧵
doi.org/10.1080/0002...

What is the Probability that Two Group Elements Commute?
Published in The American Mathematical Monthly (Vol. 80, No. 9, 1973)
doi.org
November 25, 2024 at 10:06 PM
A paper a day, episode 13.
Consider a non-abelian group. Take two elements at random. What is the probability that they commute? 🧵
doi.org/10.1080/0002...
Consider a non-abelian group. Take two elements at random. What is the probability that they commute? 🧵
doi.org/10.1080/0002...
Reposted by Swair

Anthropic released an interesting thing today: an attempt at a standard protocol for LLM tools to talk to services that provide tools and extra context to be used other the models modelcontextprotocol.io

Introduction - Model Context Protocol
Get started with the Model Context Protocol (MCP)
modelcontextprotocol.io
November 25, 2024 at 4:37 PM
Anthropic released an interesting thing today: an attempt at a standard protocol for LLM tools to talk to services that provide tools and extra context to be used other the models modelcontextprotocol.io