




Charlie Snell
@seasnell.bsky.social
PhD @berkeley_ai; prev SR @GoogleDeepMind. I stare at my computer a lot and make things
Pinned
Charlie Snell
@seasnell.bsky.social
· Nov 26
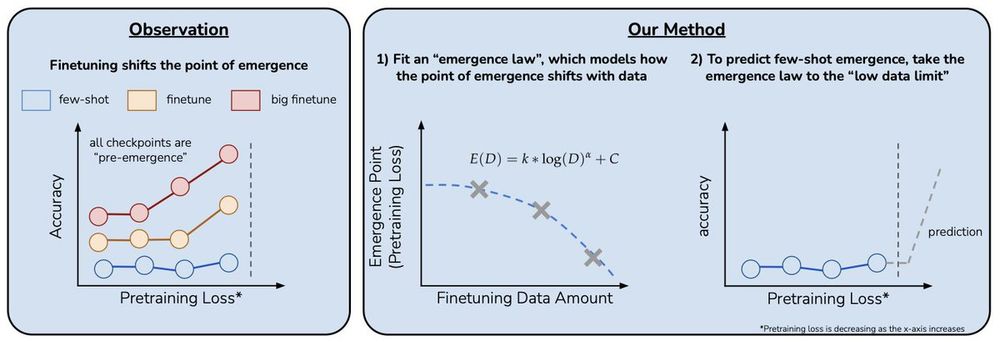
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
Reposted by Charlie Snell

Did you know that attention across the whole input span was inspired by the time-negating alien language in Arrival? Crazy anecdote from the latest Hard Fork podcast (by @kevinroose.com and @caseynewton.bsky.social). HT nwbrownboi on Threads for the lead.

December 1, 2024 at 2:50 PM
Did you know that attention across the whole input span was inspired by the time-negating alien language in Arrival? Crazy anecdote from the latest Hard Fork podcast (by @kevinroose.com and @caseynewton.bsky.social). HT nwbrownboi on Threads for the lead.
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
November 26, 2024 at 10:37 PM
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵