




jeffcarp
@jeffcarp.bsky.social
🌉 Running, biking, and drinking coffee around SF
🧑💻 ML at Goog, prev. Waymo, fintech, NPR
🐺 Social media manager for @noonathehusky
https://www.jeffcarp.com
🧑💻 ML at Goog, prev. Waymo, fintech, NPR
🐺 Social media manager for @noonathehusky
https://www.jeffcarp.com
Reposted by jeffcarp

A Waymo vehicle was driving in a 25mph zone in LA when an oncoming car swerved into its lane while speeding up to over 70mph… 3x the speed means 9x the destructive energy.
Waymo vehicle reacted safely.
Source: Dmitri Dolgov (Co-CEO at waymo)
Waymo vehicle reacted safely.
Source: Dmitri Dolgov (Co-CEO at waymo)
March 6, 2025 at 3:46 AM
A Waymo vehicle was driving in a 25mph zone in LA when an oncoming car swerved into its lane while speeding up to over 70mph… 3x the speed means 9x the destructive energy.
Waymo vehicle reacted safely.
Source: Dmitri Dolgov (Co-CEO at waymo)
Waymo vehicle reacted safely.
Source: Dmitri Dolgov (Co-CEO at waymo)
Reposted by jeffcarp
Awesome LLM Post-training
This repository is a curated collection of the most influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies.
github.com/mbzuai-oryx/...
This repository is a curated collection of the most influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies.
github.com/mbzuai-oryx/...

March 4, 2025 at 12:03 AM
Awesome LLM Post-training
This repository is a curated collection of the most influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies.
github.com/mbzuai-oryx/...
This repository is a curated collection of the most influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies.
github.com/mbzuai-oryx/...
Thanks for reposting my video. I think Waymo also solves the critical urban problem of literally not having people dying every day for no reason

Video of Waymo robots queued around the corner for pickups from Davies Symphony Hall:
Franklin St then Grove St, San Francisco
Robots aprés Rachmaninoff
Waymo solves the critical urban problems of not enough cars and too free flowing downtown traffic.
OP: @jeffcarp.bsky.social posted on threads
Franklin St then Grove St, San Francisco
Robots aprés Rachmaninoff
Waymo solves the critical urban problems of not enough cars and too free flowing downtown traffic.
OP: @jeffcarp.bsky.social posted on threads
March 3, 2025 at 11:58 PM
Thanks for reposting my video. I think Waymo also solves the critical urban problem of literally not having people dying every day for no reason
Reposted by jeffcarp
How to Scale Your Model
This book aims to demystify the science of scaling language models on TPUs: how TPUs work and how they communicate with each other, how LLMs run on real hardware, and how to parallelize your models during training and inference so they run efficiently at massive scale.
This book aims to demystify the science of scaling language models on TPUs: how TPUs work and how they communicate with each other, how LLMs run on real hardware, and how to parallelize your models during training and inference so they run efficiently at massive scale.

February 4, 2025 at 6:02 PM
How to Scale Your Model
This book aims to demystify the science of scaling language models on TPUs: how TPUs work and how they communicate with each other, how LLMs run on real hardware, and how to parallelize your models during training and inference so they run efficiently at massive scale.
This book aims to demystify the science of scaling language models on TPUs: how TPUs work and how they communicate with each other, how LLMs run on real hardware, and how to parallelize your models during training and inference so they run efficiently at massive scale.
Reposted by jeffcarp

That immigrants, from China, India, Iran, Latin America, and so many places choose to come here is a blessing and a gift. That this needs to be said and that politicians ever make them feel otherwise is an eternal disappointment.
February 1, 2025 at 8:30 PM
That immigrants, from China, India, Iran, Latin America, and so many places choose to come here is a blessing and a gift. That this needs to be said and that politicians ever make them feel otherwise is an eternal disappointment.
Reposted by jeffcarp
A vision researcher’s guide to some RL stuff: PPO & GRPO by Yuge (Jimmy) Shi
This is a deep dive into Proximal Policy Optimization (PPO), which is one of the most popular algorithm used in RLHF for LLMs, as well as Group Relative Policy Optimization (GRPO) proposed by the DeepSeek folks.
This is a deep dive into Proximal Policy Optimization (PPO), which is one of the most popular algorithm used in RLHF for LLMs, as well as Group Relative Policy Optimization (GRPO) proposed by the DeepSeek folks.
January 31, 2025 at 5:56 AM
A vision researcher’s guide to some RL stuff: PPO & GRPO by Yuge (Jimmy) Shi
This is a deep dive into Proximal Policy Optimization (PPO), which is one of the most popular algorithm used in RLHF for LLMs, as well as Group Relative Policy Optimization (GRPO) proposed by the DeepSeek folks.
This is a deep dive into Proximal Policy Optimization (PPO), which is one of the most popular algorithm used in RLHF for LLMs, as well as Group Relative Policy Optimization (GRPO) proposed by the DeepSeek folks.
Reposted by jeffcarp

The PyTorch developer's guide to JAX fundamentals cloud.google.com/blog/product...

A guide to JAX for PyTorch developers | Google Cloud Blog
PyTorch users can learn about JAX in this tutorial that connects JAX concepts to the PyTorch building blocks that they’re already familiar with.
cloud.google.com
January 10, 2025 at 4:05 AM
The PyTorch developer's guide to JAX fundamentals cloud.google.com/blog/product...
Reposted by jeffcarp

#2025 is the sum of the first 9 cubes 🤩
1+8+27+64+125+216+343+512+729 🥂 🎉 🎆 🎇 🧮
1+8+27+64+125+216+343+512+729 🥂 🎉 🎆 🎇 🧮
December 31, 2024 at 4:13 PM
#2025 is the sum of the first 9 cubes 🤩
1+8+27+64+125+216+343+512+729 🥂 🎉 🎆 🎇 🧮
1+8+27+64+125+216+343+512+729 🥂 🎉 🎆 🎇 🧮
Reposted by jeffcarp
Would be fascinated to learn how this paper came into being given the authors on it: arxiv.org/abs/2412.05747

Charting the Shapes of Stories with Game Theory
Stories are records of our experiences and their analysis reveals insights into the nature of being human. Successful analyses are often interdisciplinary, leveraging mathematical tools to extract str...
arxiv.org
December 31, 2024 at 12:21 AM
Would be fascinated to learn how this paper came into being given the authors on it: arxiv.org/abs/2412.05747
Reposted by jeffcarp

Applications open on Dec 20 for the #Research Scholar program, which aims to strengthen long-term collaboration with the academic community by supporting early-career professors pursuing research in fields relevant to #Google. Learn more & apply by Jan 27 ↓
research.google/programs-and...
research.google/programs-and...

Research scholar program
Overview
research.google
December 22, 2024 at 12:43 AM
Applications open on Dec 20 for the #Research Scholar program, which aims to strengthen long-term collaboration with the academic community by supporting early-career professors pursuing research in fields relevant to #Google. Learn more & apply by Jan 27 ↓
research.google/programs-and...
research.google/programs-and...
Reposted by jeffcarp
A good advice from Victor Dibia

December 19, 2024 at 6:20 PM
A good advice from Victor Dibia
Reposted by jeffcarp
A short list of tips for keeping a clean, organized ML codebase for new researchers: eugenevinitsky.com/posts/quick-...
Eugene Vinitsky
eugenevinitsky.com
December 18, 2024 at 8:00 PM
A short list of tips for keeping a clean, organized ML codebase for new researchers: eugenevinitsky.com/posts/quick-...
If machine learning is the high-interest credit card of technical debt, quantization is the back alley predatory loan
December 12, 2024 at 7:35 PM
If machine learning is the high-interest credit card of technical debt, quantization is the back alley predatory loan
Reposted by jeffcarp

Gemini 2.0 is out, and there's a ton of interesting stuff about it. From my testing it looks like Gemini 2.0 Flash may be the best currently available multi-modal model - I upgraded my LLM plugin to support that here: github.com/simonw/llm-g...
Gemini 2.0 announcement: blog.google/technology/g...
Gemini 2.0 announcement: blog.google/technology/g...

Release 0.7 · simonw/llm-gemini
New Gemini 2.0 Flash model: llm -m gemini-2.0-flash-exp 'prompt goes here'. #28
github.com
December 11, 2024 at 5:55 PM
Gemini 2.0 is out, and there's a ton of interesting stuff about it. From my testing it looks like Gemini 2.0 Flash may be the best currently available multi-modal model - I upgraded my LLM plugin to support that here: github.com/simonw/llm-g...
Gemini 2.0 announcement: blog.google/technology/g...
Gemini 2.0 announcement: blog.google/technology/g...
Going full circle: in 2019 Waymo made an April Fools video about a dog-only robotaxi service. Now people are actually sending their dogs in Waymo unattended.
youtu.be/ljbeFpOHvEA?...
youtu.be/ljbeFpOHvEA?...

December 9, 2024 at 3:54 PM
Going full circle: in 2019 Waymo made an April Fools video about a dog-only robotaxi service. Now people are actually sending their dogs in Waymo unattended.
youtu.be/ljbeFpOHvEA?...
youtu.be/ljbeFpOHvEA?...
Reposted by jeffcarp
Reinforcement Learning: An Overview
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based methods, and various other topics.
arxiv.org/abs/2412.05265
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based methods, and various other topics.
arxiv.org/abs/2412.05265

December 9, 2024 at 8:37 AM
Reinforcement Learning: An Overview
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based methods, and various other topics.
arxiv.org/abs/2412.05265
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based methods, and various other topics.
arxiv.org/abs/2412.05265
Reposted by jeffcarp

Happy Birthday to Gemini! ✨🎂
Around this time last year, I was working on the Gemini Launch and it was exciting to have access to such models
After one year I've learned a lot and I'm still amazed of what can be done!
best feature: 2M context window 🤯
developers.googleblog.com/en/looking-b...
Around this time last year, I was working on the Gemini Launch and it was exciting to have access to such models
After one year I've learned a lot and I'm still amazed of what can be done!
best feature: 2M context window 🤯
developers.googleblog.com/en/looking-b...

Looking back at the first year of the Gemini era
Google's Gemini family of AI models has empowered developers to build innovative applications and explore its journey over the first year.
developers.googleblog.com
December 7, 2024 at 11:56 PM
Happy Birthday to Gemini! ✨🎂
Around this time last year, I was working on the Gemini Launch and it was exciting to have access to such models
After one year I've learned a lot and I'm still amazed of what can be done!
best feature: 2M context window 🤯
developers.googleblog.com/en/looking-b...
Around this time last year, I was working on the Gemini Launch and it was exciting to have access to such models
After one year I've learned a lot and I'm still amazed of what can be done!
best feature: 2M context window 🤯
developers.googleblog.com/en/looking-b...
I’m late to the game here, but super impressed this UI is an open source React Native app, the framework has come a long way!
December 8, 2024 at 1:46 AM
I’m late to the game here, but super impressed this UI is an open source React Native app, the framework has come a long way!
Reposted by jeffcarp
Derek Sivers once said “Mastery is the best goal because the rich can’t buy it, the impatient can’t rush it, the privileged can’t inherit it, and nobody can steal it. You can only earn it through hard work. Mastery is the ultimate status.”
Does it still hold in the age of LLMs? 😎
Does it still hold in the age of LLMs? 😎
December 6, 2024 at 4:27 AM
Derek Sivers once said “Mastery is the best goal because the rich can’t buy it, the impatient can’t rush it, the privileged can’t inherit it, and nobody can steal it. You can only earn it through hard work. Mastery is the ultimate status.”
Does it still hold in the age of LLMs? 😎
Does it still hold in the age of LLMs? 😎
Reposted by jeffcarp

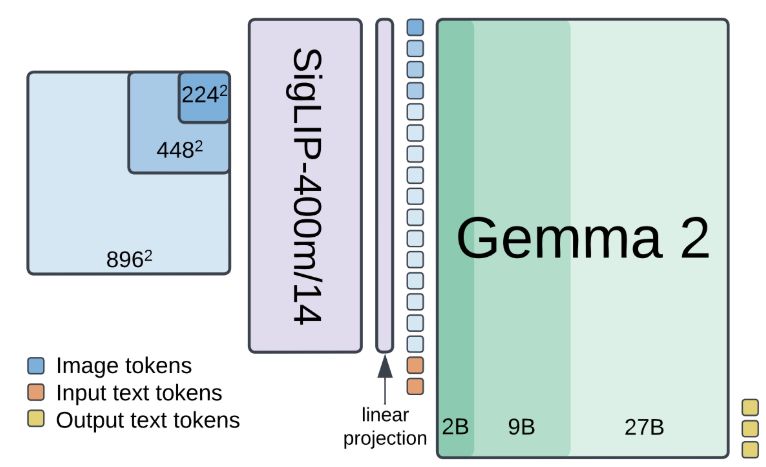
Paligemma2 is out! Bigger models, better results. For the best experience, do not forget to finetune.
Congrats Paligemma2 team!
Congrats Paligemma2 team!

🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
1/7
December 5, 2024 at 6:28 PM
Paligemma2 is out! Bigger models, better results. For the best experience, do not forget to finetune.
Congrats Paligemma2 team!
Congrats Paligemma2 team!
Hi Bluesky! Any AI/ML following recommendations?
December 4, 2024 at 9:59 PM
Hi Bluesky! Any AI/ML following recommendations?
Reposted by jeffcarp

Is this a correct description of how fields cross-pollinated each other?
- CV and speech jump-started deep learning
- NLP innovated with transformers, which were then copied by CV and others
- Robotics and CV embraced RL early on
- NLP now discovers RL, first through RLHF and now for planning.
- CV and speech jump-started deep learning
- NLP innovated with transformers, which were then copied by CV and others
- Robotics and CV embraced RL early on
- NLP now discovers RL, first through RLHF and now for planning.
December 1, 2024 at 1:08 PM
Is this a correct description of how fields cross-pollinated each other?
- CV and speech jump-started deep learning
- NLP innovated with transformers, which were then copied by CV and others
- Robotics and CV embraced RL early on
- NLP now discovers RL, first through RLHF and now for planning.
- CV and speech jump-started deep learning
- NLP innovated with transformers, which were then copied by CV and others
- Robotics and CV embraced RL early on
- NLP now discovers RL, first through RLHF and now for planning.