


Felix Wimbauer
@fwimbauer.bsky.social
74 followers
57 following
4 posts
ELLIS PhD Student in Computer Vision at TUM with Daniel Cremers and Christian Rupprecht (Oxford), fwmb.github.io, prev. Research Intern at Meta GenAI
Posts
Media
Videos
Starter Packs
Pinned
Reposted by Felix Wimbauer
Reposted by Felix Wimbauer


Reposted by Felix Wimbauer

Reposted by Felix Wimbauer

Reposted by Felix Wimbauer

Reposted by Felix Wimbauer

Sebastian
@mersault.bsky.social
· May 12
Reposted by Felix Wimbauer
Reposted by Felix Wimbauer

Oliver Hahn
@olvrhhn.bsky.social
· May 11

Behind every great conference is a team of dedicated reviewers. Congratulations to this year’s #CVPR2025 Outstanding Reviewers!
cvpr.thecvf.com/Conferences/...
cvpr.thecvf.com/Conferences/...
Felix Wimbauer
@fwimbauer.bsky.social
· May 13
Reposted by Felix Wimbauer


Reposted by Felix Wimbauer

Reposted by Felix Wimbauer

Reposted by Felix Wimbauer

Reposted by Felix Wimbauer

Felix Wimbauer
@fwimbauer.bsky.social
· Apr 23

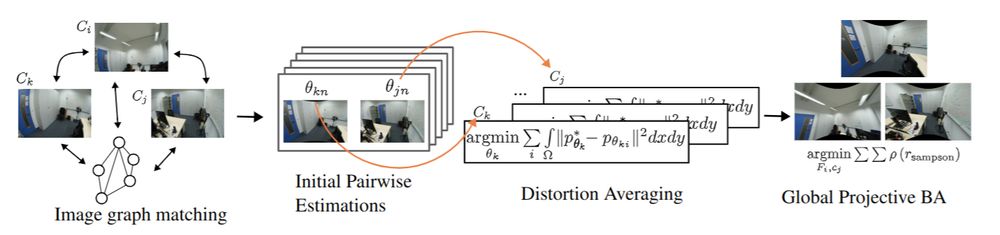
AnyCam: Learning to Recover Camera Poses and Intrinsics from Casual Videos
Estimating camera motion and intrinsics from casual videos is a core challenge in computer vision. Traditional bundle-adjustment based methods, such as SfM and SLAM, struggle to perform reliably on ar...
arxiv.org
Reposted by Felix Wimbauer





Reposted by Felix Wimbauer

Reposted by Felix Wimbauer
We are thrilled to have 12 papers accepted to #CVPR2025. Thanks to all our students and collaborators for this great achievement!
For more details check out cvg.cit.tum.de
For more details check out cvg.cit.tum.de

Reposted by Felix Wimbauer



Reposted by Felix Wimbauer
A. Sophia Koepke
@askoepke.bsky.social
· Feb 13
🔥 #CVPR2025 Submit your cool papers to Workshop on
Emergent Visual Abilities and Limits of Foundation Models 📷📷🧠🚀✨
sites.google.com/view/eval-fo...
Submission Deadline: March 12th!
Emergent Visual Abilities and Limits of Foundation Models 📷📷🧠🚀✨
sites.google.com/view/eval-fo...
Submission Deadline: March 12th!

EVAL-FoMo 2
A Vision workshop on Evaluations and Analysis
sites.google.com
Reposted by Felix Wimbauer

Reposted by Felix Wimbauer
