



Christoph Reich
@christophreich.bsky.social
120 followers
260 following
14 posts
@ellis.eu Ph.D. Student @CVG (@dcremers.bsky.social), @visinf.bsky.social & @oxford-vgg.bsky.social | Ph.D. Scholar @zuseschooleliza.bsky.social | M.Sc. & B.Sc. @tuda.bsky.social | Prev. @neclabsamerica.bsky.social
https://christophreich1996.github.io
Posts
Media
Videos
Starter Packs
Reposted by Christoph Reich
Reposted by Christoph Reich
Reposted by Christoph Reich

Visual Inference Lab
@visinf.bsky.social
· Sep 29

ELLIS PhD Program: Call for Applications 2025
The ELLIS mission is to create a diverse European network that promotes research excellence and advances breakthroughs in AI, as well as a pan-European PhD program to educate the next generation of AI...
ellis.eu
Reposted by Christoph Reich





Reposted by Christoph Reich




Reposted by Christoph Reich







Reposted by Christoph Reich

arxiv cs.CV
@arxiv-cs-cv.bsky.social
· Jul 9
Reposted by Christoph Reich


Reposted by Christoph Reich




Reposted by Christoph Reich
Reposted by Christoph Reich

Reposted by Christoph Reich

Reposted by Christoph Reich
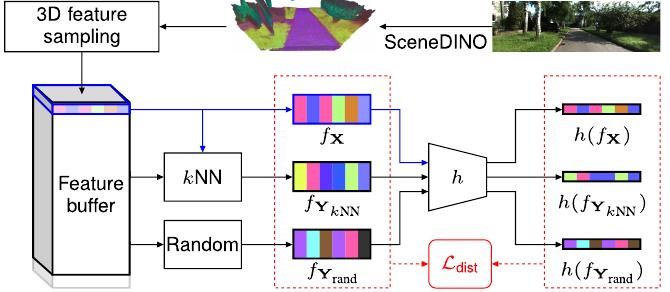
📢 #CVPR2025 Highlight: Scene-Centric Unsupervised Panoptic Segmentation 🔥
We present CUPS, the first unsupervised panoptic segmentation method trained directly on scene-centric imagery.
Using self-supervised features, depth & motion, we achieve SotA results!
🌎 visinf.github.io/cups
We present CUPS, the first unsupervised panoptic segmentation method trained directly on scene-centric imagery.
Using self-supervised features, depth & motion, we achieve SotA results!
🌎 visinf.github.io/cups

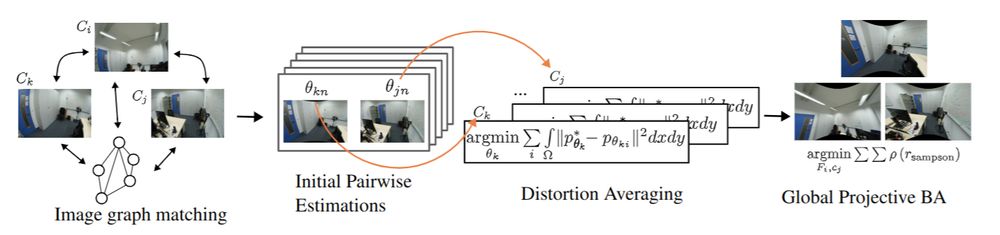
𝗠𝗖𝗠𝗟 𝗕𝗹𝗼𝗴: Robots & self-driving cars rely on scene understanding, but AI models for understanding these scenes need costly human annotations. Daniel Cremers & his team introduce 🥤🥤 CUPS: a scene-centric unsupervised panoptic segmentation approach to reduce this dependency. 🔗 mcml.ai/news/2025-04...
