



Alan
@ftenjoyer.bsky.social
ML/AI - NLP, multimodality and more. Media accesibility. Finetuning enjoyer. Investigación aplicada. También hago aplicaciones web. ES/EN
Reposted by Alan

La Junta de Andalucía ha lanzado un chatbot con RAG, precargado con documentación de la administración, para uso interno de los funcionarios públicos.
Está basado en Gemma-3-27B y se ejecuta en la nube privada de la administración, en el supercomputador Hércules.
Está basado en Gemma-3-27B y se ejecuta en la nube privada de la administración, en el supercomputador Hércules.

Andalucía anuncia JuntaGPT: la IA llega a la administración pública de la mano de Google y Gemma 3
Blog sobre informática, tecnología y seguridad con manuales, tutoriales y documentación sobre herramientas y programas
blog.elhacker.net
June 17, 2025 at 7:33 PM
La Junta de Andalucía ha lanzado un chatbot con RAG, precargado con documentación de la administración, para uso interno de los funcionarios públicos.
Está basado en Gemma-3-27B y se ejecuta en la nube privada de la administración, en el supercomputador Hércules.
Está basado en Gemma-3-27B y se ejecuta en la nube privada de la administración, en el supercomputador Hércules.
Qwen3 está muy bien, pero es DEMASIADO verboso para usarlo como agente, 10 minutos escupiendo a 90 tokens/s y no acaba.
June 6, 2025 at 8:29 AM
Qwen3 está muy bien, pero es DEMASIADO verboso para usarlo como agente, 10 minutos escupiendo a 90 tokens/s y no acaba.
Los modelos saben cuando están siendo evaluados, lo cual implica que las evaluaciones de seguridad podrían no ser efectivas.
Podrían 'finjir' estar correctamente alineados, porque es lo que se espera de ellos.
Podrían 'finjir' estar correctamente alineados, porque es lo que se espera de ellos.

June 5, 2025 at 10:57 PM
Los modelos saben cuando están siendo evaluados, lo cual implica que las evaluaciones de seguridad podrían no ser efectivas.
Podrían 'finjir' estar correctamente alineados, porque es lo que se espera de ellos.
Podrían 'finjir' estar correctamente alineados, porque es lo que se espera de ellos.
Por último, ya que estamos, Qwen-3 ha sido bastante decepcionante en general, pero el modelo 30B-A3 es muy interesante por su rapidez, da gusto verlo escupir tokens.
May 19, 2025 at 8:02 PM
Por último, ya que estamos, Qwen-3 ha sido bastante decepcionante en general, pero el modelo 30B-A3 es muy interesante por su rapidez, da gusto verlo escupir tokens.
Mistral-Small-3.1 en cambio ha sido una decepción tras usarlo más en profundidad. Es un modelo muy rígido, bueno para seguir instrucciones, similar en ese aspecto a Llama-3, pero sin ninguna 'chispa'.
May 19, 2025 at 7:59 PM
Mistral-Small-3.1 en cambio ha sido una decepción tras usarlo más en profundidad. Es un modelo muy rígido, bueno para seguir instrucciones, similar en ese aspecto a Llama-3, pero sin ninguna 'chispa'.
Reactivo esta cuenta después de mucho tiempo para desdecirme de mi último post (ya borrado): Gemma-3 es de hecho un muy buen modelo, de lo mejor en sus respectivas categorías como modelo de propósito general.
May 19, 2025 at 7:57 PM
Reactivo esta cuenta después de mucho tiempo para desdecirme de mi último post (ya borrado): Gemma-3 es de hecho un muy buen modelo, de lo mejor en sus respectivas categorías como modelo de propósito general.
Reposted by Alan

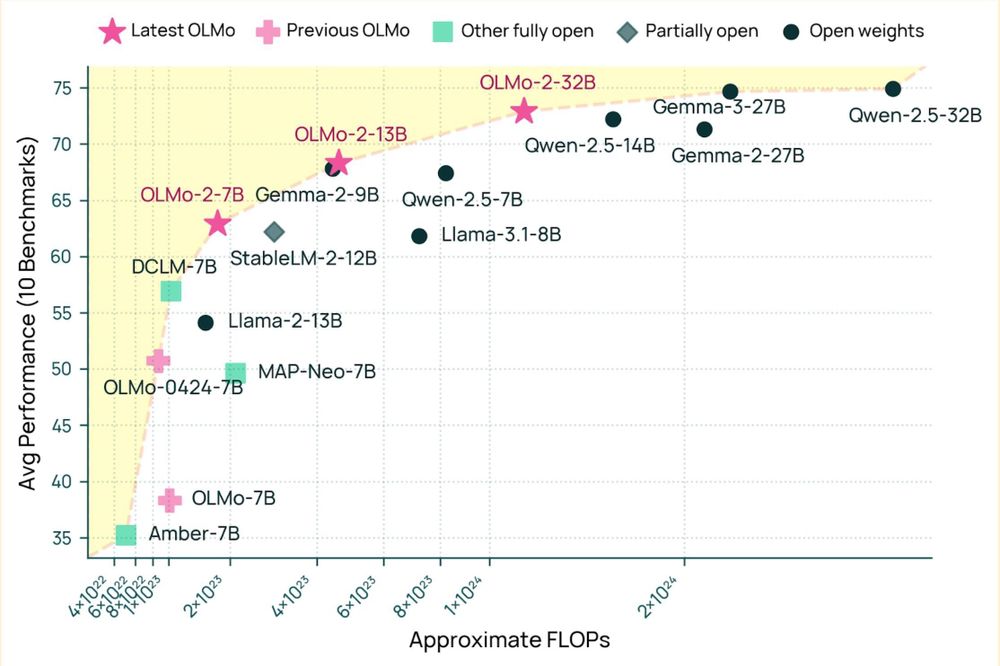
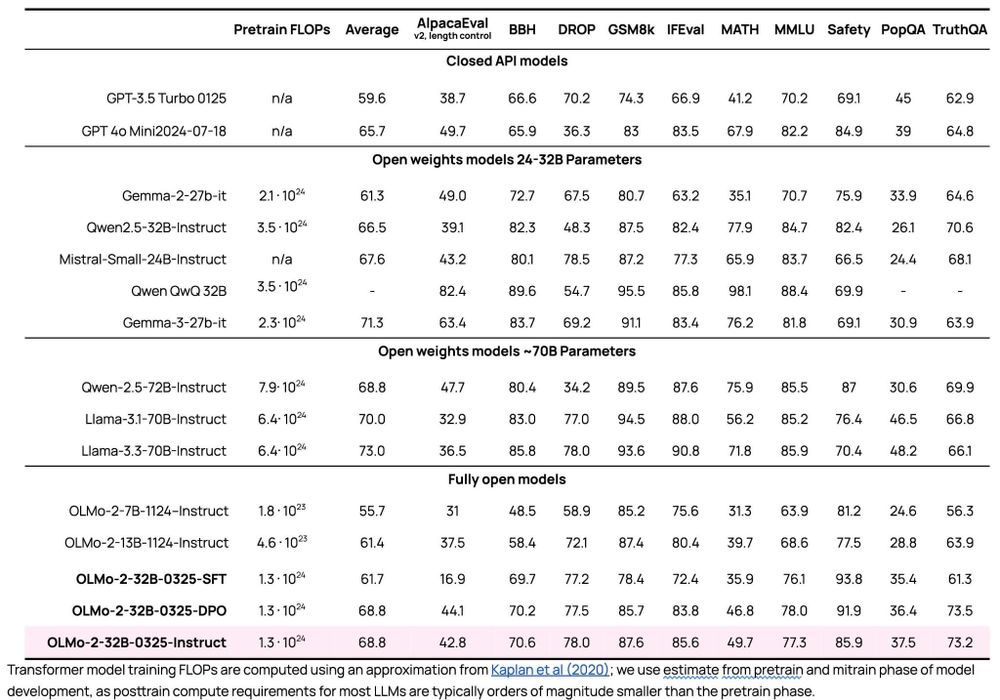
A very exciting day for open-source AI! We're releasing our biggest open source model yet -- OLMo 2 32B -- and it beats the latest GPT 3.5, GPT 4o mini, and leading open weight models like Qwen and Mistral. As usual, all data, weights, code, etc. are available.
March 13, 2025 at 6:16 PM
A very exciting day for open-source AI! We're releasing our biggest open source model yet -- OLMo 2 32B -- and it beats the latest GPT 3.5, GPT 4o mini, and leading open weight models like Qwen and Mistral. As usual, all data, weights, code, etc. are available.
Reposted by Alan

How can robots reliably place objects in diverse real-world tasks?
🤖🔍 Placement is hard! - objects vary in shape & placement modes (such as stacking, hanging, insertion)
AnyPlace predicts placement poses of unseen objects in real-world with ony using synthetic training data!
Read on👇
🤖🔍 Placement is hard! - objects vary in shape & placement modes (such as stacking, hanging, insertion)
AnyPlace predicts placement poses of unseen objects in real-world with ony using synthetic training data!
Read on👇
February 24, 2025 at 10:11 PM
How can robots reliably place objects in diverse real-world tasks?
🤖🔍 Placement is hard! - objects vary in shape & placement modes (such as stacking, hanging, insertion)
AnyPlace predicts placement poses of unseen objects in real-world with ony using synthetic training data!
Read on👇
🤖🔍 Placement is hard! - objects vary in shape & placement modes (such as stacking, hanging, insertion)
AnyPlace predicts placement poses of unseen objects in real-world with ony using synthetic training data!
Read on👇
Un grupo de investigadores de la @uneduniv.bsky.social ha evaluado varios modelos en el clásico benchmark MMLU y en un examen de la UNED (nunca publicado), pero cambiando la respuesta correcta por "ninguna de las anteriores" (noto)
Los resultados caen drásticamente en todos los casos!
Los resultados caen drásticamente en todos los casos!

February 20, 2025 at 6:15 PM
Un grupo de investigadores de la @uneduniv.bsky.social ha evaluado varios modelos en el clásico benchmark MMLU y en un examen de la UNED (nunca publicado), pero cambiando la respuesta correcta por "ninguna de las anteriores" (noto)
Los resultados caen drásticamente en todos los casos!
Los resultados caen drásticamente en todos los casos!
Reposted by Alan

I'm very happy to announce a strategic partnership between @wikimediafoundation.org enterprise and Pleias for open, ethical and trustworthy AI innovation. enterprise.wikimedia.com/blog/pleias-...

February 18, 2025 at 4:16 PM
I'm very happy to announce a strategic partnership between @wikimediafoundation.org enterprise and Pleias for open, ethical and trustworthy AI innovation. enterprise.wikimedia.com/blog/pleias-...
Reposted by Alan

We're looking for testers for our closed Beta before launching on the Google Play Store! 🚀
If you're interested in manage your followers and unfollows, send us a DM with your Gmail address, and we'll send you the instructions to join and download the app
(Android only for now!)
If you're interested in manage your followers and unfollows, send us a DM with your Gmail address, and we'll send you the instructions to join and download the app
(Android only for now!)

February 13, 2025 at 10:08 PM
We're looking for testers for our closed Beta before launching on the Google Play Store! 🚀
If you're interested in manage your followers and unfollows, send us a DM with your Gmail address, and we'll send you the instructions to join and download the app
(Android only for now!)
If you're interested in manage your followers and unfollows, send us a DM with your Gmail address, and we'll send you the instructions to join and download the app
(Android only for now!)
I'm still not confident what the future of "reasoning" on LLMs is because, while they have shown impressive capabilities on some tasks, they still feel weird and lacking of "spark". No one has truly beaten Sonnet 3.5 yet despite months of hard efforts.
I hope Claude 4 will clarify this soon.
I hope Claude 4 will clarify this soon.

this is not a drill! Claude 4 is going to be released soon
as expected, it's not a "reasoning model", it's just a regular LLM that can reason as needed
i'm extremely excited to get my hands on this one. Anthropic has always placed usability over performance
techcrunch.com/2025/02/13/a...
as expected, it's not a "reasoning model", it's just a regular LLM that can reason as needed
i'm extremely excited to get my hands on this one. Anthropic has always placed usability over performance
techcrunch.com/2025/02/13/a...

Anthropic's next major AI model could arrive within weeks | TechCrunch
AI startup Anthropic is gearing up to release its next major AI model, according to a report Thursday from The Information.
techcrunch.com
February 14, 2025 at 4:57 PM
I'm still not confident what the future of "reasoning" on LLMs is because, while they have shown impressive capabilities on some tasks, they still feel weird and lacking of "spark". No one has truly beaten Sonnet 3.5 yet despite months of hard efforts.
I hope Claude 4 will clarify this soon.
I hope Claude 4 will clarify this soon.
Reposted by Alan
In case it interest anyone: I went through all the competing definitions of "open source ai" in a short blog post. And the ongoing clarification process. pleias.fr/blog/blogwha...
February 13, 2025 at 6:08 PM
In case it interest anyone: I went through all the competing definitions of "open source ai" in a short blog post. And the ongoing clarification process. pleias.fr/blog/blogwha...
Reposted by Alan

The development of AI systems offers a crucial perspective for thinking about data, as it provides a strong case for creating value using publicly available data. https://opensource.org/datagovernance #opensourceai

Data Governance in Open Source AI
Data Governance in Open Source AI
opensource.org
February 13, 2025 at 6:42 PM
The development of AI systems offers a crucial perspective for thinking about data, as it provides a strong case for creating value using publicly available data. https://opensource.org/datagovernance #opensourceai
Mistral small seems confused

February 11, 2025 at 12:07 AM
Mistral small seems confused
Me confirman fuentes con conocimiento que lo de los Goya NO fue traducción automática.
Había un intérprete trauduciendo para los asistentes y una estenotipista transcribiendo al intérprete para los subtítulos de la TV. #Goya2025
Había un intérprete trauduciendo para los asistentes y una estenotipista transcribiendo al intérprete para los subtítulos de la TV. #Goya2025
February 9, 2025 at 2:37 PM
Me confirman fuentes con conocimiento que lo de los Goya NO fue traducción automática.
Había un intérprete trauduciendo para los asistentes y una estenotipista transcribiendo al intérprete para los subtítulos de la TV. #Goya2025
Había un intérprete trauduciendo para los asistentes y una estenotipista transcribiendo al intérprete para los subtítulos de la TV. #Goya2025
En el panorama de la IA europeo también se están haciendo algunos desarrollos muy interesantes, como esto de Kyutai (🇫🇷)
Un modelo de interpretación simultánea (real-time), capaz hasta de reproducir el acento del orador, ¡y corre en un móvil!
De momento solo francés->inglés, pero muy prometedor:
Un modelo de interpretación simultánea (real-time), capaz hasta de reproducir el acento del orador, ¡y corre en un móvil!
De momento solo francés->inglés, pero muy prometedor:
February 8, 2025 at 2:04 PM
En el panorama de la IA europeo también se están haciendo algunos desarrollos muy interesantes, como esto de Kyutai (🇫🇷)
Un modelo de interpretación simultánea (real-time), capaz hasta de reproducir el acento del orador, ¡y corre en un móvil!
De momento solo francés->inglés, pero muy prometedor:
Un modelo de interpretación simultánea (real-time), capaz hasta de reproducir el acento del orador, ¡y corre en un móvil!
De momento solo francés->inglés, pero muy prometedor:
Reposted by Alan

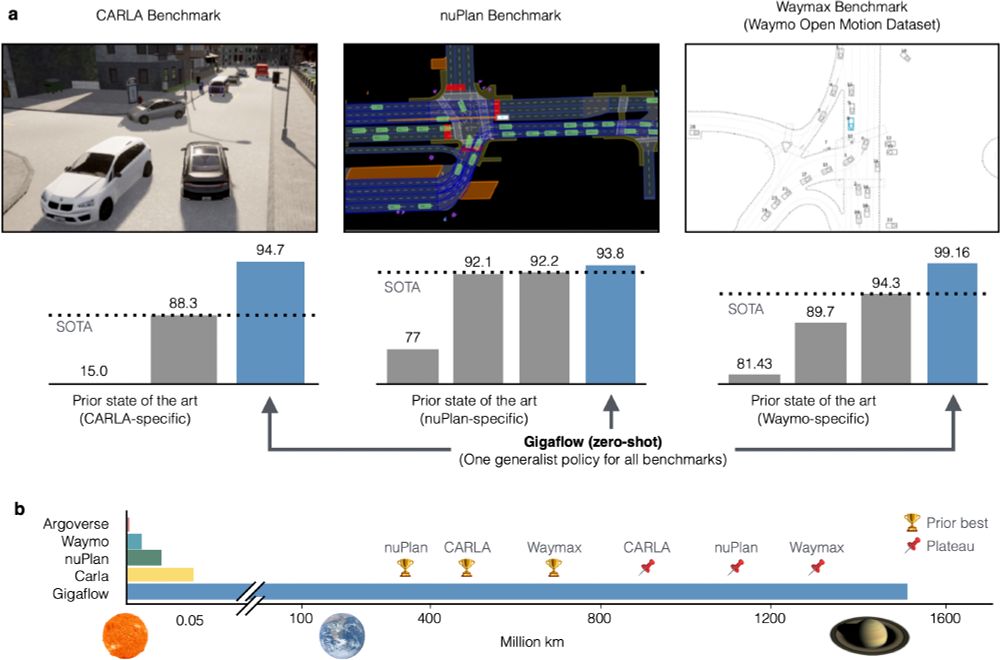
We've built a simulated driving agent that we trained on 1.6 billion km of driving with no human data.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
February 6, 2025 at 6:34 PM
We've built a simulated driving agent that we trained on 1.6 billion km of driving with no human data.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
Reposted by Alan

Can pretrained diffusion models be connected for cross-modal generation?
📢 Introducing AV-Link ♾️
Bridging unimodal diffusion models in one self-contained framework to enable:
📽️ ➡️ 🔊 Video-to-Audio generation.
🔊 ➡️ 📽️ Audio-to-Video generation.
🌐: snap-research.github.io/AVLink/
⤵️ Results
📢 Introducing AV-Link ♾️
Bridging unimodal diffusion models in one self-contained framework to enable:
📽️ ➡️ 🔊 Video-to-Audio generation.
🔊 ➡️ 📽️ Audio-to-Video generation.
🌐: snap-research.github.io/AVLink/
⤵️ Results
January 14, 2025 at 6:13 PM
Can pretrained diffusion models be connected for cross-modal generation?
📢 Introducing AV-Link ♾️
Bridging unimodal diffusion models in one self-contained framework to enable:
📽️ ➡️ 🔊 Video-to-Audio generation.
🔊 ➡️ 📽️ Audio-to-Video generation.
🌐: snap-research.github.io/AVLink/
⤵️ Results
📢 Introducing AV-Link ♾️
Bridging unimodal diffusion models in one self-contained framework to enable:
📽️ ➡️ 🔊 Video-to-Audio generation.
🔊 ➡️ 📽️ Audio-to-Video generation.
🌐: snap-research.github.io/AVLink/
⤵️ Results
Por fin un modelo [de retrieval] en español al nivel del inglés! y multimodal! Pintaza.

there's a new multimodal retrieval model in town 🤠
@llamaindex.bsky.social released vdr-2b-multi-v1
> uses 70% less image tokens, yet outperforming other dse-qwen2 based models
> 3x faster inference with less VRAM 💨
> shrinkable with matryoshka 🪆
huggingface.co/collections/...
@llamaindex.bsky.social released vdr-2b-multi-v1
> uses 70% less image tokens, yet outperforming other dse-qwen2 based models
> 3x faster inference with less VRAM 💨
> shrinkable with matryoshka 🪆
huggingface.co/collections/...

January 13, 2025 at 9:16 PM
Por fin un modelo [de retrieval] en español al nivel del inglés! y multimodal! Pintaza.
Reposted by Alan

Increasingly large food.
All made by me with veo 2, the serious point is to note how impressive the "physics" of these models have become (also the consistency, like the spilled burrito across two different shots), there are some issues, obviously, but big advances.
All made by me with veo 2, the serious point is to note how impressive the "physics" of these models have become (also the consistency, like the spilled burrito across two different shots), there are some issues, obviously, but big advances.
January 8, 2025 at 9:01 PM
Increasingly large food.
All made by me with veo 2, the serious point is to note how impressive the "physics" of these models have become (also the consistency, like the spilled burrito across two different shots), there are some issues, obviously, but big advances.
All made by me with veo 2, the serious point is to note how impressive the "physics" of these models have become (also the consistency, like the spilled burrito across two different shots), there are some issues, obviously, but big advances.
Researchers are using Claude to analyze acoustic data for whale conservation, increasing accuracy from 76% of previous methods that used to take 2 weeks of manual work to 89% in real time.
There are lots of useful AI applications just waiting to be implemented, in all fields.
There are lots of useful AI applications just waiting to be implemented, in all fields.

The University of Sydney and Accenture accelerate whale conservation with Claude
Learn how researchers achieved 89.4% accuracy in whale detection using Claude AI, transforming a two-week manual process into instant insights for marine conservation. See how AI is revolutionizing oc...
www.anthropic.com
January 7, 2025 at 11:20 PM
Researchers are using Claude to analyze acoustic data for whale conservation, increasing accuracy from 76% of previous methods that used to take 2 weeks of manual work to 89% in real time.
There are lots of useful AI applications just waiting to be implemented, in all fields.
There are lots of useful AI applications just waiting to be implemented, in all fields.
Todos los vídeos de este hilo son oro puro, pero este en concreto captura muy bien las virtudes de Veo2. Fijaos como rota el barril acompañando de forma coherente los movimientos del gorila (salvo un error, notable pero que pasa desapercibido)
January 4, 2025 at 11:15 PM
Todos los vídeos de este hilo son oro puro, pero este en concreto captura muy bien las virtudes de Veo2. Fijaos como rota el barril acompañando de forma coherente los movimientos del gorila (salvo un error, notable pero que pasa desapercibido)
Reposted by Alan

RAG systems are only as good as the data fed into them. In real world situations, it's hard to come by perfect contexts. How do noisy contexts impact RAG performance? We built a dataset to find out 👇

📚 How good are language models at utilising contexts in RAG scenarios?
We release 🧙🏽♀️DRUID to facilitate studies of context usage in real-world scenarios.
arxiv.org/abs/2412.17031
w/ @saravera.bsky.social, H.Yu, @rnv.bsky.social, C.Lioma, M.Maistro, @apepa.bsky.social and @iaugenstein.bsky.social ⭐️
We release 🧙🏽♀️DRUID to facilitate studies of context usage in real-world scenarios.
arxiv.org/abs/2412.17031
w/ @saravera.bsky.social, H.Yu, @rnv.bsky.social, C.Lioma, M.Maistro, @apepa.bsky.social and @iaugenstein.bsky.social ⭐️

A Reality Check on Context Utilisation for Retrieval-Augmented Generation
Retrieval-augmented generation (RAG) helps address the limitations of the parametric knowledge embedded within a language model (LM). However, investigations of how LMs utilise retrieved information o...
arxiv.org
January 2, 2025 at 4:01 PM
RAG systems are only as good as the data fed into them. In real world situations, it's hard to come by perfect contexts. How do noisy contexts impact RAG performance? We built a dataset to find out 👇
Hoy está circulando una nueva estimación de tamaños, sacada de un paper de Microsoft. No aportan ningún razonamiento y nadie parece ponerse de acuerdo, así que yo mantengo mi apuesta (para modelos densos):
Sonnet: 600B
Flash: 20B
4o: 600B
4o-mini: 40B
oX: 3T
oX-mini: 600B
Sonnet: 600B
Flash: 20B
4o: 600B
4o-mini: 40B
oX: 3T
oX-mini: 600B

January 2, 2025 at 4:05 PM
Hoy está circulando una nueva estimación de tamaños, sacada de un paper de Microsoft. No aportan ningún razonamiento y nadie parece ponerse de acuerdo, así que yo mantengo mi apuesta (para modelos densos):
Sonnet: 600B
Flash: 20B
4o: 600B
4o-mini: 40B
oX: 3T
oX-mini: 600B
Sonnet: 600B
Flash: 20B
4o: 600B
4o-mini: 40B
oX: 3T
oX-mini: 600B