



David Smith
@dasmiq.bsky.social
Associate professor of computer science at Northeastern University. Natural language processing, digital humanities, OCR, computational bibliography, and computational social sciences. Artificial intelligence is an archival science.
Reposted by David Smith

Interesting about Claude. A few years ago I tried to use Gemini1.5 to OCR a few pages of 19th C texts from the HTDL and got a RECITATION error. Apparently I was asking the model to output "passages that are "recited" from copyrighted material in the foundational LLM's training data."
November 26, 2025 at 4:27 PM
Interesting about Claude. A few years ago I tried to use Gemini1.5 to OCR a few pages of 19th C texts from the HTDL and got a RECITATION error. Apparently I was asking the model to output "passages that are "recited" from copyrighted material in the foundational LLM's training data."
Reposted by David Smith

FWIW, I've been asking Claude to transcribe both printed text and handwriting that it almost certainly hasn't seen (e.g. photos from pretty obscure docs in archives) for a couple of years, and it has gotten massively better this year. Still has difficulty with some stuff (esp. very period-specific
November 26, 2025 at 4:01 PM
FWIW, I've been asking Claude to transcribe both printed text and handwriting that it almost certainly hasn't seen (e.g. photos from pretty obscure docs in archives) for a couple of years, and it has gotten massively better this year. Still has difficulty with some stuff (esp. very period-specific
Reposted by David Smith

I was wondering this! Namely whether it had already seen the plaintext in training.
Dan's post is great, as usual! It's exciting to move to full-page models that allow us to engage with the text and avoid mucking around with image processing. But we don't need to pronounce a eulogy on paleographers yet. The War Department and Jane Austen examples are likely known to the LM. 1/

New issue of my newsletter: "The Writing Is on the Wall for Handwriting Recognition" — One of the hardest problems in digital humanities has finally been solved, and it's a good use of AI newsletter.dancohen.org/archive/the-...
November 26, 2025 at 3:20 PM
I was wondering this! Namely whether it had already seen the plaintext in training.
Dan's post is great, as usual! It's exciting to move to full-page models that allow us to engage with the text and avoid mucking around with image processing. But we don't need to pronounce a eulogy on paleographers yet. The War Department and Jane Austen examples are likely known to the LM. 1/
New issue of my newsletter: "The Writing Is on the Wall for Handwriting Recognition" — One of the hardest problems in digital humanities has finally been solved, and it's a good use of AI newsletter.dancohen.org/archive/the-...

The Writing Is on the Wall for Handwriting Recognition
One of the hardest problems in digital humanities has finally been solved
newsletter.dancohen.org
November 26, 2025 at 3:15 PM
Dan's post is great, as usual! It's exciting to move to full-page models that allow us to engage with the text and avoid mucking around with image processing. But we don't need to pronounce a eulogy on paleographers yet. The War Department and Jane Austen examples are likely known to the LM. 1/
Reposted by David Smith
Here at UMass Amherst CICS, we’re searching for TT faculty in NLP – see the link from
www.cics.umass.edu/about/employ...
I’m happy to answer questions of course, too!
www.cics.umass.edu/about/employ...
I’m happy to answer questions of course, too!
Faculty Positions
Open tenure-track and teaching faculty positions in computer science and informatics at the Manning College of Information and Computer Sciences
www.cics.umass.edu
November 26, 2025 at 4:21 AM
Here at UMass Amherst CICS, we’re searching for TT faculty in NLP – see the link from
www.cics.umass.edu/about/employ...
I’m happy to answer questions of course, too!
www.cics.umass.edu/about/employ...
I’m happy to answer questions of course, too!
Reposted by David Smith

Back to EpiDoc: A query to the www.jiscmail.ac.uk/EPIDOC-MARKUP list would surely return pointers to dozens of repos of EpiDoc files with Greek inscriptions. I'd love to see that list!
JISCMail - EPIDOC-MARKUP List at WWW.JISCMAIL.AC.UK
www.jiscmail.ac.uk
November 26, 2025 at 11:29 AM
Back to EpiDoc: A query to the www.jiscmail.ac.uk/EPIDOC-MARKUP list would surely return pointers to dozens of repos of EpiDoc files with Greek inscriptions. I'd love to see that list!
Reposted by David Smith
I believe Inscriptions of the Northern Black Sea also have EpiDoc files available (github.com/kingsdigital...), but I haven't checked how up to date these are.
Many EpiDoc projects listed at: wiki.digitalclassicist.org/Category:Epi... . At least some I haven't thought of will have downloadable XML.
Many EpiDoc projects listed at: wiki.digitalclassicist.org/Category:Epi... . At least some I haven't thought of will have downloadable XML.
GitHub - kingsdigitallab/iospe
Contribute to kingsdigitallab/iospe development by creating an account on GitHub.
github.com
November 26, 2025 at 11:22 AM
I believe Inscriptions of the Northern Black Sea also have EpiDoc files available (github.com/kingsdigital...), but I haven't checked how up to date these are.
Many EpiDoc projects listed at: wiki.digitalclassicist.org/Category:Epi... . At least some I haven't thought of will have downloadable XML.
Many EpiDoc projects listed at: wiki.digitalclassicist.org/Category:Epi... . At least some I haven't thought of will have downloadable XML.
Reposted by David Smith
EpiDoc: There are repos for I.Aphrodisias (github.com/Aphrodisias/...), IRCyr (github.com/kingsdigital...), IGCyr (doi.org/10.6092/unib...), ICretaInst (github.com/IreneVagiona...) with c. 100s – 1000s of EpiDoc files in each.

GitHub - Aphrodisias/IAph_EFES: Preparation of the future publication built on the EFES platform of Inscriptions of Aphrodisias, a second edition of the 2007 publication at https://insaph.kcl.ac.uk/ia...
Preparation of the future publication built on the EFES platform of Inscriptions of Aphrodisias, a second edition of the 2007 publication at https://insaph.kcl.ac.uk/iaph2007/ - Aphrodisias/IAph_EFES
github.com
November 26, 2025 at 11:15 AM
EpiDoc: There are repos for I.Aphrodisias (github.com/Aphrodisias/...), IRCyr (github.com/kingsdigital...), IGCyr (doi.org/10.6092/unib...), ICretaInst (github.com/IreneVagiona...) with c. 100s – 1000s of EpiDoc files in each.
A student is working on detecting gaps in text transcriptions. Does anyone in #DigiClass or beyond know of open transcriptions of ancient Greek inscriptions, in EpiDoc or otherwise, similar to papyri.info ? I've worked with literary texts and papyri, but I'm stumped on this.
papyri.info
November 25, 2025 at 10:20 PM
A student is working on detecting gaps in text transcriptions. Does anyone in #DigiClass or beyond know of open transcriptions of ancient Greek inscriptions, in EpiDoc or otherwise, similar to papyri.info ? I've worked with literary texts and papyri, but I'm stumped on this.
Reposted by David Smith

Que reste-t-il des textes médiévaux ? Pourquoi certains survivent et d’autres s’effacent ?
👉 Une séance de séminaire dédiée aux enjeux de la transmission textuelle dans le cadre du projet ERC LostMA avec @jbcamps.bsky.social
Rendez-vous demain à partir de 14h
Inscription 🔽
👉 Une séance de séminaire dédiée aux enjeux de la transmission textuelle dans le cadre du projet ERC LostMA avec @jbcamps.bsky.social
Rendez-vous demain à partir de 14h
Inscription 🔽

Modelling the transmission and survival of texts and manuscripts | médialab Sciences Po
Le séminaire du médialab accueille Jean-Baptiste Camps pour une séance sur le projet LostMA sur la transmission et la survie des anciens textes. Il analysera comment et pourquoi certains textes manusc...
medialab.sciencespo.fr
November 24, 2025 at 10:35 AM
Que reste-t-il des textes médiévaux ? Pourquoi certains survivent et d’autres s’effacent ?
👉 Une séance de séminaire dédiée aux enjeux de la transmission textuelle dans le cadre du projet ERC LostMA avec @jbcamps.bsky.social
Rendez-vous demain à partir de 14h
Inscription 🔽
👉 Une séance de séminaire dédiée aux enjeux de la transmission textuelle dans le cadre du projet ERC LostMA avec @jbcamps.bsky.social
Rendez-vous demain à partir de 14h
Inscription 🔽
Reposted by David Smith

Three exciting opportunities at
@msftresearch.bsky.social in NYC!!! 🎉
Internship w/ FATE: apply.careers.microsoft.com/careers/job?...
Internship w/ STAC on AI evaluation and measurement: apply.careers.microsoft.com/careers/job?...
Postdoc w/ FATE: apply.careers.microsoft.com/careers/job?...
@msftresearch.bsky.social in NYC!!! 🎉
Internship w/ FATE: apply.careers.microsoft.com/careers/job?...
Internship w/ STAC on AI evaluation and measurement: apply.careers.microsoft.com/careers/job?...
Postdoc w/ FATE: apply.careers.microsoft.com/careers/job?...
FATE internships: apply.careers.microsoft.com/careers/job?...
FATE postdocs: apply.careers.microsoft.com/careers/job?...
And internships with our close collaborators at STAC: apply.careers.microsoft.com/careers/job?...
FATE postdocs: apply.careers.microsoft.com/careers/job?...
And internships with our close collaborators at STAC: apply.careers.microsoft.com/careers/job?...
November 24, 2025 at 3:33 PM
Three exciting opportunities at
@msftresearch.bsky.social in NYC!!! 🎉
Internship w/ FATE: apply.careers.microsoft.com/careers/job?...
Internship w/ STAC on AI evaluation and measurement: apply.careers.microsoft.com/careers/job?...
Postdoc w/ FATE: apply.careers.microsoft.com/careers/job?...
@msftresearch.bsky.social in NYC!!! 🎉
Internship w/ FATE: apply.careers.microsoft.com/careers/job?...
Internship w/ STAC on AI evaluation and measurement: apply.careers.microsoft.com/careers/job?...
Postdoc w/ FATE: apply.careers.microsoft.com/careers/job?...
Reposted by David Smith

Building datasets to train smaller, task-focused models used to be incredibly time-consuming.
Very excited to see SAM3 massively lower that barrier. Describe the class you want to detect and get annotated datasets automatically!
Try it yourself: huggingface.co/datasets/uv-...!
Very excited to see SAM3 massively lower that barrier. Describe the class you want to detect and get annotated datasets automatically!
Try it yourself: huggingface.co/datasets/uv-...!


November 21, 2025 at 1:30 PM
Building datasets to train smaller, task-focused models used to be incredibly time-consuming.
Very excited to see SAM3 massively lower that barrier. Describe the class you want to detect and get annotated datasets automatically!
Try it yourself: huggingface.co/datasets/uv-...!
Very excited to see SAM3 massively lower that barrier. Describe the class you want to detect and get annotated datasets automatically!
Try it yourself: huggingface.co/datasets/uv-...!
Reposted by David Smith

Spread the word! 📢 The FATE (Fairness, Accountability, Transparency, and Ethics) group at @msftresearch.bsky.social in NYC is hiring interns and postdocs to start in summer 2026! 🎉
Apply by *December 15* for full consideration.
Apply by *December 15* for full consideration.
November 20, 2025 at 8:11 PM
Spread the word! 📢 The FATE (Fairness, Accountability, Transparency, and Ethics) group at @msftresearch.bsky.social in NYC is hiring interns and postdocs to start in summer 2026! 🎉
Apply by *December 15* for full consideration.
Apply by *December 15* for full consideration.
Reposted by David Smith

We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.


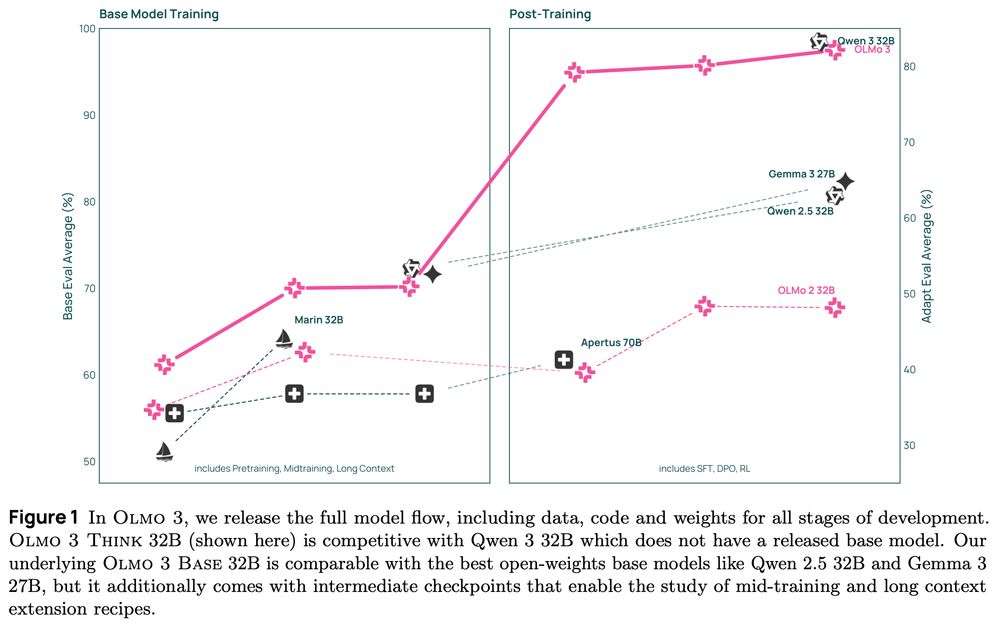
November 20, 2025 at 2:32 PM
We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
Reposted by David Smith

📢 The #CHR2025 proceedings are out!
97 papers, ~1600 pages of computational humanities 🔥 Now published via the new Anthology of Computers and the Humanities, with DOIs for every paper.
🔗 anthology.ach.org/volumes/vol0...
And don’t forget: registration closes tomorrow (20 Nov)!
97 papers, ~1600 pages of computational humanities 🔥 Now published via the new Anthology of Computers and the Humanities, with DOIs for every paper.
🔗 anthology.ach.org/volumes/vol0...
And don’t forget: registration closes tomorrow (20 Nov)!

Edited by Taylor Arnold, Margherita Fantoli, and Ruben Ros
anthology.ach.org
November 19, 2025 at 12:53 PM
📢 The #CHR2025 proceedings are out!
97 papers, ~1600 pages of computational humanities 🔥 Now published via the new Anthology of Computers and the Humanities, with DOIs for every paper.
🔗 anthology.ach.org/volumes/vol0...
And don’t forget: registration closes tomorrow (20 Nov)!
97 papers, ~1600 pages of computational humanities 🔥 Now published via the new Anthology of Computers and the Humanities, with DOIs for every paper.
🔗 anthology.ach.org/volumes/vol0...
And don’t forget: registration closes tomorrow (20 Nov)!
Reposted by David Smith

2/ GovScape is built on top of the End of Term Web Archive (eotarchive.org) and currently contains all renderable PDFs (50 pages or fewer) from the 2020 crawl, documenting the first Trump administration. An overview of GovScape’s search functionality can be found in this diagram.

November 18, 2025 at 8:19 PM
2/ GovScape is built on top of the End of Term Web Archive (eotarchive.org) and currently contains all renderable PDFs (50 pages or fewer) from the 2020 crawl, documenting the first Trump administration. An overview of GovScape’s search functionality can be found in this diagram.
Reposted by David Smith
1/ Announcing GovScape – a public search system for 10 million U.S. government PDFs (70 million pages)! GovScape offers visual search, semantic text search, and keyword search. Explore below:
Website: www.govscape.net
ArXiv link: arxiv.org/abs/2511.11010
Website: www.govscape.net
ArXiv link: arxiv.org/abs/2511.11010
www.govscape.net
November 18, 2025 at 8:19 PM
1/ Announcing GovScape – a public search system for 10 million U.S. government PDFs (70 million pages)! GovScape offers visual search, semantic text search, and keyword search. Explore below:
Website: www.govscape.net
ArXiv link: arxiv.org/abs/2511.11010
Website: www.govscape.net
ArXiv link: arxiv.org/abs/2511.11010
Reposted by David Smith

The new features are still in alpha—but @djevans.bsky.social's contextual tools for Viral Texts data are live clusters.viraltexts.org
Click "View witness in context" to see a given reprint on the newspaper page, alongside other reprints on that page—click a cluster ID here to see its other reprints
Click "View witness in context" to see a given reprint on the newspaper page, alongside other reprints on that page—click a cluster ID here to see its other reprints


November 17, 2025 at 5:34 PM
The new features are still in alpha—but @djevans.bsky.social's contextual tools for Viral Texts data are live clusters.viraltexts.org
Click "View witness in context" to see a given reprint on the newspaper page, alongside other reprints on that page—click a cluster ID here to see its other reprints
Click "View witness in context" to see a given reprint on the newspaper page, alongside other reprints on that page—click a cluster ID here to see its other reprints
Reposted by David Smith

THE STEAM MAN OF THE PRARIE, an “Edisonade” (story about a boy wonder inventor) by Edward S. Ellis published as a literal dime novel in 1868. Not “AI” but a ten-foot steam-powered mechanical man used as transport and surrogate labor. Cover image here is from the Rosenbach Library, via Wikipedia.

November 17, 2025 at 1:41 AM
THE STEAM MAN OF THE PRARIE, an “Edisonade” (story about a boy wonder inventor) by Edward S. Ellis published as a literal dime novel in 1868. Not “AI” but a ten-foot steam-powered mechanical man used as transport and surrogate labor. Cover image here is from the Rosenbach Library, via Wikipedia.
Reposted by David Smith

Trying an experiment in good old-fashioned blogging about papers: dallascard.github.io/granular-mat...
Language Model Hacking - Granular Material
dallascard.github.io
November 16, 2025 at 7:51 PM
Trying an experiment in good old-fashioned blogging about papers: dallascard.github.io/granular-mat...
Reposted by David Smith

For example, one really helpful thing about a delegation framing is that its natural to think about any technology as an agent with at least two principals - say, you and Sam Altman. That seems mostly invisible from a fantasy HR perspective.
November 15, 2025 at 10:29 AM
For example, one really helpful thing about a delegation framing is that its natural to think about any technology as an agent with at least two principals - say, you and Sam Altman. That seems mostly invisible from a fantasy HR perspective.
Reposted by David Smith
Ironically, and now slightly painfully, I've been pushing formal models of delegation for thinking clearly about technology and tech ethics for years in class. In my partial defence none of that demands turning what is abstractly a delegation problem into an exercise in fantasy HR.
November 15, 2025 at 9:59 AM
Ironically, and now slightly painfully, I've been pushing formal models of delegation for thinking clearly about technology and tech ethics for years in class. In my partial defence none of that demands turning what is abstractly a delegation problem into an exercise in fantasy HR.
Reposted by David Smith

(2/2) Morphology-aware tokenization improves Latin LM performance on four downstream tasks, including gains for out-of-domain texts and rare words.
📄 arxiv.org/abs/2511.09709
📄 arxiv.org/abs/2511.09709

Contextual morphologically-guided tokenization for Latin encoder models
Tokenization is a critical component of language model pretraining, yet standard tokenization methods often prioritize information-theoretical goals like high compression and low fertility rather than...
arxiv.org
November 14, 2025 at 8:02 PM
(2/2) Morphology-aware tokenization improves Latin LM performance on four downstream tasks, including gains for out-of-domain texts and rare words.
📄 arxiv.org/abs/2511.09709
📄 arxiv.org/abs/2511.09709
Reposted by David Smith
(1/2) 🎉 New preprint: "Contextual Morphologically-Guided Tokenization for Latin Encoder Models"
w/ @diyclassics.bsky.social @brenocon.bsky.social
w/ @diyclassics.bsky.social @brenocon.bsky.social

November 14, 2025 at 8:02 PM
(1/2) 🎉 New preprint: "Contextual Morphologically-Guided Tokenization for Latin Encoder Models"
w/ @diyclassics.bsky.social @brenocon.bsky.social
w/ @diyclassics.bsky.social @brenocon.bsky.social
Reposted by David Smith

(2) The prediction view: the cost of processing each word in a sentence can be fully reduced to the word’s contextual predictability (i.e. surprisal). Predicting the next word is exactly what LLMs are trained to do, so they’re a great tool for evaluating this view. (3/n)
November 14, 2025 at 7:19 PM
(2) The prediction view: the cost of processing each word in a sentence can be fully reduced to the word’s contextual predictability (i.e. surprisal). Predicting the next word is exactly what LLMs are trained to do, so they’re a great tool for evaluating this view. (3/n)