

Donald Szlosek
@dszlosek.bsky.social
860 followers
4.3K following
180 posts
Biostatistician @IDEXX formerly at harvardmed, @BIDMChealth, @nasa. Big data, clinical trials, and medical diagnostics. Mainer. Opinions are my own. he/him
Posts
Media
Videos
Starter Packs



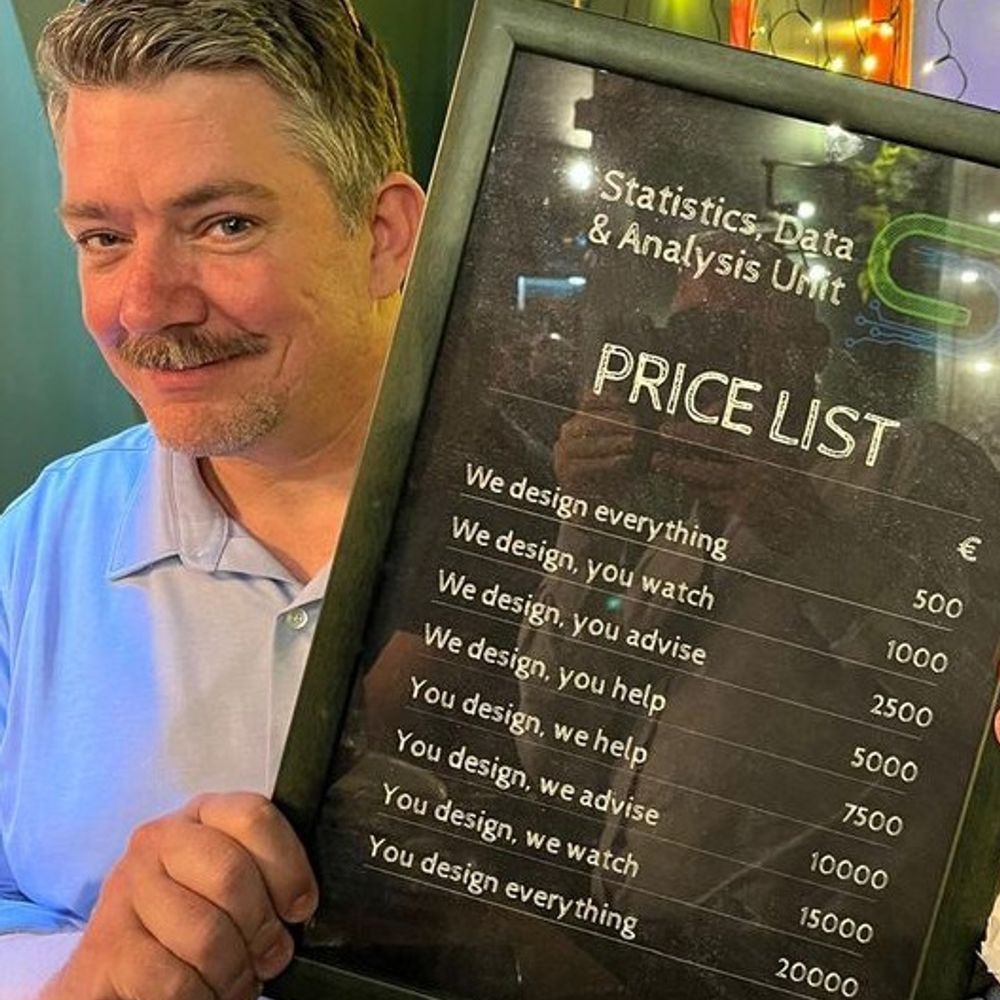


Reposted by Donald Szlosek

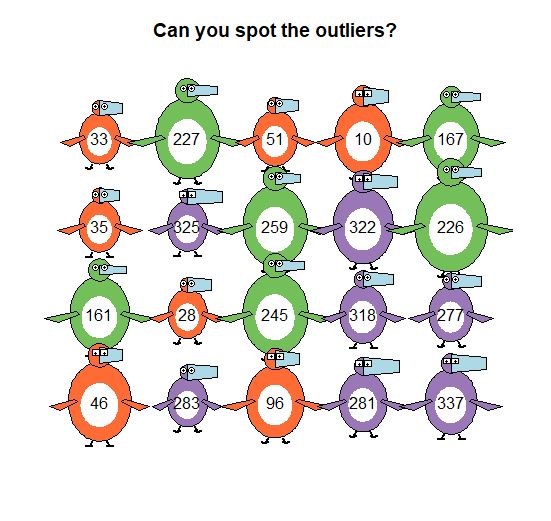
Reposted by Donald Szlosek



Reposted by Donald Szlosek


Reposted by Donald Szlosek


Reposted by Donald Szlosek


Reposted by Donald Szlosek



Reposted by Donald Szlosek


Reposted by Donald Szlosek

Reposted by Donald Szlosek

