



Sub-1B #Vision Language Model: Introducing OmniVision-968M 🔍
#NexaAI introduces #OmniVision, 968M #VisionLanguageModel for edge devices with 9x token reduction & enhanced accuracy via #DPO. Based on #Qwen & #SigLIP architecture. Try demo on #HuggingFace
nexa.ai/blogs/omni-v...
#ai
#NexaAI introduces #OmniVision, 968M #VisionLanguageModel for edge devices with 9x token reduction & enhanced accuracy via #DPO. Based on #Qwen & #SigLIP architecture. Try demo on #HuggingFace
nexa.ai/blogs/omni-v...
#ai

OmniVision-968M: World's Smallest Vision Language Model
Pocket-size multimodal model with 9x token reduction for on-device deployment
nexa.ai
November 26, 2024 at 8:22 AM
Sub-1B #Vision Language Model: Introducing OmniVision-968M 🔍
#NexaAI introduces #OmniVision, 968M #VisionLanguageModel for edge devices with 9x token reduction & enhanced accuracy via #DPO. Based on #Qwen & #SigLIP architecture. Try demo on #HuggingFace
nexa.ai/blogs/omni-v...
#ai
#NexaAI introduces #OmniVision, 968M #VisionLanguageModel for edge devices with 9x token reduction & enhanced accuracy via #DPO. Based on #Qwen & #SigLIP architecture. Try demo on #HuggingFace
nexa.ai/blogs/omni-v...
#ai

Explore a collection of visualizations demonstrating the effectiveness of promptable and open-vocabulary segmentation across various datasets. #visionlanguagemodel

Visualizing Promptable and Open-Vocabulary Segmentation Across Multiple Datasets
hackernoon.com
November 13, 2024 at 6:00 PM
Explore a collection of visualizations demonstrating the effectiveness of promptable and open-vocabulary segmentation across various datasets. #visionlanguagemodel
#UITARS Desktop: The Future of Computer Control through Natural Language 🖥️
🎯 #ByteDance introduces GUI agent powered by #VisionLanguageModel for intuitive computer control
Code: lnkd.in/eNKasq56
Paper: lnkd.in/eN5UPQ6V
Models: lnkd.in/eVRAwA-9
#ai
🧵 ↓
🎯 #ByteDance introduces GUI agent powered by #VisionLanguageModel for intuitive computer control
Code: lnkd.in/eNKasq56
Paper: lnkd.in/eN5UPQ6V
Models: lnkd.in/eVRAwA-9
#ai
🧵 ↓
January 22, 2025 at 6:34 PM
#UITARS Desktop: The Future of Computer Control through Natural Language 🖥️
🎯 #ByteDance introduces GUI agent powered by #VisionLanguageModel for intuitive computer control
Code: lnkd.in/eNKasq56
Paper: lnkd.in/eN5UPQ6V
Models: lnkd.in/eVRAwA-9
#ai
🧵 ↓
🎯 #ByteDance introduces GUI agent powered by #VisionLanguageModel for intuitive computer control
Code: lnkd.in/eNKasq56
Paper: lnkd.in/eN5UPQ6V
Models: lnkd.in/eVRAwA-9
#ai
🧵 ↓
Uni-OVSeg combines CLIP, multi-scale pixel decoders, and visual prompts for effective open-vocabulary segmentation, boosting weakly-supervised learning. #visionlanguagemodel

Advanced Open-Vocabulary Segmentation with Uni-OVSeg
hackernoon.com
November 13, 2024 at 4:01 PM
Uni-OVSeg combines CLIP, multi-scale pixel decoders, and visual prompts for effective open-vocabulary segmentation, boosting weakly-supervised learning. #visionlanguagemodel
Explore the datasets, including SA-1B and image-text pairs, used for training open-vocabulary segmentation. #visionlanguagemodel

Datasets and Evaluation Methods for Open-Vocabulary Segmentation Tasks
hackernoon.com
November 12, 2024 at 10:27 PM
Explore the datasets, including SA-1B and image-text pairs, used for training open-vocabulary segmentation. #visionlanguagemodel
Uni-OVSeg advances open-vocabulary segmentation, benefiting sectors like medical imaging and autonomous vehicles while addressing the risk of AI bias in dataset #visionlanguagemodel

Uni-OVSeg: A Step Towards Efficient and Bias-Resilient Vision Systems
hackernoon.com
November 12, 2024 at 10:27 PM
Uni-OVSeg advances open-vocabulary segmentation, benefiting sectors like medical imaging and autonomous vehicles while addressing the risk of AI bias in dataset #visionlanguagemodel
#MistralAI Document #AI: Advanced #OCR solution for complex document processing 📄
📺 www.youtube.com/watch?v=yrx...
🔧 Fine-tuned #VisionLanguageModel specifically designed for document understanding beyond traditional #OCR limitations that plague most business workflows
🧵 👇
📺 www.youtube.com/watch?v=yrx...
🔧 Fine-tuned #VisionLanguageModel specifically designed for document understanding beyond traditional #OCR limitations that plague most business workflows
🧵 👇

July 22, 2025 at 8:15 PM
#MistralAI Document #AI: Advanced #OCR solution for complex document processing 📄
📺 www.youtube.com/watch?v=yrx...
🔧 Fine-tuned #VisionLanguageModel specifically designed for document understanding beyond traditional #OCR limitations that plague most business workflows
🧵 👇
📺 www.youtube.com/watch?v=yrx...
🔧 Fine-tuned #VisionLanguageModel specifically designed for document understanding beyond traditional #OCR limitations that plague most business workflows
🧵 👇

A Pan-Organ Vision-Language Model for Generalizable 3D CT Representations
Beeche, C. A., Chen, T. et al.
Paper
Details
#3DCTRepresentations #VisionLanguageModel #MedicalImagingInnovation
Beeche, C. A., Chen, T. et al.
Paper
Details
#3DCTRepresentations #VisionLanguageModel #MedicalImagingInnovation
July 4, 2025 at 9:01 AM
A Pan-Organ Vision-Language Model for Generalizable 3D CT Representations
Beeche, C. A., Chen, T. et al.
Paper
Details
#3DCTRepresentations #VisionLanguageModel #MedicalImagingInnovation
Beeche, C. A., Chen, T. et al.
Paper
Details
#3DCTRepresentations #VisionLanguageModel #MedicalImagingInnovation

HiViS cuts the drafter’s prefill sequence to just 0.7%‑1.3% of the original input, delivering up to 2.65× faster inference without quality loss in multimodal AI. Read more: https://getnews.me/hivis-boosts-vision-language-model-speed-with-visual-token-hiding/ #hivis #visionlanguagemodel

September 30, 2025 at 3:59 PM
HiViS cuts the drafter’s prefill sequence to just 0.7%‑1.3% of the original input, delivering up to 2.65× faster inference without quality loss in multimodal AI. Read more: https://getnews.me/hivis-boosts-vision-language-model-speed-with-visual-token-hiding/ #hivis #visionlanguagemodel
Get familiar with the open-vocabulary segmentation problem, where the aim is to segment images into masks associated with unseen semantic categories. #visionlanguagemodel

Defining Open-Vocabulary Segmentation: Problem Setup, Baseline, and the Uni-OVSeg Framework
hackernoon.com
November 12, 2024 at 10:27 PM
Get familiar with the open-vocabulary segmentation problem, where the aim is to segment images into masks associated with unseen semantic categories. #visionlanguagemodel

Google DeepMind’s PaliGemma: A Small But Mighty Open-Source Vision-Language Model.
See here - techchilli.com/news/google-...
#GoogleDeepMind #PaliGemma #VisionLanguageModel #AI #TechInnovation #OpenSource #MachineLearning #AIEfficiency #TechTrends #FutureOfAI #ArtificialIntelligence
See here - techchilli.com/news/google-...
#GoogleDeepMind #PaliGemma #VisionLanguageModel #AI #TechInnovation #OpenSource #MachineLearning #AIEfficiency #TechTrends #FutureOfAI #ArtificialIntelligence

July 14, 2024 at 4:07 PM
Google DeepMind’s PaliGemma: A Small But Mighty Open-Source Vision-Language Model.
See here - techchilli.com/news/google-...
#GoogleDeepMind #PaliGemma #VisionLanguageModel #AI #TechInnovation #OpenSource #MachineLearning #AIEfficiency #TechTrends #FutureOfAI #ArtificialIntelligence
See here - techchilli.com/news/google-...
#GoogleDeepMind #PaliGemma #VisionLanguageModel #AI #TechInnovation #OpenSource #MachineLearning #AIEfficiency #TechTrends #FutureOfAI #ArtificialIntelligence
Explore the evolution of segmentation techniques, from semantic to open-vocabulary segmentation, and the role of vision-language models in improving performance #visionlanguagemodel

The Future of Segmentation: Low-Cost Annotation Meets High Performance
hackernoon.com
November 12, 2024 at 10:27 PM
Explore the evolution of segmentation techniques, from semantic to open-vocabulary segmentation, and the role of vision-language models in improving performance #visionlanguagemodel

Can you ask questions about an image?
A 'Vision Language Model' links your question with the visual content of an image. It will generate a full response to your question.
#learnAI #VisionLanguageModel
A 'Vision Language Model' links your question with the visual content of an image. It will generate a full response to your question.
#learnAI #VisionLanguageModel

April 17, 2025 at 11:38 AM
Can you ask questions about an image?
A 'Vision Language Model' links your question with the visual content of an image. It will generate a full response to your question.
#learnAI #VisionLanguageModel
A 'Vision Language Model' links your question with the visual content of an image. It will generate a full response to your question.
#learnAI #VisionLanguageModel
The baseline for open-vocabulary segmentation uses image-text and image-mask pairs with the CLIP model for feature extraction. #visionlanguagemodel
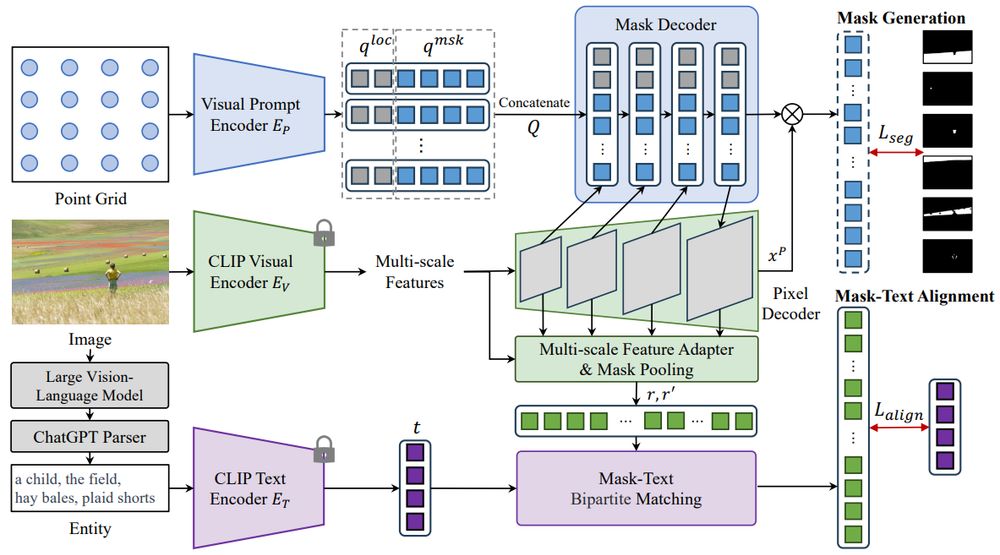
he Baseline and Uni-OVSeg Framework for Open-Vocabulary Segmentation
hackernoon.com
November 12, 2024 at 10:27 PM
The baseline for open-vocabulary segmentation uses image-text and image-mask pairs with the CLIP model for feature extraction. #visionlanguagemodel
Uni-OVSeg offers a breakthrough in open-vocabulary segmentation, reducing reliance on triplets and achieving superior performance, surpassing current models.
#visionlanguagemodel
#visionlanguagemodel

Uni-OVSeg: Weakly-Supervised Open-Vocabulary Segmentation with Cutting-Edge Performance
hackernoon.com
November 12, 2024 at 10:27 PM
Uni-OVSeg offers a breakthrough in open-vocabulary segmentation, reducing reliance on triplets and achieving superior performance, surpassing current models.
#visionlanguagemodel
#visionlanguagemodel

Pour essayer Qwen2.5-VL :
1. Installer Ollama https://ollama.com/download
2. Télécharger/lancer le modèle : ollama run qwen2.5vl:7b
3. Exemple de prompt : Describe this picture /path/to/file.png
#opensource #vlm #llm #visionlanguagemodel
1. Installer Ollama https://ollama.com/download
2. Télécharger/lancer le modèle : ollama run qwen2.5vl:7b
3. Exemple de prompt : Describe this picture /path/to/file.png
#opensource #vlm #llm #visionlanguagemodel

Download Ollama on macOS
Download Ollama for macOS
ollama.com
May 26, 2025 at 7:28 AM
Pour essayer Qwen2.5-VL :
1. Installer Ollama https://ollama.com/download
2. Télécharger/lancer le modèle : ollama run qwen2.5vl:7b
3. Exemple de prompt : Describe this picture /path/to/file.png
#opensource #vlm #llm #visionlanguagemodel
1. Installer Ollama https://ollama.com/download
2. Télécharger/lancer le modèle : ollama run qwen2.5vl:7b
3. Exemple de prompt : Describe this picture /path/to/file.png
#opensource #vlm #llm #visionlanguagemodel
Uni-OVSeg outperforms weakly-supervised and fully-supervised methods in open-vocabulary segmentation, showing superior results on datasets like PASCAL and COCO. #visionlanguagemodel
Uni-OVSeg Outperforms Weakly-Supervised and Fully-Supervised Methods in Open-Vocabulary Segmentation
hackernoon.com
November 12, 2024 at 10:27 PM
Uni-OVSeg outperforms weakly-supervised and fully-supervised methods in open-vocabulary segmentation, showing superior results on datasets like PASCAL and COCO. #visionlanguagemodel
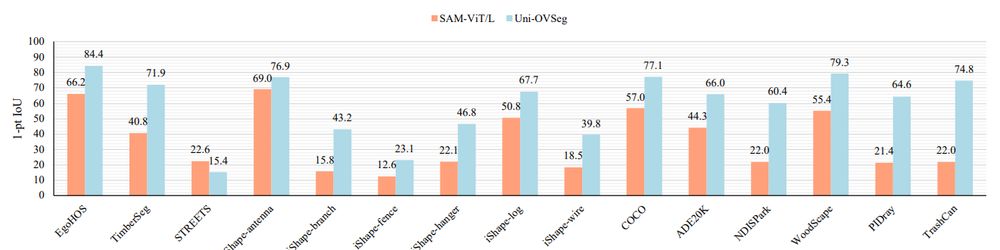
This evaluation explores promptable segmentation using uniform point grids and ground-truth bounding boxes across various datasets. #visionlanguagemodel

Evaluating Promptable Segmentation with Uniform Point Grids and Bounding Boxes on Diverse Datasets
hackernoon.com
November 13, 2024 at 5:00 PM
This evaluation explores promptable segmentation using uniform point grids and ground-truth bounding boxes across various datasets. #visionlanguagemodel