



Zhaofeng Lin
@zhaofenglin.bsky.social
PhD student @Trinity College Dublin | Multimodal speech recognition
https://chaufanglin.github.io/
https://chaufanglin.github.io/
Results show Auto-AVSR may rely more on audio, with a weaker correlation between MaFI scores and IWERs in AV mode.
In contrast, AVEC shows a stronger use of visual information, with a significant negative correlation, especially in noisy conditions.
[7/8] 🧵
In contrast, AVEC shows a stronger use of visual information, with a significant negative correlation, especially in noisy conditions.
[7/8] 🧵

April 1, 2025 at 11:18 AM
Results show Auto-AVSR may rely more on audio, with a weaker correlation between MaFI scores and IWERs in AV mode.
In contrast, AVEC shows a stronger use of visual information, with a significant negative correlation, especially in noisy conditions.
[7/8] 🧵
In contrast, AVEC shows a stronger use of visual information, with a significant negative correlation, especially in noisy conditions.
[7/8] 🧵
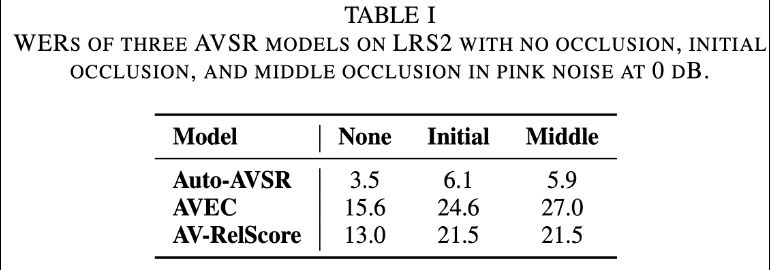
Occlusion tests reveal AVSR models rely differently on visual segments.
Auto-AVSR & AV-RelScore are equally affected by initial & middle occlusions, while AVEC is more impacted by middle occlusion.
Unlike humans, AVSR models do not depend on initial visual cues.
[5/8] 🧵
Auto-AVSR & AV-RelScore are equally affected by initial & middle occlusions, while AVEC is more impacted by middle occlusion.
Unlike humans, AVSR models do not depend on initial visual cues.
[5/8] 🧵
April 1, 2025 at 11:17 AM
Occlusion tests reveal AVSR models rely differently on visual segments.
Auto-AVSR & AV-RelScore are equally affected by initial & middle occlusions, while AVEC is more impacted by middle occlusion.
Unlike humans, AVSR models do not depend on initial visual cues.
[5/8] 🧵
Auto-AVSR & AV-RelScore are equally affected by initial & middle occlusions, while AVEC is more impacted by middle occlusion.
Unlike humans, AVSR models do not depend on initial visual cues.
[5/8] 🧵
First, we revisit *effective SNR gain* - measured by the difference in SNR at which the AVSR WER equals the reference WER for audio-only recognition at 0 dB.
This metric quantifies the benefit of the visual modality in reducing WER compared to the audio-only system. [3/n] 🧵
This metric quantifies the benefit of the visual modality in reducing WER compared to the audio-only system. [3/n] 🧵

April 1, 2025 at 11:16 AM
First, we revisit *effective SNR gain* - measured by the difference in SNR at which the AVSR WER equals the reference WER for audio-only recognition at 0 dB.
This metric quantifies the benefit of the visual modality in reducing WER compared to the audio-only system. [3/n] 🧵
This metric quantifies the benefit of the visual modality in reducing WER compared to the audio-only system. [3/n] 🧵