



Reposted by Tim Vieira

My paper "Tokenization as Finite-State Transduction" was accepted to Computational Linguistics.
This was my final PhD degree requirement :)
The goal was to unify the major tokenization algorithms under a finite-state automaton framework. For example, by encoding a BPE tokenizer as a transducer.
This was my final PhD degree requirement :)
The goal was to unify the major tokenization algorithms under a finite-state automaton framework. For example, by encoding a BPE tokenizer as a transducer.

August 15, 2025 at 7:25 AM
My paper "Tokenization as Finite-State Transduction" was accepted to Computational Linguistics.
This was my final PhD degree requirement :)
The goal was to unify the major tokenization algorithms under a finite-state automaton framework. For example, by encoding a BPE tokenizer as a transducer.
This was my final PhD degree requirement :)
The goal was to unify the major tokenization algorithms under a finite-state automaton framework. For example, by encoding a BPE tokenizer as a transducer.
Reposted by Tim Vieira

Many LM applications may be formulated as text generation conditional on some (Boolean) constraint.
Generate a…
- Python program that passes a test suite.
- PDDL plan that satisfies a goal.
- CoT trajectory that yields a positive reward.
The list goes on…
How can we efficiently satisfy these? 🧵👇
Generate a…
- Python program that passes a test suite.
- PDDL plan that satisfies a goal.
- CoT trajectory that yields a positive reward.
The list goes on…
How can we efficiently satisfy these? 🧵👇
May 13, 2025 at 2:22 PM
Many LM applications may be formulated as text generation conditional on some (Boolean) constraint.
Generate a…
- Python program that passes a test suite.
- PDDL plan that satisfies a goal.
- CoT trajectory that yields a positive reward.
The list goes on…
How can we efficiently satisfy these? 🧵👇
Generate a…
- Python program that passes a test suite.
- PDDL plan that satisfies a goal.
- CoT trajectory that yields a positive reward.
The list goes on…
How can we efficiently satisfy these? 🧵👇
Reposted by Tim Vieira

Current KL estimation practices in RLHF can generate high variance and even negative values! We propose a provably better estimator that only takes a few lines of code to implement.🧵👇
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb

May 6, 2025 at 2:59 PM
Current KL estimation practices in RLHF can generate high variance and even negative values! We propose a provably better estimator that only takes a few lines of code to implement.🧵👇
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb
w/ @xtimv.bsky.social and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb
Reposted by Tim Vieira

#ICLR2025 Oral
How can we control LMs using diverse signals such as static analyses, test cases, and simulations?
In our paper “Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo” (w/ @benlipkin.bsky.social,
@alexlew.bsky.social, @xtimv.bsky.social) we:
How can we control LMs using diverse signals such as static analyses, test cases, and simulations?
In our paper “Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo” (w/ @benlipkin.bsky.social,
@alexlew.bsky.social, @xtimv.bsky.social) we:
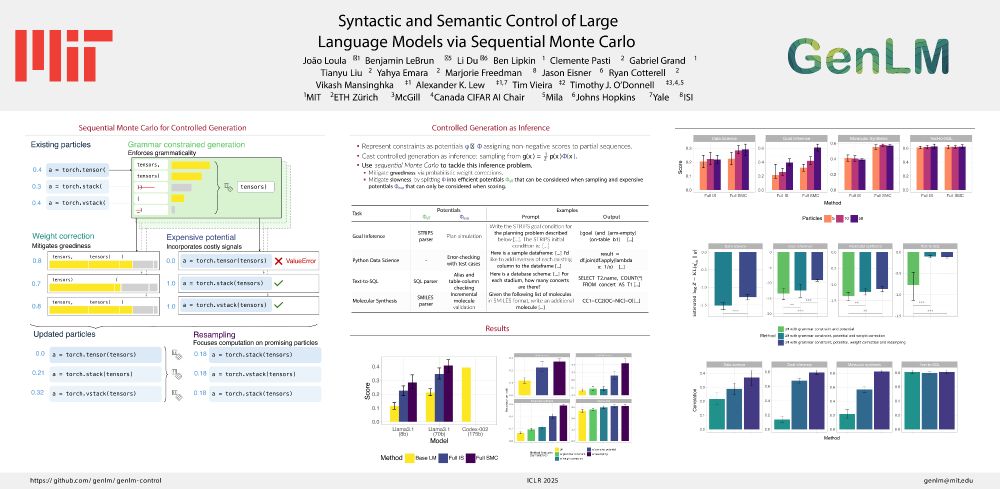
April 25, 2025 at 7:33 PM
#ICLR2025 Oral
How can we control LMs using diverse signals such as static analyses, test cases, and simulations?
In our paper “Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo” (w/ @benlipkin.bsky.social,
@alexlew.bsky.social, @xtimv.bsky.social) we:
How can we control LMs using diverse signals such as static analyses, test cases, and simulations?
In our paper “Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo” (w/ @benlipkin.bsky.social,
@alexlew.bsky.social, @xtimv.bsky.social) we:
Reposted by Tim Vieira
New preprint on controlled generation from LMs!
I'll be presenting at NENLP tomorrow 12:50-2:00pm
Longer thread coming soon :)
I'll be presenting at NENLP tomorrow 12:50-2:00pm
Longer thread coming soon :)

April 10, 2025 at 7:19 PM
New preprint on controlled generation from LMs!
I'll be presenting at NENLP tomorrow 12:50-2:00pm
Longer thread coming soon :)
I'll be presenting at NENLP tomorrow 12:50-2:00pm
Longer thread coming soon :)
Reposted by Tim Vieira
Tokenization is an often-overlooked aspect of modern #NLP, but it’s experiencing a resurgence — thanks in large part to @karpathy.bsky.social and his classic tweet:
x.com/karpathy/sta...
Come hang out with us and let's fix these problems!
x.com/karpathy/sta...
Come hang out with us and let's fix these problems!

February 10, 2025 at 4:26 PM
Tokenization is an often-overlooked aspect of modern #NLP, but it’s experiencing a resurgence — thanks in large part to @karpathy.bsky.social and his classic tweet:
x.com/karpathy/sta...
Come hang out with us and let's fix these problems!
x.com/karpathy/sta...
Come hang out with us and let's fix these problems!
Reposted by Tim Vieira
Today we are launching a server dedicated to Tokenization research! Come join us!
discord.gg/CDJhnSvU
discord.gg/CDJhnSvU
Join the Token ##ization Discord Server!
Check out the Token ##ization community on Discord - hang out with 24 other members and enjoy free voice and text chat.
discord.gg
February 10, 2025 at 4:26 PM
Today we are launching a server dedicated to Tokenization research! Come join us!
discord.gg/CDJhnSvU
discord.gg/CDJhnSvU
Reposted by Tim Vieira

@xtimv.bsky.social and I were just discussing this interesting comment in the DeepSeek paper introducing GRPO: a different way of setting up the KL loss.
It's a little hard to reason about what this does to the objective. 1/
It's a little hard to reason about what this does to the objective. 1/

February 10, 2025 at 4:32 AM
@xtimv.bsky.social and I were just discussing this interesting comment in the DeepSeek paper introducing GRPO: a different way of setting up the KL loss.
It's a little hard to reason about what this does to the objective. 1/
It's a little hard to reason about what this does to the objective. 1/
Reposted by Tim Vieira

I made a starter pack for people in NLP working in the area of tokenization. Let me know if you'd like to be added
go.bsky.app/8P9ftjL
go.bsky.app/8P9ftjL
December 20, 2024 at 6:37 PM
I made a starter pack for people in NLP working in the area of tokenization. Let me know if you'd like to be added
go.bsky.app/8P9ftjL
go.bsky.app/8P9ftjL
Reposted by Tim Vieira

It's ready! 💫
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
So far the blog post draft is winning the distraction battle. Prepare for a very long and opinionated update about all the new tools and apps I’ve been using for work.
Flight prep for someone who hates flying:
- Switch with Nine Sols loaded
- iPad with Black Doves loaded
- laptop with data, python notebook, blog post draft loaded
- silk eye mask
- REI inflatable neck pillow
- vitamin C juice
- Journey to the East by Hermann Hesse
- compression socks
- many snacks
- Switch with Nine Sols loaded
- iPad with Black Doves loaded
- laptop with data, python notebook, blog post draft loaded
- silk eye mask
- REI inflatable neck pillow
- vitamin C juice
- Journey to the East by Hermann Hesse
- compression socks
- many snacks
December 31, 2024 at 5:38 AM
It's ready! 💫
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
Reposted by Tim Vieira

hi everyone!! let's try this optimal transport again 🙃
December 5, 2024 at 12:58 PM
hi everyone!! let's try this optimal transport again 🙃
Reposted by Tim Vieira

Also: you can also use variables (or expressions?!) for the formatting information! #Python is cool...
More details and explanation at fstring.help
More details and explanation at fstring.help

November 21, 2024 at 5:50 PM
Also: you can also use variables (or expressions?!) for the formatting information! #Python is cool...
More details and explanation at fstring.help
More details and explanation at fstring.help
Reposted by Tim Vieira
Surprisal of title beginning with 'O'? 3.22
Surprisal of 'o' following 'Treatment '? 0.11
Surprisal that title includes surprisal of each title character? Priceless [...I did not know titles could do this]
Surprisal of 'o' following 'Treatment '? 0.11
Surprisal that title includes surprisal of each title character? Priceless [...I did not know titles could do this]

November 21, 2024 at 4:06 PM
Surprisal of title beginning with 'O'? 3.22
Surprisal of 'o' following 'Treatment '? 0.11
Surprisal that title includes surprisal of each title character? Priceless [...I did not know titles could do this]
Surprisal of 'o' following 'Treatment '? 0.11
Surprisal that title includes surprisal of each title character? Priceless [...I did not know titles could do this]
Reposted by Tim Vieira

Happy to share our work "Counterfactual Generation from Language Models" with @AnejSvete, @vesteinns, and Ryan Cotterell! We tackle generating true counterfactual strings from LMs after interventions and introduce a simple algorithm for it. (1/7) arxiv.org/pdf/2411.07180

November 12, 2024 at 4:00 PM
Happy to share our work "Counterfactual Generation from Language Models" with @AnejSvete, @vesteinns, and Ryan Cotterell! We tackle generating true counterfactual strings from LMs after interventions and introduce a simple algorithm for it. (1/7) arxiv.org/pdf/2411.07180
Reposted by Tim Vieira

Variational approximation with Gaussian mixtures is looking cute! So here it's just gradient descent on K(q||p) for optimising the mixtures means & covariances & weights...
@lacerbi.bsky.social
@lacerbi.bsky.social
November 20, 2024 at 6:23 PM
Variational approximation with Gaussian mixtures is looking cute! So here it's just gradient descent on K(q||p) for optimising the mixtures means & covariances & weights...
@lacerbi.bsky.social
@lacerbi.bsky.social
Reposted by Tim Vieira
Gaussian approximation of a target distribution: mean-field versus full-covariance! Below shows a simple gradient descent on KL(q||p)
November 20, 2024 at 8:51 AM
Gaussian approximation of a target distribution: mean-field versus full-covariance! Below shows a simple gradient descent on KL(q||p)