



Costa Huang
@vwxyzjn.bsky.social
RL + LLM @ai2.bsky.social; main dev of https://cleanrl.dev/
This is all. Enjoy the new model 😆
May 1, 2025 at 1:21 PM
This is all. Enjoy the new model 😆
One fun thing is that our model outperformed qwen by almost ~26 points in IFEval. What's going on? We built some nice visualization tools, finding out that basically our model can follow the instructions like "write without a comma" well.
May 1, 2025 at 1:21 PM
One fun thing is that our model outperformed qwen by almost ~26 points in IFEval. What's going on? We built some nice visualization tools, finding out that basically our model can follow the instructions like "write without a comma" well.
Our 1B model achieves impressive performance. See our official tweet for more details!
bsky.app/profile/ai2....
bsky.app/profile/ai2....

We're excited to round out the OLMo 2 family with its smallest member, OLMo 2 1B, surpassing peer models like Gemma 3 1B or Llama 3.2 1B. The 1B model should enable rapid iteration for researchers, more local development, and a more complete picture of how our recipe scales.

May 1, 2025 at 1:21 PM
Our 1B model achieves impressive performance. See our official tweet for more details!
bsky.app/profile/ai2....
bsky.app/profile/ai2....
The model checkpoints are available in huggingface.co/collections/....
As always, we uploaded all the intermediate RL checkpoints
As always, we uploaded all the intermediate RL checkpoints

May 1, 2025 at 1:21 PM
The model checkpoints are available in huggingface.co/collections/....
As always, we uploaded all the intermediate RL checkpoints
As always, we uploaded all the intermediate RL checkpoints
We streamlined our release process to include the RLVR intermediate checkpoints as well. They are available in the revisions if you want to check it out.
See our updated collection here: huggingface.co/collections/...
See our updated collection here: huggingface.co/collections/...

March 13, 2025 at 7:19 PM
We streamlined our release process to include the RLVR intermediate checkpoints as well. They are available in the revisions if you want to check it out.
See our updated collection here: huggingface.co/collections/...
See our updated collection here: huggingface.co/collections/...
Finally, @hamishivi.bsky.social initially added the GRPO async RL script here: github.com/allenai/open.... We are battle-testing it and hope to share more soon!
https://github.com/allenai/open-instruct/blob/main/open_instruct/grpo_vllm_thread_ray_gtrl.py…
February 12, 2025 at 5:33 PM
Finally, @hamishivi.bsky.social initially added the GRPO async RL script here: github.com/allenai/open.... We are battle-testing it and hope to share more soon!
💾 I included the reproduction commands here:
github.com/allenai/open...
github.com/allenai/open...
github.com
February 12, 2025 at 5:33 PM
💾 I included the reproduction commands here:
github.com/allenai/open...
github.com/allenai/open...
📦Here is the trained model. The main recipe is basically the same, except we used a different RL algorithm, so we are just doing a minor release.
huggingface.co/allenai/Llam...
huggingface.co/allenai/Llam...
huggingface.co
February 12, 2025 at 5:33 PM
📦Here is the trained model. The main recipe is basically the same, except we used a different RL algorithm, so we are just doing a minor release.
huggingface.co/allenai/Llam...
huggingface.co/allenai/Llam...
🗡️ The training length is a confounder, but I did run a launch an ablation study on the same `allenai/RLVR-MATH` dataset, using almost identical hyperparams for PPO and GRPO:
The PPO's MATH score is more consistent with the Llama-3.1-Tulu-3-8B model, but GRPO got higher scores.
The PPO's MATH score is more consistent with the Llama-3.1-Tulu-3-8B model, but GRPO got higher scores.

February 12, 2025 at 5:33 PM
🗡️ The training length is a confounder, but I did run a launch an ablation study on the same `allenai/RLVR-MATH` dataset, using almost identical hyperparams for PPO and GRPO:
The PPO's MATH score is more consistent with the Llama-3.1-Tulu-3-8B model, but GRPO got higher scores.
The PPO's MATH score is more consistent with the Llama-3.1-Tulu-3-8B model, but GRPO got higher scores.
📈 Below is the training curve. I think part of the performance gain also comes from training RL for longer

February 12, 2025 at 5:33 PM
📈 Below is the training curve. I think part of the performance gain also comes from training RL for longer
🎆 @natolambert.bsky.social also updated this figure in our paper, for a better visualization :D

February 12, 2025 at 5:33 PM
🎆 @natolambert.bsky.social also updated this figure in our paper, for a better visualization :D
🎁 We applied the same RLVR dataset (allenai/RLVR-GSM-MATH-IF-Mixed-Constraints) using our new GRPO training script - the trained model checkpoints are better!

February 12, 2025 at 5:33 PM
🎁 We applied the same RLVR dataset (allenai/RLVR-GSM-MATH-IF-Mixed-Constraints) using our new GRPO training script - the trained model checkpoints are better!
Thanks @soldni.bsky.social for the better OLMoE base model and for pulling everything through,
@ljvmiranda.bsky.social for on-policy preferences, and many others for coordinating and making the release happen 💪
@ljvmiranda.bsky.social for on-policy preferences, and many others for coordinating and making the release happen 💪
February 11, 2025 at 3:30 PM
Thanks @soldni.bsky.social for the better OLMoE base model and for pulling everything through,
@ljvmiranda.bsky.social for on-policy preferences, and many others for coordinating and making the release happen 💪
@ljvmiranda.bsky.social for on-policy preferences, and many others for coordinating and making the release happen 💪
For a cleaned-up version, please refer to Tulu 3 repro commands github.com/allenai/open...
github.com
February 11, 2025 at 3:30 PM
For a cleaned-up version, please refer to Tulu 3 repro commands github.com/allenai/open...
For interested folks, I also included the script I used to launch all the SFT / DPO / RLVR experiments here github.com/allenai/open.... Not cleaned up, but hope it shows some traces of the end-to-end workflow.
github.com
February 11, 2025 at 3:30 PM
For interested folks, I also included the script I used to launch all the SFT / DPO / RLVR experiments here github.com/allenai/open.... Not cleaned up, but hope it shows some traces of the end-to-end workflow.
All of our research artifacts are fully open source and released. Check out our HF collection:
huggingface.co/collections/...
huggingface.co/collections/...
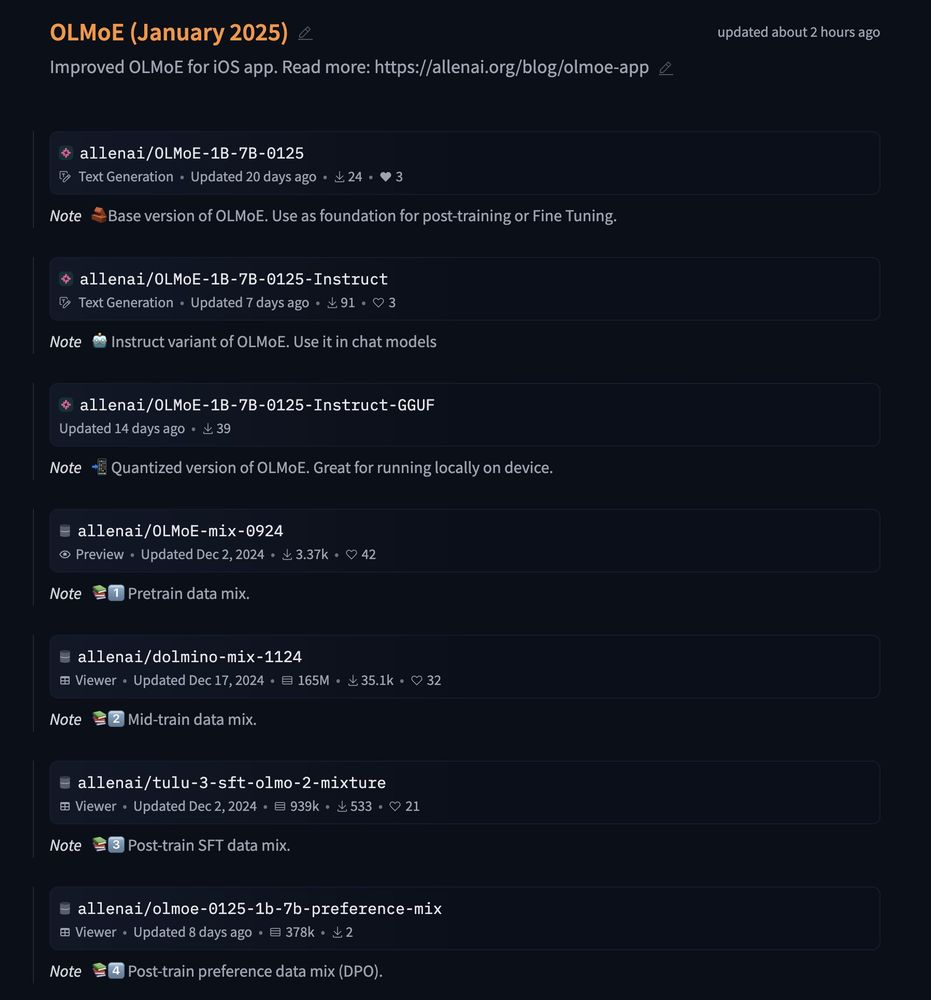
February 11, 2025 at 3:30 PM
All of our research artifacts are fully open source and released. Check out our HF collection:
huggingface.co/collections/...
huggingface.co/collections/...
We hope you love this new OLMoE model! Download our app at apps.apple.com/us/app/ai2-o...

Ai2 OLMoE
Our app is intended to help researchers better explore how to make on-device intelligence better and to enable developers to quickly prototype new AI experiences – all with no cloud connectivity requ...
apps.apple.com
February 11, 2025 at 3:30 PM
We hope you love this new OLMoE model! Download our app at apps.apple.com/us/app/ai2-o...
This is how our new allenai/OLMoE-1B-7B-0125-Instruct models compare with the existing allenai/OLMoE-1B-7B-0924-Instruct checkpoint :)
Huge gains on GSM8K, DROP, MATH, and alpaca eval.
Huge gains on GSM8K, DROP, MATH, and alpaca eval.

February 11, 2025 at 3:30 PM
This is how our new allenai/OLMoE-1B-7B-0125-Instruct models compare with the existing allenai/OLMoE-1B-7B-0924-Instruct checkpoint :)
Huge gains on GSM8K, DROP, MATH, and alpaca eval.
Huge gains on GSM8K, DROP, MATH, and alpaca eval.
We found the RLVR + GSM8K recipe to work robustly, and the scores kept going up

February 11, 2025 at 3:30 PM
We found the RLVR + GSM8K recipe to work robustly, and the scores kept going up
So maybe using it in the loss directly instead of in the rewards changes certain things? I am not sure.
Anyway just thought the snippet is interesting to share.
Anyway just thought the snippet is interesting to share.
January 31, 2025 at 3:21 PM
So maybe using it in the loss directly instead of in the rewards changes certain things? I am not sure.
Anyway just thought the snippet is interesting to share.
Anyway just thought the snippet is interesting to share.