



@vinhtong.bsky.social
I'll be giving an oral talk at #ICLR2025!
🗓 Session 1C — 🕦 11:30 AM SGT.
Title: Learning to Discretize Denoising Diffusion ODEs.
Come by if you're into #GenerativeAI / #DiffusionModels
🗓 Session 1C — 🕦 11:30 AM SGT.
Title: Learning to Discretize Denoising Diffusion ODEs.
Come by if you're into #GenerativeAI / #DiffusionModels

April 23, 2025 at 10:09 PM
I'll be giving an oral talk at #ICLR2025!
🗓 Session 1C — 🕦 11:30 AM SGT.
Title: Learning to Discretize Denoising Diffusion ODEs.
Come by if you're into #GenerativeAI / #DiffusionModels
🗓 Session 1C — 🕦 11:30 AM SGT.
Title: Learning to Discretize Denoising Diffusion ODEs.
Come by if you're into #GenerativeAI / #DiffusionModels
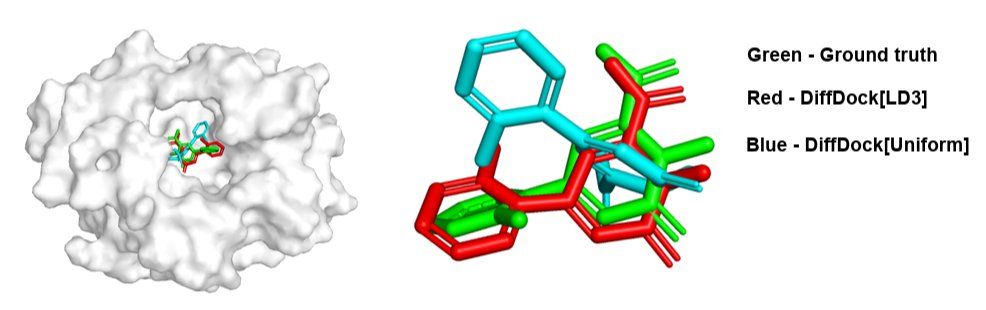
[9/n] Beyond Image Generation
LD3 can be applied to diffusion models in other domains, such as molecular docking.
LD3 can be applied to diffusion models in other domains, such as molecular docking.
February 13, 2025 at 8:31 AM
[9/n] Beyond Image Generation
LD3 can be applied to diffusion models in other domains, such as molecular docking.
LD3 can be applied to diffusion models in other domains, such as molecular docking.
[8/n] LD3 is fast
LD3 can be trained on a single GPU in under one hour. For smaller datasets like CIFAR-10, training can be completed in less than 6 minutes.
LD3 can be trained on a single GPU in under one hour. For smaller datasets like CIFAR-10, training can be completed in less than 6 minutes.

February 13, 2025 at 8:31 AM
[8/n] LD3 is fast
LD3 can be trained on a single GPU in under one hour. For smaller datasets like CIFAR-10, training can be completed in less than 6 minutes.
LD3 can be trained on a single GPU in under one hour. For smaller datasets like CIFAR-10, training can be completed in less than 6 minutes.
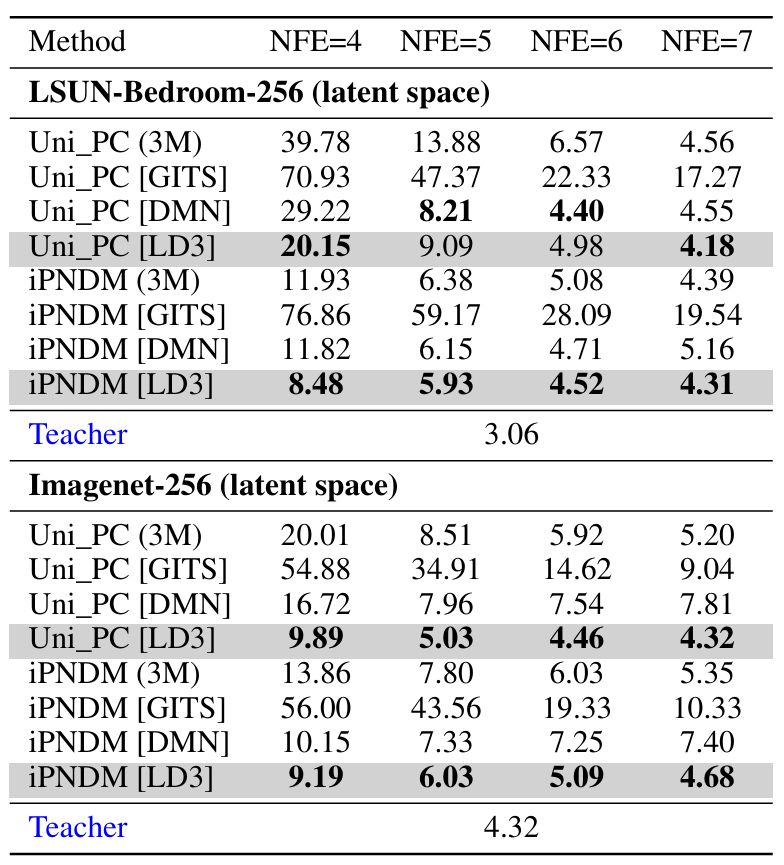
[7/n]
LD3 significantly improves sample quality.
LD3 significantly improves sample quality.

February 13, 2025 at 8:31 AM
[7/n]
LD3 significantly improves sample quality.
LD3 significantly improves sample quality.
[6/n]
This surrogate loss is theoretically close to the original distillation objective, leading to better convergence and avoiding underfitting.
This surrogate loss is theoretically close to the original distillation objective, leading to better convergence and avoiding underfitting.

February 13, 2025 at 8:31 AM
[6/n]
This surrogate loss is theoretically close to the original distillation objective, leading to better convergence and avoiding underfitting.
This surrogate loss is theoretically close to the original distillation objective, leading to better convergence and avoiding underfitting.
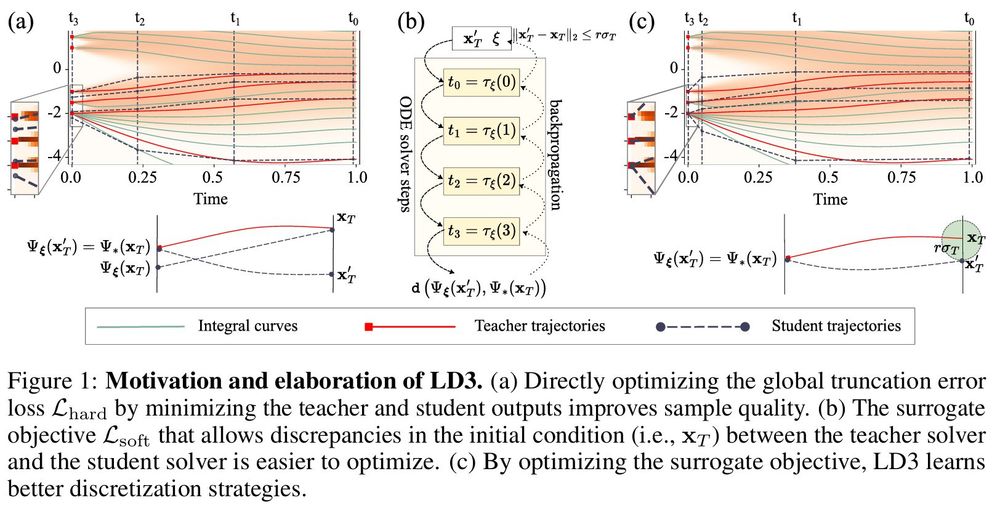
[5/n] Soft constraint
A potential problem with the student model is its limited capacity. To address this, we propose a soft surrogate loss, simplifying the student's optimization task.
A potential problem with the student model is its limited capacity. To address this, we propose a soft surrogate loss, simplifying the student's optimization task.
February 13, 2025 at 8:31 AM
[5/n] Soft constraint
A potential problem with the student model is its limited capacity. To address this, we propose a soft surrogate loss, simplifying the student's optimization task.
A potential problem with the student model is its limited capacity. To address this, we propose a soft surrogate loss, simplifying the student's optimization task.
🚀 Exciting news! Our paper "Learning to Discretize Diffusion ODEs" has been accepted as an Oral at #ICLR2025! 🎉
[1/n]
We propose LD3, a lightweight framework that learns the optimal time discretization for sampling from pre-trained Diffusion Probabilistic Models (DPMs).
[1/n]
We propose LD3, a lightweight framework that learns the optimal time discretization for sampling from pre-trained Diffusion Probabilistic Models (DPMs).

February 13, 2025 at 8:31 AM
🚀 Exciting news! Our paper "Learning to Discretize Diffusion ODEs" has been accepted as an Oral at #ICLR2025! 🎉
[1/n]
We propose LD3, a lightweight framework that learns the optimal time discretization for sampling from pre-trained Diffusion Probabilistic Models (DPMs).
[1/n]
We propose LD3, a lightweight framework that learns the optimal time discretization for sampling from pre-trained Diffusion Probabilistic Models (DPMs).