



Tiancheng Hu
@tiancheng.bsky.social
PhD student @CambridgeLTL; Previously @DLAB @EPFL; Interested in NLP and CSS. Apple Scholar, Gates Scholar.
Better calibration has benefits beyond accuracy scores. It helps reduce "mode collapse" in generation tasks, leading to more diverse generations (and higher utility too), as measured on NoveltyBench. It improves model performance on group-level simulation tasks too! (7/8)

October 30, 2025 at 5:00 PM
Better calibration has benefits beyond accuracy scores. It helps reduce "mode collapse" in generation tasks, leading to more diverse generations (and higher utility too), as measured on NoveltyBench. It improves model performance on group-level simulation tasks too! (7/8)
And it gets better with scale! 📈
The benefits of merging, both the accuracy boost and the stability of the "sweet spot", become even more pronounced in larger, more capable models. This echoes prior work which shows merging bigger models are more effective and stable. (6/8)
The benefits of merging, both the accuracy boost and the stability of the "sweet spot", become even more pronounced in larger, more capable models. This echoes prior work which shows merging bigger models are more effective and stable. (6/8)

October 30, 2025 at 5:00 PM
And it gets better with scale! 📈
The benefits of merging, both the accuracy boost and the stability of the "sweet spot", become even more pronounced in larger, more capable models. This echoes prior work which shows merging bigger models are more effective and stable. (6/8)
The benefits of merging, both the accuracy boost and the stability of the "sweet spot", become even more pronounced in larger, more capable models. This echoes prior work which shows merging bigger models are more effective and stable. (6/8)
The Pareto-superior frontier is a general phenomenon we observe across model families (Gemma, Qwen), sizes, and datasets, where we can consistently find a better-balanced model. We show Qwen 2.5 results on BBH and MMLU-Pro below. (5/8)

October 30, 2025 at 5:00 PM
The Pareto-superior frontier is a general phenomenon we observe across model families (Gemma, Qwen), sizes, and datasets, where we can consistently find a better-balanced model. We show Qwen 2.5 results on BBH and MMLU-Pro below. (5/8)
It's NOT a zero-sum game between base and instruct.
We find a "sweet spot" merge that is Pareto-superior: it has HIGHER accuracy than both parents while substantially restoring the calibration lost during alignment. (4/8)
We find a "sweet spot" merge that is Pareto-superior: it has HIGHER accuracy than both parents while substantially restoring the calibration lost during alignment. (4/8)

October 30, 2025 at 5:00 PM
It's NOT a zero-sum game between base and instruct.
We find a "sweet spot" merge that is Pareto-superior: it has HIGHER accuracy than both parents while substantially restoring the calibration lost during alignment. (4/8)
We find a "sweet spot" merge that is Pareto-superior: it has HIGHER accuracy than both parents while substantially restoring the calibration lost during alignment. (4/8)
Our solution is simple and computationally cheap: model merging.
By interpolating between the well-calibrated base model and its capable but overconfident instruct counterpart, we create a continuous spectrum to navigate this trade-off. No retraining needed.
(3/8)
By interpolating between the well-calibrated base model and its capable but overconfident instruct counterpart, we create a continuous spectrum to navigate this trade-off. No retraining needed.
(3/8)

October 30, 2025 at 5:00 PM
Our solution is simple and computationally cheap: model merging.
By interpolating between the well-calibrated base model and its capable but overconfident instruct counterpart, we create a continuous spectrum to navigate this trade-off. No retraining needed.
(3/8)
By interpolating between the well-calibrated base model and its capable but overconfident instruct counterpart, we create a continuous spectrum to navigate this trade-off. No retraining needed.
(3/8)
Let's start by redefining the problem. We argue the "alignment tax" MUST include the severe loss of model calibration.
Instruction tuning doesn't just nudge performance; it wrecks calibration, causing a huge spike in overconfidence. (2/8)
Instruction tuning doesn't just nudge performance; it wrecks calibration, causing a huge spike in overconfidence. (2/8)

October 30, 2025 at 5:00 PM
Let's start by redefining the problem. We argue the "alignment tax" MUST include the severe loss of model calibration.
Instruction tuning doesn't just nudge performance; it wrecks calibration, causing a huge spike in overconfidence. (2/8)
Instruction tuning doesn't just nudge performance; it wrecks calibration, causing a huge spike in overconfidence. (2/8)
Instruction tuning unlocks incredible skills in LLMs, but at a cost: they become dangerously overconfident.
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
October 30, 2025 at 5:00 PM
Instruction tuning unlocks incredible skills in LLMs, but at a cost: they become dangerously overconfident.
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
Check out the paper and data for details!
Paper: arxiv.org/abs/2510.17516
Data: huggingface.co/datasets/pit...
Website: simbench.tiancheng.hu (9/9)
Paper: arxiv.org/abs/2510.17516
Data: huggingface.co/datasets/pit...
Website: simbench.tiancheng.hu (9/9)

October 28, 2025 at 4:54 PM
Check out the paper and data for details!
Paper: arxiv.org/abs/2510.17516
Data: huggingface.co/datasets/pit...
Website: simbench.tiancheng.hu (9/9)
Paper: arxiv.org/abs/2510.17516
Data: huggingface.co/datasets/pit...
Website: simbench.tiancheng.hu (9/9)
There’s also an alignment-simulation tradeoff:
Instruction-tuning (the process that makes LLMs helpful and safe) improves their ability to predict consensus opinions.
BUT, it actively harms their ability to predict diverse, pluralistic opinions where humans disagree. (5/9)
Instruction-tuning (the process that makes LLMs helpful and safe) improves their ability to predict consensus opinions.
BUT, it actively harms their ability to predict diverse, pluralistic opinions where humans disagree. (5/9)

October 28, 2025 at 4:54 PM
There’s also an alignment-simulation tradeoff:
Instruction-tuning (the process that makes LLMs helpful and safe) improves their ability to predict consensus opinions.
BUT, it actively harms their ability to predict diverse, pluralistic opinions where humans disagree. (5/9)
Instruction-tuning (the process that makes LLMs helpful and safe) improves their ability to predict consensus opinions.
BUT, it actively harms their ability to predict diverse, pluralistic opinions where humans disagree. (5/9)
We found a clear log-linear scaling trend.
Across the model families we could test, bigger models are consistently better simulators. Performance reliably increases with model size. This suggests that future, larger models hold the potential to become highly accurate simulators. (4/9)
Across the model families we could test, bigger models are consistently better simulators. Performance reliably increases with model size. This suggests that future, larger models hold the potential to become highly accurate simulators. (4/9)

October 28, 2025 at 4:54 PM
We found a clear log-linear scaling trend.
Across the model families we could test, bigger models are consistently better simulators. Performance reliably increases with model size. This suggests that future, larger models hold the potential to become highly accurate simulators. (4/9)
Across the model families we could test, bigger models are consistently better simulators. Performance reliably increases with model size. This suggests that future, larger models hold the potential to become highly accurate simulators. (4/9)
The best model we tested on release, Claude 3.7 Sonnet, scores just 40.8 out of 100. A lot of room for improvement for LLM social simulators! Interestingly, more test-time compute doesn’t help. This suggests that simulation requires a different type of reasoning than math / coding. (3/9)

October 28, 2025 at 4:54 PM
The best model we tested on release, Claude 3.7 Sonnet, scores just 40.8 out of 100. A lot of room for improvement for LLM social simulators! Interestingly, more test-time compute doesn’t help. This suggests that simulation requires a different type of reasoning than math / coding. (3/9)

Can AI simulate human behavior? 🧠
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
October 28, 2025 at 4:54 PM
Can AI simulate human behavior? 🧠
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
Working on LLM social simulation and need data?
Excited to announce our iNews paper is accepted to #ACL2025! 🥳 It's a large-scale dataset for predicting individualized affective responses to real-world, multimodal news.
Paper: arxiv.org/abs/2503.03335
Data: huggingface.co/datasets/pit...
Excited to announce our iNews paper is accepted to #ACL2025! 🥳 It's a large-scale dataset for predicting individualized affective responses to real-world, multimodal news.
Paper: arxiv.org/abs/2503.03335
Data: huggingface.co/datasets/pit...

July 9, 2025 at 3:44 PM
Working on LLM social simulation and need data?
Excited to announce our iNews paper is accepted to #ACL2025! 🥳 It's a large-scale dataset for predicting individualized affective responses to real-world, multimodal news.
Paper: arxiv.org/abs/2503.03335
Data: huggingface.co/datasets/pit...
Excited to announce our iNews paper is accepted to #ACL2025! 🥳 It's a large-scale dataset for predicting individualized affective responses to real-world, multimodal news.
Paper: arxiv.org/abs/2503.03335
Data: huggingface.co/datasets/pit...
Few-Shot:
• "Early ascent phenomenon": performance dips with few examples, then improves
• Persona info consistently helps, even at 32-shot (reaching 44.4% accuracy).
• Image few-shot prompting scales worse than text, despite zero-shot advantage. (7/8)
• "Early ascent phenomenon": performance dips with few examples, then improves
• Persona info consistently helps, even at 32-shot (reaching 44.4% accuracy).
• Image few-shot prompting scales worse than text, despite zero-shot advantage. (7/8)

March 10, 2025 at 4:47 PM
Few-Shot:
• "Early ascent phenomenon": performance dips with few examples, then improves
• Persona info consistently helps, even at 32-shot (reaching 44.4% accuracy).
• Image few-shot prompting scales worse than text, despite zero-shot advantage. (7/8)
• "Early ascent phenomenon": performance dips with few examples, then improves
• Persona info consistently helps, even at 32-shot (reaching 44.4% accuracy).
• Image few-shot prompting scales worse than text, despite zero-shot advantage. (7/8)
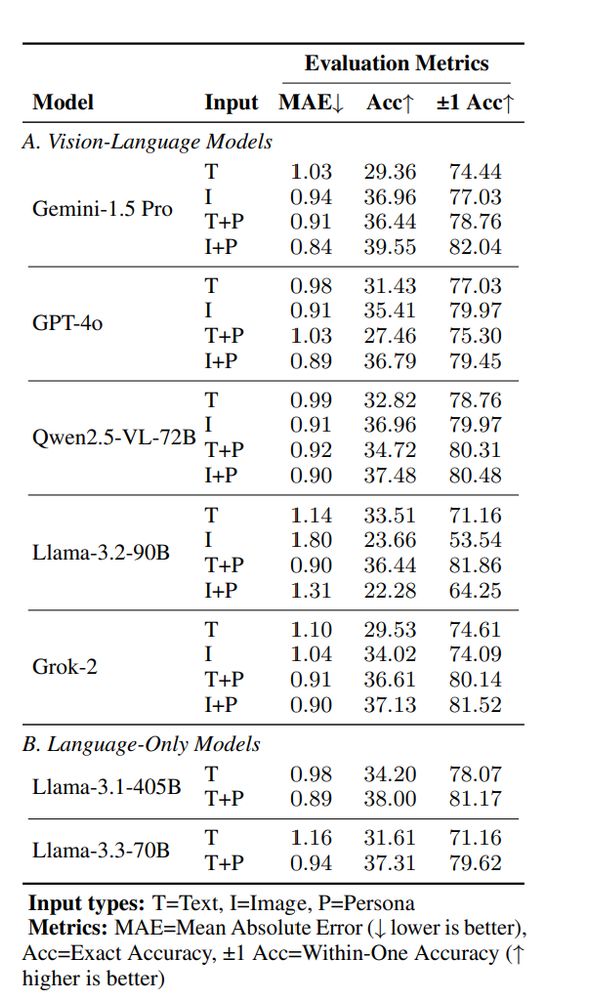
Zero-Shot LLM Prediction:
• Persona info boosts accuracy across models (up to 7% gain!).
• Image inputs generally outperform text inputs in zero-shot.
• Gemini 1.5 Pro + image + persona = best zero-shot performance (still only 40% accuracy though). (6/8)
• Persona info boosts accuracy across models (up to 7% gain!).
• Image inputs generally outperform text inputs in zero-shot.
• Gemini 1.5 Pro + image + persona = best zero-shot performance (still only 40% accuracy though). (6/8)
March 10, 2025 at 4:47 PM
Zero-Shot LLM Prediction:
• Persona info boosts accuracy across models (up to 7% gain!).
• Image inputs generally outperform text inputs in zero-shot.
• Gemini 1.5 Pro + image + persona = best zero-shot performance (still only 40% accuracy though). (6/8)
• Persona info boosts accuracy across models (up to 7% gain!).
• Image inputs generally outperform text inputs in zero-shot.
• Gemini 1.5 Pro + image + persona = best zero-shot performance (still only 40% accuracy though). (6/8)
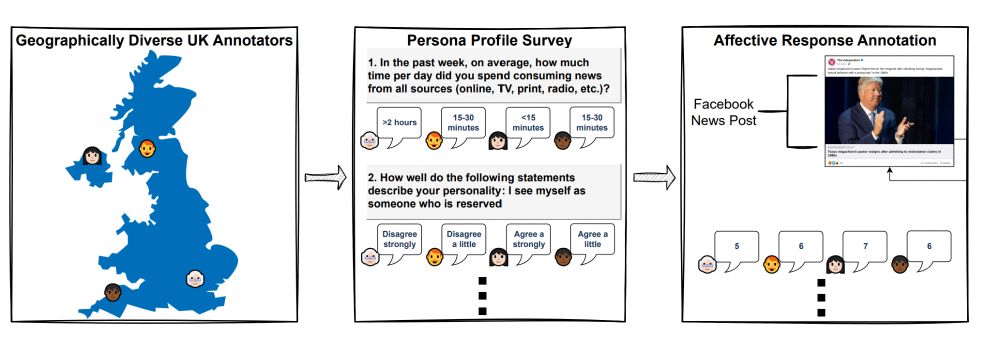
We're introducing iNews: a large-scale dataset capturing the inherent subjectivity of how people respond emotionally to real news content. 2,899 Facebook posts (screenshot so multimodal!) × 291 diverse annotators = rich, subjective affective data. (3/8)
March 10, 2025 at 4:47 PM
We're introducing iNews: a large-scale dataset capturing the inherent subjectivity of how people respond emotionally to real news content. 2,899 Facebook posts (screenshot so multimodal!) × 291 diverse annotators = rich, subjective affective data. (3/8)
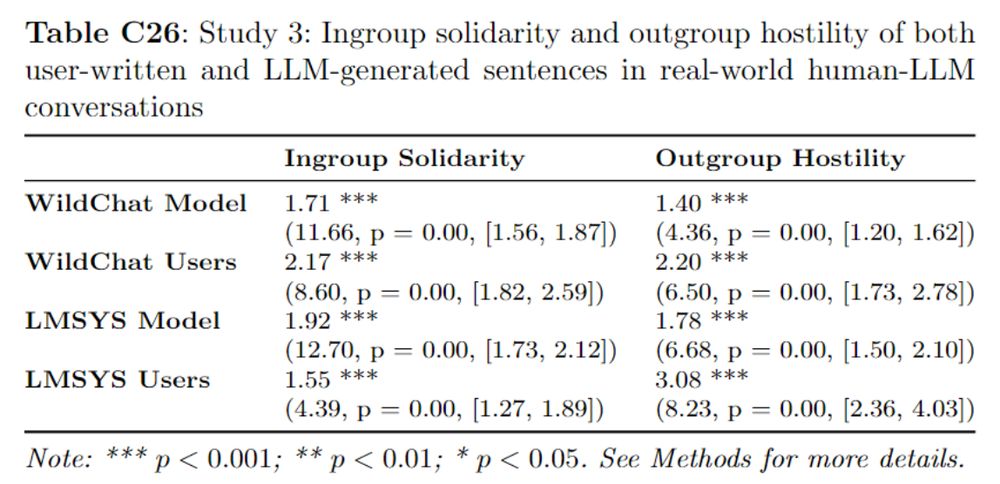
6/9: How do LLMs fare in real conversations? We looked at WildChat and LMSYS data and found that both users and LLMs here exhibit significant levels of ingroup and outgroup bias but actually users themselves displayed more bias than the models they interacted with!
December 12, 2024 at 10:39 PM
6/9: How do LLMs fare in real conversations? We looked at WildChat and LMSYS data and found that both users and LLMs here exhibit significant levels of ingroup and outgroup bias but actually users themselves displayed more bias than the models they interacted with!
5/9 But fear not: if we remove varying proportions of “biased” sentences and fine-tune models again, we could in fact greatly reduce the ingroup and outgroup bias, even when fine-tuning on an otherwise partisan twitter corpus.
December 12, 2024 at 10:39 PM
5/9 But fear not: if we remove varying proportions of “biased” sentences and fine-tune models again, we could in fact greatly reduce the ingroup and outgroup bias, even when fine-tuning on an otherwise partisan twitter corpus.
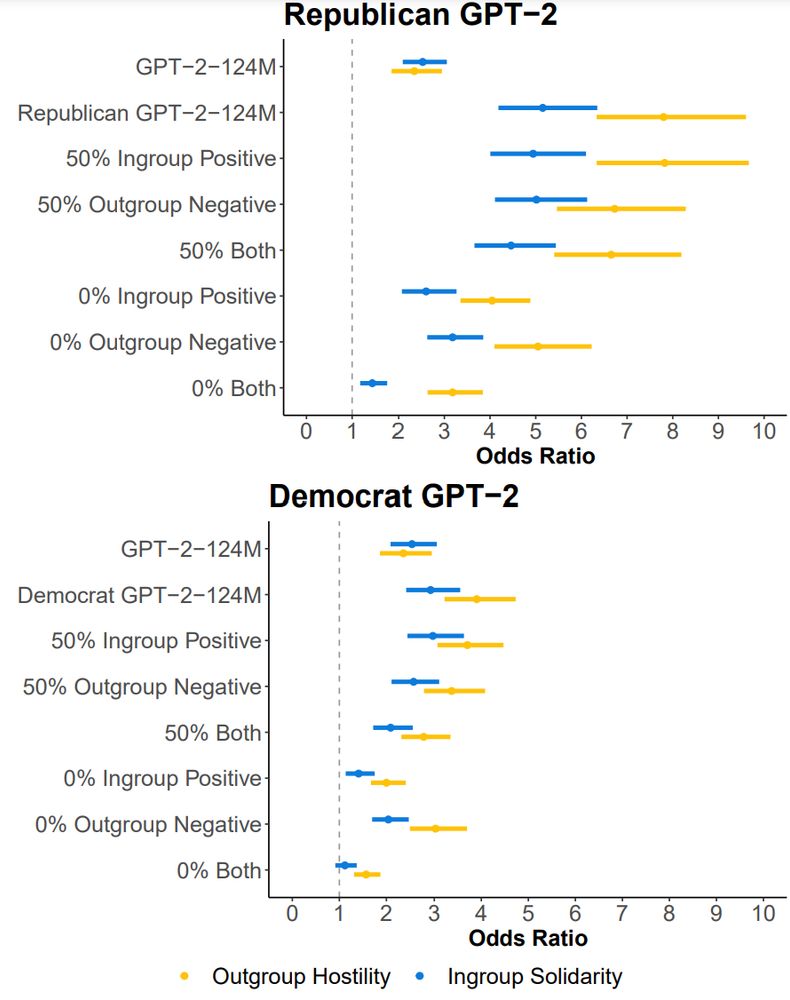
4/9🤔 Curious about the origins of these biases in LLMs? Is it the training data's fault? After fine-tuning on a U.S. partisan Twitter corpus, we saw a large increase in ingroup solidarity and an even larger increase in outgroup hostility.

December 12, 2024 at 10:39 PM
4/9🤔 Curious about the origins of these biases in LLMs? Is it the training data's fault? After fine-tuning on a U.S. partisan Twitter corpus, we saw a large increase in ingroup solidarity and an even larger increase in outgroup hostility.
3/9 Many LLMs show clear favoritism toward "ingroups" and negativity toward "outgroups" - just like humans! In fact, many models mirror the same statistical patterns of bias found in their pretraining data. Instruction/preference tuning reduce both ingroup and outgroup bias.

December 12, 2024 at 10:39 PM
3/9 Many LLMs show clear favoritism toward "ingroups" and negativity toward "outgroups" - just like humans! In fact, many models mirror the same statistical patterns of bias found in their pretraining data. Instruction/preference tuning reduce both ingroup and outgroup bias.
Such an amazing work in so many ways! Well done! Great to see convergent evidence that the more persona information you have about someone, the more accurate your simulation would be. aclanthology.org/2024.acl-lon...
Is there a scaling law for simulation based on persona detailedness?
Is there a scaling law for simulation based on persona detailedness?

November 19, 2024 at 8:50 AM
Such an amazing work in so many ways! Well done! Great to see convergent evidence that the more persona information you have about someone, the more accurate your simulation would be. aclanthology.org/2024.acl-lon...
Is there a scaling law for simulation based on persona detailedness?
Is there a scaling law for simulation based on persona detailedness?
🚨New Preprint: "Generative language models exhibit social identity biases" Did you know LLMs mirror human-like biases, showing human-levels of ingroup solidarity & outgroup hostility?
@profsanderlinden.bsky.social @steverathje.bsky.social
📄 arxiv.org/abs/2310.15819
@profsanderlinden.bsky.social @steverathje.bsky.social
📄 arxiv.org/abs/2310.15819


December 1, 2023 at 6:01 PM
🚨New Preprint: "Generative language models exhibit social identity biases" Did you know LLMs mirror human-like biases, showing human-levels of ingroup solidarity & outgroup hostility?
@profsanderlinden.bsky.social @steverathje.bsky.social
📄 arxiv.org/abs/2310.15819
@profsanderlinden.bsky.social @steverathje.bsky.social
📄 arxiv.org/abs/2310.15819