



Stanford NLP Group
@stanfordnlp.bsky.social
Computational Linguists—Natural Language—Machine Learning
Reposted by Stanford NLP Group

Life update! Excited to announce that I’ll be starting as an assistant professor at Cornell Info Sci in August 2026! I’ll be recruiting students this upcoming cycle!
An abundance of thanks to all my mentors and friends who helped make this possible!!
An abundance of thanks to all my mentors and friends who helped make this possible!!
April 24, 2025 at 2:03 AM
Life update! Excited to announce that I’ll be starting as an assistant professor at Cornell Info Sci in August 2026! I’ll be recruiting students this upcoming cycle!
An abundance of thanks to all my mentors and friends who helped make this possible!!
An abundance of thanks to all my mentors and friends who helped make this possible!!
Reposted by Stanford NLP Group

New ICLR blogpost! 🎉 We argue that understanding the impact of anthropomorphic AI is critical to understanding the impact of AI.

April 27, 2025 at 9:55 PM
New ICLR blogpost! 🎉 We argue that understanding the impact of anthropomorphic AI is critical to understanding the impact of AI.
Reposted by Stanford NLP Group

Big win for Stanford NLP to have @yejinchoinka.bsky.social Looking forward to new amazing directions
Look who we found hanging out in her new Stanford Gates Computer Science office!
We’re truly delighted to welcome @yejinchoinka.bsky.social as a new @stanfordnlp.bsky.social faculty member, starting full-time in September. ❤️
nlp.stanford.edu/people/
We’re truly delighted to welcome @yejinchoinka.bsky.social as a new @stanfordnlp.bsky.social faculty member, starting full-time in September. ❤️
nlp.stanford.edu/people/

April 8, 2025 at 3:57 AM
Big win for Stanford NLP to have @yejinchoinka.bsky.social Looking forward to new amazing directions
Reposted by Stanford NLP Group

The Model Context Protocol is cool because it gives external developers a way to add meaningful functionality on top of LLM platforms.
To limit test this, I made a "Realtime Voice" MCP using free STT, VAD, and TTS systems. The result is a janky, but makes me me excited about the ecosystem to come!
To limit test this, I made a "Realtime Voice" MCP using free STT, VAD, and TTS systems. The result is a janky, but makes me me excited about the ecosystem to come!
April 10, 2025 at 10:03 PM
The Model Context Protocol is cool because it gives external developers a way to add meaningful functionality on top of LLM platforms.
To limit test this, I made a "Realtime Voice" MCP using free STT, VAD, and TTS systems. The result is a janky, but makes me me excited about the ecosystem to come!
To limit test this, I made a "Realtime Voice" MCP using free STT, VAD, and TTS systems. The result is a janky, but makes me me excited about the ecosystem to come!
Look who we found hanging out in her new Stanford Gates Computer Science office!
We’re truly delighted to welcome @yejinchoinka.bsky.social as a new @stanfordnlp.bsky.social faculty member, starting full-time in September. ❤️
nlp.stanford.edu/people/
We’re truly delighted to welcome @yejinchoinka.bsky.social as a new @stanfordnlp.bsky.social faculty member, starting full-time in September. ❤️
nlp.stanford.edu/people/
April 4, 2025 at 3:24 PM
Look who we found hanging out in her new Stanford Gates Computer Science office!
We’re truly delighted to welcome @yejinchoinka.bsky.social as a new @stanfordnlp.bsky.social faculty member, starting full-time in September. ❤️
nlp.stanford.edu/people/
We’re truly delighted to welcome @yejinchoinka.bsky.social as a new @stanfordnlp.bsky.social faculty member, starting full-time in September. ❤️
nlp.stanford.edu/people/
Reposted by Stanford NLP Group

#WomensHistoryMonth: Honoring trailblazing #WomenOfAI whose research has made an impact on the current #AI/ML revolution incl. @anima-anandkumar.bsky.social @timnitgebru.bsky.social @mmitchell.bsky.social @deviparikh.bsky.social @ajlunited.bsky.social @yejinchoinka.bsky.social @drfeifei.bsky.social

March 30, 2025 at 7:33 PM
#WomensHistoryMonth: Honoring trailblazing #WomenOfAI whose research has made an impact on the current #AI/ML revolution incl. @anima-anandkumar.bsky.social @timnitgebru.bsky.social @mmitchell.bsky.social @deviparikh.bsky.social @ajlunited.bsky.social @yejinchoinka.bsky.social @drfeifei.bsky.social
Reposted by Stanford NLP Group

Stanford scholars introduced an open-source AI agent that learns how to navigate websites by mimicking childhood learning – an approach that could lead to more efficient, transparent, and privacy-conscious AI: hai.stanford.edu/news/an-open...
@chrmanning.bsky.social @shikharmurty.bsky.social
@chrmanning.bsky.social @shikharmurty.bsky.social
An Open-Source AI Agent for Doing Tasks on the Web | Stanford HAI
NNetNav learns how to navigate websites by mimicking childhood learning through exploration.
hai.stanford.edu
March 28, 2025 at 7:00 PM
Stanford scholars introduced an open-source AI agent that learns how to navigate websites by mimicking childhood learning – an approach that could lead to more efficient, transparent, and privacy-conscious AI: hai.stanford.edu/news/an-open...
@chrmanning.bsky.social @shikharmurty.bsky.social
@chrmanning.bsky.social @shikharmurty.bsky.social
Reposted by Stanford NLP Group

Teaching for the first time: I finished the last official lecture of the class and got a surprise round of applause! Feels so great!
March 27, 2025 at 7:25 PM
Teaching for the first time: I finished the last official lecture of the class and got a surprise round of applause! Feels so great!
Reposted by Stanford NLP Group

🎙️ Speech recognition is great - if you speak the right language.
Our new @stanfordnlp.bsky.social paper introduces CTC-DRO, a training method that reduces worst-language errors by up to 47.1%.
Work w/ Ananjan, Moussa, @jurafsky.bsky.social, Tatsu Hashimoto and Karen Livescu.
Here’s how it works 🧵
Our new @stanfordnlp.bsky.social paper introduces CTC-DRO, a training method that reduces worst-language errors by up to 47.1%.
Work w/ Ananjan, Moussa, @jurafsky.bsky.social, Tatsu Hashimoto and Karen Livescu.
Here’s how it works 🧵
March 12, 2025 at 3:29 PM
🎙️ Speech recognition is great - if you speak the right language.
Our new @stanfordnlp.bsky.social paper introduces CTC-DRO, a training method that reduces worst-language errors by up to 47.1%.
Work w/ Ananjan, Moussa, @jurafsky.bsky.social, Tatsu Hashimoto and Karen Livescu.
Here’s how it works 🧵
Our new @stanfordnlp.bsky.social paper introduces CTC-DRO, a training method that reduces worst-language errors by up to 47.1%.
Work w/ Ananjan, Moussa, @jurafsky.bsky.social, Tatsu Hashimoto and Karen Livescu.
Here’s how it works 🧵
Reposted by Stanford NLP Group

Our survey highlights the enduring influence of linguistics on #NLProc. We emphasize 6 facets: Resources, Evaluation, Low-resource settings, Interpretability, Explanation, and the Study of language.

Happy to share that our paper, "Natural Language Processing RELIES on Linguistics," will appear in Computational Linguistics!
Preprint: arxiv.org/abs/2405.05966
Preprint: arxiv.org/abs/2405.05966

March 11, 2025 at 7:06 PM
Our survey highlights the enduring influence of linguistics on #NLProc. We emphasize 6 facets: Resources, Evaluation, Low-resource settings, Interpretability, Explanation, and the Study of language.
Reposted by Stanford NLP Group

Check it out for cool plots like this about how affinities between words in sentences and how they can show how Green Day isn't like green paint or green tea. And congrats to @coryshain.bsky.social and the CLiMB lab! climblab.org

March 11, 2025 at 8:04 PM
Check it out for cool plots like this about how affinities between words in sentences and how they can show how Green Day isn't like green paint or green tea. And congrats to @coryshain.bsky.social and the CLiMB lab! climblab.org
Reposted by Stanford NLP Group

🚨 First preprint from the lab! 🚨 Josh Rozner (w/@weissweiler.bsky.social and @kmahowald.bsky.social) uses counterfactual experiments on LMs to show that word distributions can provide a learning signal for diverse syntactic constructions, including some hard cases.

Constructions are Revealed in Word Distributions
Construction grammar posits that constructions (form-meaning pairings) are acquired through experience with language (the distributional learning hypothesis). But how much information about…
arxiv.org
March 11, 2025 at 6:06 PM
🚨 First preprint from the lab! 🚨 Josh Rozner (w/@weissweiler.bsky.social and @kmahowald.bsky.social) uses counterfactual experiments on LMs to show that word distributions can provide a learning signal for diverse syntactic constructions, including some hard cases.
Reposted by Stanford NLP Group

I am concerned about AI but late at night, alone working on a proposal, I was glad ChatGPT had my back as I hit submit 😀.. Reminded me of @chrmanning.bsky.social’s mention in a talk of the 'Real World Utility Test' - early adoption of tech moves forward when it’s genuinely useful, concerns and all.
March 6, 2025 at 10:21 PM
I am concerned about AI but late at night, alone working on a proposal, I was glad ChatGPT had my back as I hit submit 😀.. Reminded me of @chrmanning.bsky.social’s mention in a talk of the 'Real World Utility Test' - early adoption of tech moves forward when it’s genuinely useful, concerns and all.
Reposted by Stanford NLP Group

Upcoming joint LCSR seminar featuring @stanfordnlp.bsky.social’s @siddkaramcheti.bsky.social! Learn more about it here: www.cs.jhu.edu/event/cs-lcs...

March 7, 2025 at 7:59 PM
Upcoming joint LCSR seminar featuring @stanfordnlp.bsky.social’s @siddkaramcheti.bsky.social! Learn more about it here: www.cs.jhu.edu/event/cs-lcs...
An introductory talk by @chrmanning.bsky.social on “Large Language Models in 2025 – How much understanding and intelligence?” at the Workshop on a Public AI Assistant to Worldwide Knowledge at Stanford, covering 3 eras of LLMs, RAG, Agents, DeepSeek-R1, using LLMs, ….
Video: youtu.be/5Aer7MUSuSU
Video: youtu.be/5Aer7MUSuSU

March 10, 2025 at 11:20 PM
An introductory talk by @chrmanning.bsky.social on “Large Language Models in 2025 – How much understanding and intelligence?” at the Workshop on a Public AI Assistant to Worldwide Knowledge at Stanford, covering 3 eras of LLMs, RAG, Agents, DeepSeek-R1, using LLMs, ….
Video: youtu.be/5Aer7MUSuSU
Video: youtu.be/5Aer7MUSuSU
Reposted by Stanford NLP Group

How can we better think and talk about human-like qualities attributed to language technologies like LLMs? In our #CHI2025 paper, we taxonomize how text outputs from cases of user interactions with language technologies can contribute to anthropomorphism. arxiv.org/abs/2502.09870 1/n

March 6, 2025 at 3:43 AM
How can we better think and talk about human-like qualities attributed to language technologies like LLMs? In our #CHI2025 paper, we taxonomize how text outputs from cases of user interactions with language technologies can contribute to anthropomorphism. arxiv.org/abs/2502.09870 1/n
Reposted by Stanford NLP Group

We are getting closer to have agents operating in the real physical world. However, can we trust frontier models to make embodied decisions 🎮 aligned with human norms 👩⚖️ ?
With EgoNormia, a 1.8k ego-centric video 🥽 QA benchmark, we show that this is surprisingly challenging!
With EgoNormia, a 1.8k ego-centric video 🥽 QA benchmark, we show that this is surprisingly challenging!
March 4, 2025 at 4:32 AM
We are getting closer to have agents operating in the real physical world. However, can we trust frontier models to make embodied decisions 🎮 aligned with human norms 👩⚖️ ?
With EgoNormia, a 1.8k ego-centric video 🥽 QA benchmark, we show that this is surprisingly challenging!
With EgoNormia, a 1.8k ego-centric video 🥽 QA benchmark, we show that this is surprisingly challenging!
Reposted by Stanford NLP Group

EgoNormia (egonormia.org) exposes a major gap in Vision-Language Models understanding of the social world: they don't know how to behave when norms about the physical world *conflict* ⚔️ (<45% acc.)
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
March 4, 2025 at 4:44 AM
EgoNormia (egonormia.org) exposes a major gap in Vision-Language Models understanding of the social world: they don't know how to behave when norms about the physical world *conflict* ⚔️ (<45% acc.)
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
Reposted by Stanford NLP Group

1/13 New Paper!! We try to understand why some LMs self-improve their reasoning while others hit a wall. The key? Cognitive behaviors! Read our paper on how the right cognitive behaviors can make all the difference in a model's ability to improve with RL! 🧵

March 4, 2025 at 6:15 PM
1/13 New Paper!! We try to understand why some LMs self-improve their reasoning while others hit a wall. The key? Cognitive behaviors! Read our paper on how the right cognitive behaviors can make all the difference in a model's ability to improve with RL! 🧵
Reposted by Stanford NLP Group

In 2013, at AKBC 2013 and other workshops, I gave a talk titled “Texts are Knowledge”. This was well before there were any transformer LLMs—indeed before the invention of attention—and my early neural NLP ideas were rudimentary.
🔮 Nevertheless, the talk was quite prophetic!
🔮 Nevertheless, the talk was quite prophetic!




March 3, 2025 at 10:46 PM
In 2013, at AKBC 2013 and other workshops, I gave a talk titled “Texts are Knowledge”. This was well before there were any transformer LLMs—indeed before the invention of attention—and my early neural NLP ideas were rudimentary.
🔮 Nevertheless, the talk was quite prophetic!
🔮 Nevertheless, the talk was quite prophetic!
Reposted by Stanford NLP Group

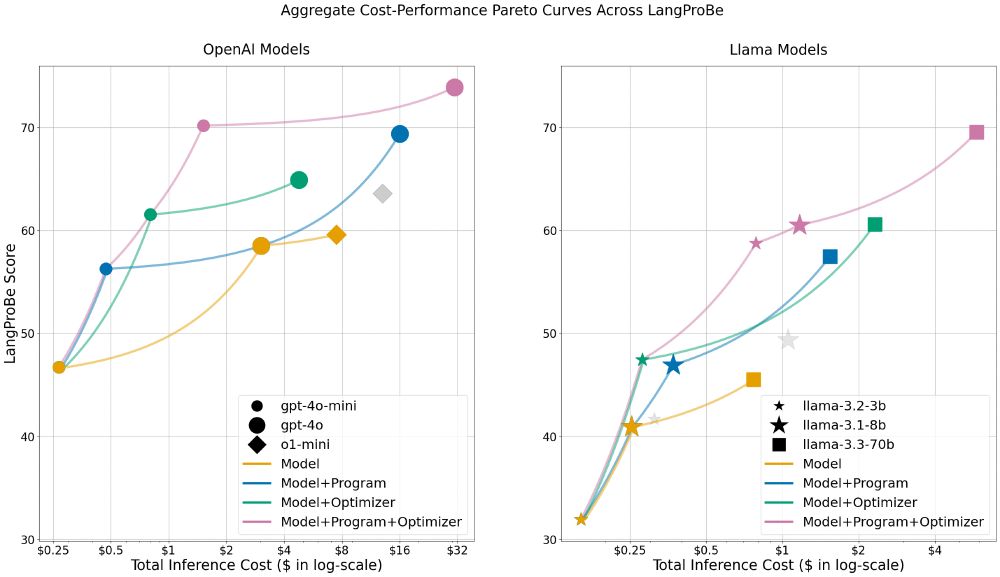
🧵Introducing LangProBe: the first benchmark testing where and how composing LLMs into language programs affects cost-quality tradeoffs!
We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.
We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.
March 3, 2025 at 6:59 PM
🧵Introducing LangProBe: the first benchmark testing where and how composing LLMs into language programs affects cost-quality tradeoffs!
We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.
We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.
Reposted by Stanford NLP Group
Excited to have two papers at #NAACL2025!
The first reveals how human over-reliance can be exacerbated by LLM friendliness. The second presents a novel computational method for concept tracing. Check them out!
arxiv.org/pdf/2407.07950
arxiv.org/pdf/2502.05704
The first reveals how human over-reliance can be exacerbated by LLM friendliness. The second presents a novel computational method for concept tracing. Check them out!
arxiv.org/pdf/2407.07950
arxiv.org/pdf/2502.05704

February 19, 2025 at 9:58 PM
Excited to have two papers at #NAACL2025!
The first reveals how human over-reliance can be exacerbated by LLM friendliness. The second presents a novel computational method for concept tracing. Check them out!
arxiv.org/pdf/2407.07950
arxiv.org/pdf/2502.05704
The first reveals how human over-reliance can be exacerbated by LLM friendliness. The second presents a novel computational method for concept tracing. Check them out!
arxiv.org/pdf/2407.07950
arxiv.org/pdf/2502.05704
Reposted by Stanford NLP Group

Real-world AI needs real-world work. Let’s make it happen 🔥🔥
Want to learn more?
Paper: arxiv.org/pdf/2410.03017v2
Code: github.com/rosewang2008/tutor-copilot
School visit: www.youtube.com/watch?v=IOd2...
Thank you @nssaccelerator.bsky.social @stanfordnlp.bsky.social for the support!
Want to learn more?
Paper: arxiv.org/pdf/2410.03017v2
Code: github.com/rosewang2008/tutor-copilot
School visit: www.youtube.com/watch?v=IOd2...
Thank you @nssaccelerator.bsky.social @stanfordnlp.bsky.social for the support!
arxiv.org
February 18, 2025 at 4:28 PM
Real-world AI needs real-world work. Let’s make it happen 🔥🔥
Want to learn more?
Paper: arxiv.org/pdf/2410.03017v2
Code: github.com/rosewang2008/tutor-copilot
School visit: www.youtube.com/watch?v=IOd2...
Thank you @nssaccelerator.bsky.social @stanfordnlp.bsky.social for the support!
Want to learn more?
Paper: arxiv.org/pdf/2410.03017v2
Code: github.com/rosewang2008/tutor-copilot
School visit: www.youtube.com/watch?v=IOd2...
Thank you @nssaccelerator.bsky.social @stanfordnlp.bsky.social for the support!
Reposted by Stanford NLP Group
AI won’t reshape education without tackling real problems. Why are we not visiting schools or talking to teachers?
A year ago, I partnered with a district facing a major challenge. Instead of doing AI x Education research in isolation, I focused on their real needs.🧵
A year ago, I partnered with a district facing a major challenge. Instead of doing AI x Education research in isolation, I focused on their real needs.🧵

February 18, 2025 at 4:28 PM
AI won’t reshape education without tackling real problems. Why are we not visiting schools or talking to teachers?
A year ago, I partnered with a district facing a major challenge. Instead of doing AI x Education research in isolation, I focused on their real needs.🧵
A year ago, I partnered with a district facing a major challenge. Instead of doing AI x Education research in isolation, I focused on their real needs.🧵
Reposted by Stanford NLP Group

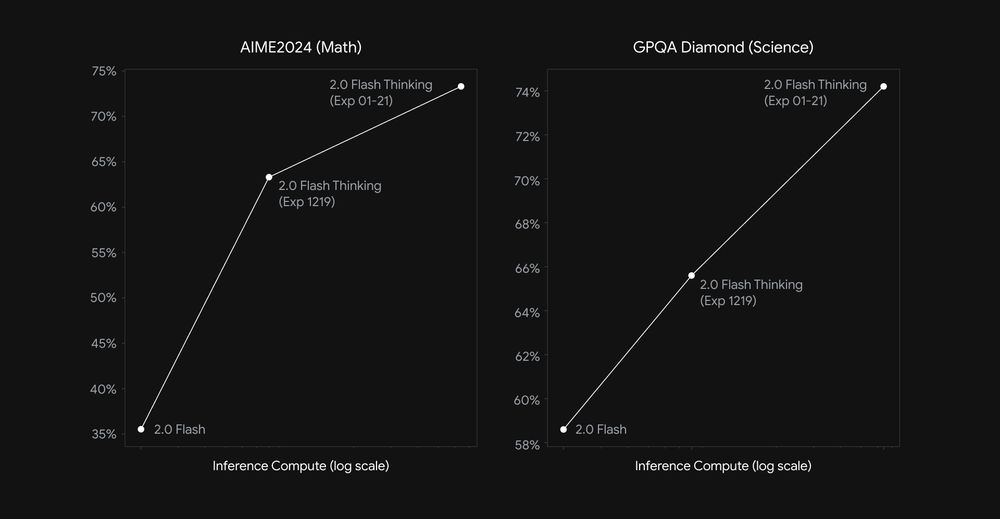
We’ve been thrilled by the positive reception to Gemini 2.0 Flash Thinking we discussed in December.
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
January 22, 2025 at 12:31 AM
We’ve been thrilled by the positive reception to Gemini 2.0 Flash Thinking we discussed in December.
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%