



@sta8is.bsky.social
📄 Check out our paper at arxiv.org/abs/2501.08303 and 🖥️code at github.com/Sta8is/FUTUR... to learn more about FUTURIST and its applications in autonomous systems! (9/n)
Joint work with @ikakogeorgiou.bsky.social, @spyrosgidaris.bsky.social and Nikos Komodakis
Joint work with @ikakogeorgiou.bsky.social, @spyrosgidaris.bsky.social and Nikos Komodakis

Advancing Semantic Future Prediction through Multimodal Visual Sequence Transformers
Semantic future prediction is important for autonomous systems navigating dynamic environments. This paper introduces FUTURIST, a method for multimodal future semantic prediction that uses a unified a...
arxiv.org
February 26, 2025 at 7:57 PM
📄 Check out our paper at arxiv.org/abs/2501.08303 and 🖥️code at github.com/Sta8is/FUTUR... to learn more about FUTURIST and its applications in autonomous systems! (9/n)
Joint work with @ikakogeorgiou.bsky.social, @spyrosgidaris.bsky.social and Nikos Komodakis
Joint work with @ikakogeorgiou.bsky.social, @spyrosgidaris.bsky.social and Nikos Komodakis
🚀 The architecture demonstrates significant performance improvements with extended training—indicating substantial potential for future enhancements (8/n)

February 26, 2025 at 7:57 PM
🚀 The architecture demonstrates significant performance improvements with extended training—indicating substantial potential for future enhancements (8/n)
💡 Our multimodal approach significantly outperforms single-modality variants, demonstrating the power of learning cross-modal relationships (7/n)

February 26, 2025 at 7:57 PM
💡 Our multimodal approach significantly outperforms single-modality variants, demonstrating the power of learning cross-modal relationships (7/n)
📈 Results are impressive! We achieve state-of-the-art performance in future semantic segmentation on Cityscapes, with strong improvements in both short-term (0.18s) and mid-term (0.54s) predictions (6/n)

February 26, 2025 at 7:57 PM
📈 Results are impressive! We achieve state-of-the-art performance in future semantic segmentation on Cityscapes, with strong improvements in both short-term (0.18s) and mid-term (0.54s) predictions (6/n)
🎭 Key innovation #3: We developed a novel multimodal masked visual modeling objective specifically designed for future prediction tasks (5/n)

February 26, 2025 at 7:57 PM
🎭 Key innovation #3: We developed a novel multimodal masked visual modeling objective specifically designed for future prediction tasks (5/n)
🔗 Key innovation #2: Our model features an efficient cross-modality fusion mechanism that improves predictions by learning synergies between different modalities (segmentation + depth) (4/n)

February 26, 2025 at 7:57 PM
🔗 Key innovation #2: Our model features an efficient cross-modality fusion mechanism that improves predictions by learning synergies between different modalities (segmentation + depth) (4/n)
🎯 Key innovation #1: We introduce a VAE-free hierarchical tokenization process integrated directly into our transformer. This simplifies training, reduces computational overhead, and enables true end-to-end optimization (3/n)

February 26, 2025 at 7:57 PM
🎯 Key innovation #1: We introduce a VAE-free hierarchical tokenization process integrated directly into our transformer. This simplifies training, reduces computational overhead, and enables true end-to-end optimization (3/n)
🔍 FUTURIST employs a multimodal visual sequence transformer to directly predict multiple future semantic modalities. We focus on two key modalities: semantic segmentation and depth estimation—critical capabilities for autonomous systems operating in dynamic environments (2/n)

February 26, 2025 at 7:57 PM
🔍 FUTURIST employs a multimodal visual sequence transformer to directly predict multiple future semantic modalities. We focus on two key modalities: semantic segmentation and depth estimation—critical capabilities for autonomous systems operating in dynamic environments (2/n)
8/n 💡Our work shows that by leveraging the semantic power of VFMs, we create more efficient and effective future prediction systems.
📄 Paper: arxiv.org/abs/2412.11673
🖥️Code available at: github.com/Sta8is/DINO-...
Joint work with @ikakogeorgiou.bsky.social, @spyrosgidaris.bsky.social, N. Komodakis
📄 Paper: arxiv.org/abs/2412.11673
🖥️Code available at: github.com/Sta8is/DINO-...
Joint work with @ikakogeorgiou.bsky.social, @spyrosgidaris.bsky.social, N. Komodakis
DINO-Foresight: Looking into the Future with DINO
Predicting future dynamics is crucial for applications like autonomous driving and robotics, where understanding the environment is key. Existing pixel-level methods are computationally expensive and ...
arxiv.org
February 7, 2025 at 5:06 PM
8/n 💡Our work shows that by leveraging the semantic power of VFMs, we create more efficient and effective future prediction systems.
📄 Paper: arxiv.org/abs/2412.11673
🖥️Code available at: github.com/Sta8is/DINO-...
Joint work with @ikakogeorgiou.bsky.social, @spyrosgidaris.bsky.social, N. Komodakis
📄 Paper: arxiv.org/abs/2412.11673
🖥️Code available at: github.com/Sta8is/DINO-...
Joint work with @ikakogeorgiou.bsky.social, @spyrosgidaris.bsky.social, N. Komodakis
7/n 🔬Interesting discovery: The intermediate features from our transformer can actually enhance the already-strong VFM features, suggesting potential for self-supervised learning.

February 7, 2025 at 5:06 PM
7/n 🔬Interesting discovery: The intermediate features from our transformer can actually enhance the already-strong VFM features, suggesting potential for self-supervised learning.
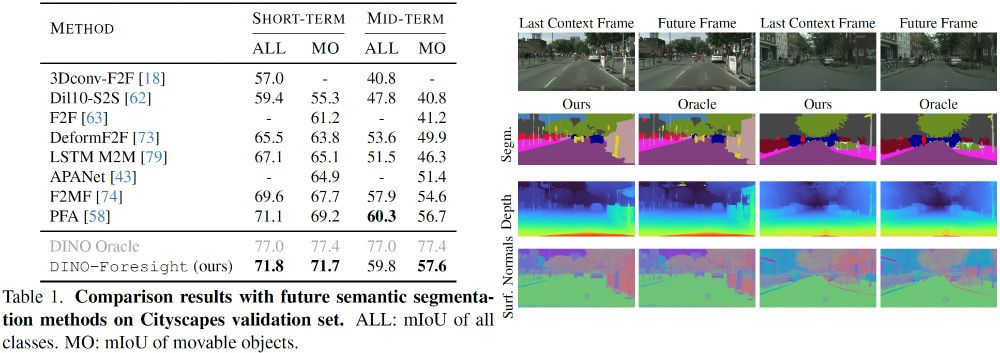
6/n 📊And it works amazingly well! We achieve state-of-the-art results in semantic segmentation forecasting, with strong performance across multiple tasks using a single feature prediction model.
February 7, 2025 at 5:06 PM
6/n 📊And it works amazingly well! We achieve state-of-the-art results in semantic segmentation forecasting, with strong performance across multiple tasks using a single feature prediction model.
5/n 🎨The beauty of our method? It's completely modular - different task-specific heads (segmentation, depth estimation, surface normals) can be plugged in without retraining the core model.

February 7, 2025 at 5:06 PM
5/n 🎨The beauty of our method? It's completely modular - different task-specific heads (segmentation, depth estimation, surface normals) can be plugged in without retraining the core model.
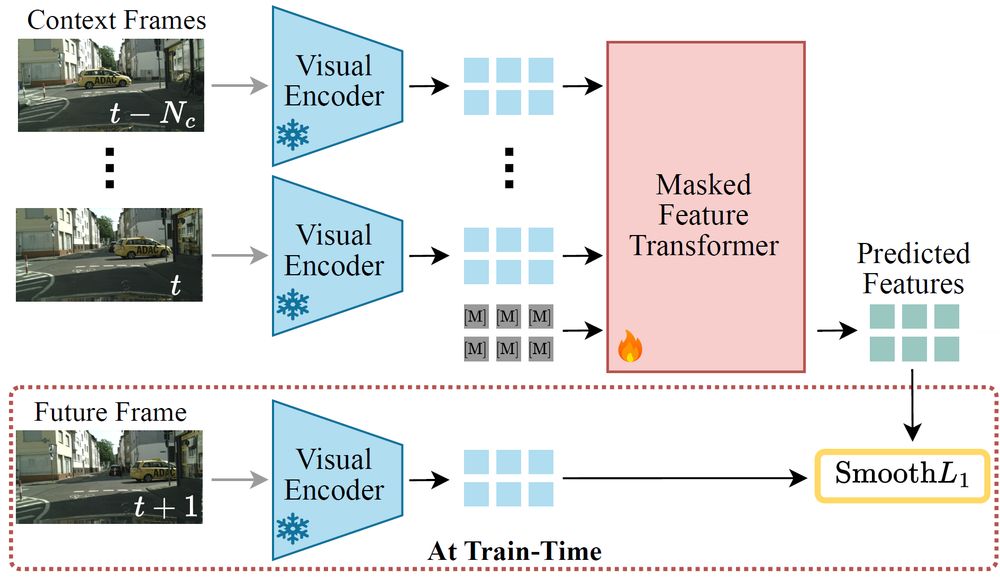
4/n 🔄Our approach: We train a masked feature transformer to predict how VFM features change over time. These predicted features can then be used for various scene understanding tasks!
February 7, 2025 at 5:06 PM
4/n 🔄Our approach: We train a masked feature transformer to predict how VFM features change over time. These predicted features can then be used for various scene understanding tasks!
3/n 🧩Why is this important? Most existing approaches focus on pixel-level prediction, which wastes computation on irrelevant visual details. We focus directly on meaningful semantic features!
February 7, 2025 at 5:06 PM
3/n 🧩Why is this important? Most existing approaches focus on pixel-level prediction, which wastes computation on irrelevant visual details. We focus directly on meaningful semantic features!
2/n 🎯Our key insight: Instead of predicting future RGB frames directly, we can forecast how semantic features from Vision Foundation Models (VFMs) evolve over time.
February 7, 2025 at 5:06 PM
2/n 🎯Our key insight: Instead of predicting future RGB frames directly, we can forecast how semantic features from Vision Foundation Models (VFMs) evolve over time.