




Simone Scardapane
@sscardapane.bsky.social
I fall in love with a new #machinelearning topic every month 🙄
Ass. Prof. Sapienza (Rome) | Author: Alice in a differentiable wonderland (https://www.sscardapane.it/alice-book/)
Ass. Prof. Sapienza (Rome) | Author: Alice in a differentiable wonderland (https://www.sscardapane.it/alice-book/)
*CAT: Content-Adaptive Image Tokenization*
by @junhongshen1.bsky.social @lukezettlemoyer.bsky.social et al.
They use an LLM to predict a "complexity score" for each image token, which in turns decides the size of its VAE latent representation.
arxiv.org/abs/2501.03120
by @junhongshen1.bsky.social @lukezettlemoyer.bsky.social et al.
They use an LLM to predict a "complexity score" for each image token, which in turns decides the size of its VAE latent representation.
arxiv.org/abs/2501.03120

February 17, 2025 at 2:57 PM
*CAT: Content-Adaptive Image Tokenization*
by @junhongshen1.bsky.social @lukezettlemoyer.bsky.social et al.
They use an LLM to predict a "complexity score" for each image token, which in turns decides the size of its VAE latent representation.
arxiv.org/abs/2501.03120
by @junhongshen1.bsky.social @lukezettlemoyer.bsky.social et al.
They use an LLM to predict a "complexity score" for each image token, which in turns decides the size of its VAE latent representation.
arxiv.org/abs/2501.03120
*Accurate predictions on small data with a tabular foundation model*
by Noah Hollmann et al.
A transformer for tabular data that takes an entire training set as input and provides predictions - trained on millions of synthetic datasets.
www.nature.com/articles/s41...
by Noah Hollmann et al.
A transformer for tabular data that takes an entire training set as input and provides predictions - trained on millions of synthetic datasets.
www.nature.com/articles/s41...

February 14, 2025 at 3:52 PM
*Accurate predictions on small data with a tabular foundation model*
by Noah Hollmann et al.
A transformer for tabular data that takes an entire training set as input and provides predictions - trained on millions of synthetic datasets.
www.nature.com/articles/s41...
by Noah Hollmann et al.
A transformer for tabular data that takes an entire training set as input and provides predictions - trained on millions of synthetic datasets.
www.nature.com/articles/s41...
*Insights on Galaxy Evolution from Interpretable Sparse Feature Networks*
by @jwuphysics.bsky.social
Integrates a sparse dictionary step on the last layer of a CNN to obtain a set of interpretable features on multiple astronomical prediction tasks.
arxiv.org/abs/2501.00089
by @jwuphysics.bsky.social
Integrates a sparse dictionary step on the last layer of a CNN to obtain a set of interpretable features on multiple astronomical prediction tasks.
arxiv.org/abs/2501.00089

February 13, 2025 at 1:54 PM
*Insights on Galaxy Evolution from Interpretable Sparse Feature Networks*
by @jwuphysics.bsky.social
Integrates a sparse dictionary step on the last layer of a CNN to obtain a set of interpretable features on multiple astronomical prediction tasks.
arxiv.org/abs/2501.00089
by @jwuphysics.bsky.social
Integrates a sparse dictionary step on the last layer of a CNN to obtain a set of interpretable features on multiple astronomical prediction tasks.
arxiv.org/abs/2501.00089
*Round and Round We Go! What makes Rotary Positional Encodings useful?*
by @petar-v.bsky.social et al.
They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics.
arxiv.org/abs/2410.06205
by @petar-v.bsky.social et al.
They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics.
arxiv.org/abs/2410.06205

February 10, 2025 at 11:23 AM
*Round and Round We Go! What makes Rotary Positional Encodings useful?*
by @petar-v.bsky.social et al.
They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics.
arxiv.org/abs/2410.06205
by @petar-v.bsky.social et al.
They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics.
arxiv.org/abs/2410.06205
*Cautious Optimizers: Improving Training with One Line of Code*
by Liang et al.
Adding a simple masking operation to momentum-based optimizers can significantly boost their speed.
arxiv.org/abs/2411.16085
by Liang et al.
Adding a simple masking operation to momentum-based optimizers can significantly boost their speed.
arxiv.org/abs/2411.16085

February 3, 2025 at 12:30 PM
*Cautious Optimizers: Improving Training with One Line of Code*
by Liang et al.
Adding a simple masking operation to momentum-based optimizers can significantly boost their speed.
arxiv.org/abs/2411.16085
by Liang et al.
Adding a simple masking operation to momentum-based optimizers can significantly boost their speed.
arxiv.org/abs/2411.16085
*Byte Latent Transformer: Patches Scale Better Than Tokens*
by @artidoro.bsky.social et al.
Trains a small encoder to dynamically aggregate bytes into tokens, which are input to a standard autoregressive model. Nice direction!
arxiv.org/abs/2412.09871
by @artidoro.bsky.social et al.
Trains a small encoder to dynamically aggregate bytes into tokens, which are input to a standard autoregressive model. Nice direction!
arxiv.org/abs/2412.09871

January 31, 2025 at 9:56 AM
*Byte Latent Transformer: Patches Scale Better Than Tokens*
by @artidoro.bsky.social et al.
Trains a small encoder to dynamically aggregate bytes into tokens, which are input to a standard autoregressive model. Nice direction!
arxiv.org/abs/2412.09871
by @artidoro.bsky.social et al.
Trains a small encoder to dynamically aggregate bytes into tokens, which are input to a standard autoregressive model. Nice direction!
arxiv.org/abs/2412.09871
*Understanding Gradient Descent through the Training Jacobian*
by @norabelrose.bsky.social @eleutherai.bsky.social
Analyzes training through the spectrum of the "training Jacobian" (∇ of trained weights wrt initial weights), identifying a large inactive subspace.
arxiv.org/abs/2412.07003
by @norabelrose.bsky.social @eleutherai.bsky.social
Analyzes training through the spectrum of the "training Jacobian" (∇ of trained weights wrt initial weights), identifying a large inactive subspace.
arxiv.org/abs/2412.07003

January 28, 2025 at 11:47 AM
*Understanding Gradient Descent through the Training Jacobian*
by @norabelrose.bsky.social @eleutherai.bsky.social
Analyzes training through the spectrum of the "training Jacobian" (∇ of trained weights wrt initial weights), identifying a large inactive subspace.
arxiv.org/abs/2412.07003
by @norabelrose.bsky.social @eleutherai.bsky.social
Analyzes training through the spectrum of the "training Jacobian" (∇ of trained weights wrt initial weights), identifying a large inactive subspace.
arxiv.org/abs/2412.07003
*Mixture of A Million Experts*
by Xu Owen He
Scales a MoE architecture up to millions of experts by implementing a fast retrieval method in the router, inspired by recent MoE scaling laws.
arxiv.org/abs/2407.04153
by Xu Owen He
Scales a MoE architecture up to millions of experts by implementing a fast retrieval method in the router, inspired by recent MoE scaling laws.
arxiv.org/abs/2407.04153

January 27, 2025 at 2:00 PM
*Mixture of A Million Experts*
by Xu Owen He
Scales a MoE architecture up to millions of experts by implementing a fast retrieval method in the router, inspired by recent MoE scaling laws.
arxiv.org/abs/2407.04153
by Xu Owen He
Scales a MoE architecture up to millions of experts by implementing a fast retrieval method in the router, inspired by recent MoE scaling laws.
arxiv.org/abs/2407.04153
*Restructuring Vector Quantization with the Rotation Trick*
by Fifty et al.
Replaces the "closest codebook" operation in vector quantization with a rotation and rescaling operations to improve the back-propagation of gradients.
arxiv.org/abs/2410.06424
by Fifty et al.
Replaces the "closest codebook" operation in vector quantization with a rotation and rescaling operations to improve the back-propagation of gradients.
arxiv.org/abs/2410.06424

January 23, 2025 at 11:31 AM
*Restructuring Vector Quantization with the Rotation Trick*
by Fifty et al.
Replaces the "closest codebook" operation in vector quantization with a rotation and rescaling operations to improve the back-propagation of gradients.
arxiv.org/abs/2410.06424
by Fifty et al.
Replaces the "closest codebook" operation in vector quantization with a rotation and rescaling operations to improve the back-propagation of gradients.
arxiv.org/abs/2410.06424
*On the Surprising Effectiveness of Attention Transfer
for Vision Transformers*
by Li et al.
Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning.
arxiv.org/abs/2411.09702
for Vision Transformers*
by Li et al.
Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning.
arxiv.org/abs/2411.09702

January 21, 2025 at 11:35 AM
*On the Surprising Effectiveness of Attention Transfer
for Vision Transformers*
by Li et al.
Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning.
arxiv.org/abs/2411.09702
for Vision Transformers*
by Li et al.
Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning.
arxiv.org/abs/2411.09702
*The Super Weight in Large Language Models*
by Yu et al.
Identifies single weights in LLMs that destroy inference when deactivated. Tracks their mechanisms through the LLM and proposes quantization-specific techniques.
arxiv.org/abs/2411.07191
by Yu et al.
Identifies single weights in LLMs that destroy inference when deactivated. Tracks their mechanisms through the LLM and proposes quantization-specific techniques.
arxiv.org/abs/2411.07191

January 17, 2025 at 10:55 AM
*The Super Weight in Large Language Models*
by Yu et al.
Identifies single weights in LLMs that destroy inference when deactivated. Tracks their mechanisms through the LLM and proposes quantization-specific techniques.
arxiv.org/abs/2411.07191
by Yu et al.
Identifies single weights in LLMs that destroy inference when deactivated. Tracks their mechanisms through the LLM and proposes quantization-specific techniques.
arxiv.org/abs/2411.07191
*The Surprising Effectiveness of Test-Time Training for Abstract Reasoning*
by @ekinakyurek.bsky.social et al.
Shows that test-time training (fine-tuning at inference time) strongly improves performance on the ARC dataset.
arxiv.org/abs/2411.07279
by @ekinakyurek.bsky.social et al.
Shows that test-time training (fine-tuning at inference time) strongly improves performance on the ARC dataset.
arxiv.org/abs/2411.07279

January 16, 2025 at 10:50 AM
*The Surprising Effectiveness of Test-Time Training for Abstract Reasoning*
by @ekinakyurek.bsky.social et al.
Shows that test-time training (fine-tuning at inference time) strongly improves performance on the ARC dataset.
arxiv.org/abs/2411.07279
by @ekinakyurek.bsky.social et al.
Shows that test-time training (fine-tuning at inference time) strongly improves performance on the ARC dataset.
arxiv.org/abs/2411.07279
*Large Concept Models*
by Barrault et al.
Builds an autoregressive model in a "concept" space by wrapping the LLM in a pre-trained sentence embedder (also works with diffusion models).
arxiv.org/abs/2412.08821
by Barrault et al.
Builds an autoregressive model in a "concept" space by wrapping the LLM in a pre-trained sentence embedder (also works with diffusion models).
arxiv.org/abs/2412.08821

January 15, 2025 at 4:09 PM
*Large Concept Models*
by Barrault et al.
Builds an autoregressive model in a "concept" space by wrapping the LLM in a pre-trained sentence embedder (also works with diffusion models).
arxiv.org/abs/2412.08821
by Barrault et al.
Builds an autoregressive model in a "concept" space by wrapping the LLM in a pre-trained sentence embedder (also works with diffusion models).
arxiv.org/abs/2412.08821
*Adaptive Length Image Tokenization via Recurrent Allocation*
by @phillipisola.bsky.social et al.
An encoder to compress an image into a sequence of 1D tokens whose length can dynamically vary depending on the specific image.
arxiv.org/abs/2411.02393
by @phillipisola.bsky.social et al.
An encoder to compress an image into a sequence of 1D tokens whose length can dynamically vary depending on the specific image.
arxiv.org/abs/2411.02393

January 14, 2025 at 11:11 AM
*Adaptive Length Image Tokenization via Recurrent Allocation*
by @phillipisola.bsky.social et al.
An encoder to compress an image into a sequence of 1D tokens whose length can dynamically vary depending on the specific image.
arxiv.org/abs/2411.02393
by @phillipisola.bsky.social et al.
An encoder to compress an image into a sequence of 1D tokens whose length can dynamically vary depending on the specific image.
arxiv.org/abs/2411.02393
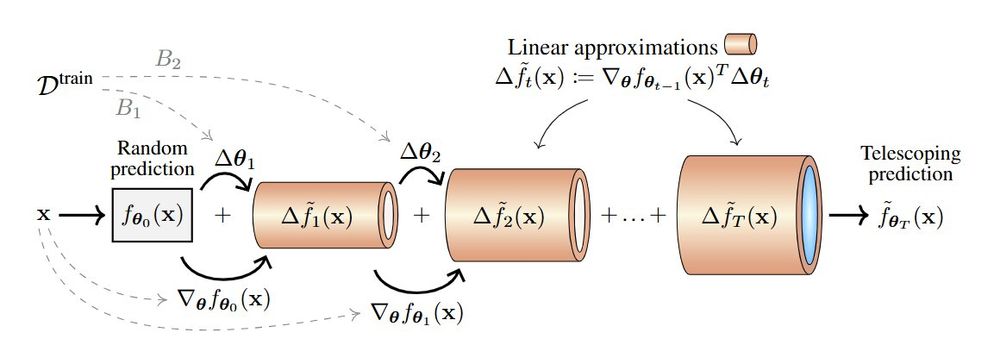
*Deep Learning Through A Telescoping Lens*
by @alanjeffares.bsky.social @aliciacurth.bsky.social
Shows that tracking 1st-order approximations to the training dynamics provides insights into many phenomena (e.g., double descent, grokking).
arxiv.org/abs/2411.00247
by @alanjeffares.bsky.social @aliciacurth.bsky.social
Shows that tracking 1st-order approximations to the training dynamics provides insights into many phenomena (e.g., double descent, grokking).
arxiv.org/abs/2411.00247
January 14, 2025 at 10:43 AM
*Deep Learning Through A Telescoping Lens*
by @alanjeffares.bsky.social @aliciacurth.bsky.social
Shows that tracking 1st-order approximations to the training dynamics provides insights into many phenomena (e.g., double descent, grokking).
arxiv.org/abs/2411.00247
by @alanjeffares.bsky.social @aliciacurth.bsky.social
Shows that tracking 1st-order approximations to the training dynamics provides insights into many phenomena (e.g., double descent, grokking).
arxiv.org/abs/2411.00247
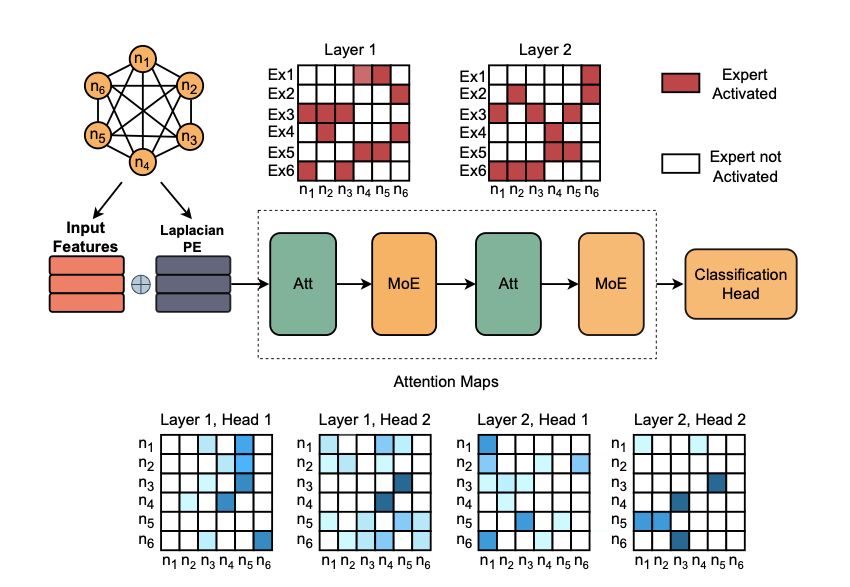
*MoE Graph Transformers for Interpretable Particle Collision Detection*
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
January 10, 2025 at 2:12 PM
*MoE Graph Transformers for Interpretable Particle Collision Detection*
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
*A Meticulous Guide to Advances in Deep Learning Efficiency over the Years* by Alex Zhang
Part deep learning history, part overview on the vast landscape of "efficiency" in DL (hardware, compilers, architecture, ...). Fantastic post!
alexzhang13.github.io/blog/2024/ef...
Part deep learning history, part overview on the vast landscape of "efficiency" in DL (hardware, compilers, architecture, ...). Fantastic post!
alexzhang13.github.io/blog/2024/ef...

January 9, 2025 at 2:15 PM
*A Meticulous Guide to Advances in Deep Learning Efficiency over the Years* by Alex Zhang
Part deep learning history, part overview on the vast landscape of "efficiency" in DL (hardware, compilers, architecture, ...). Fantastic post!
alexzhang13.github.io/blog/2024/ef...
Part deep learning history, part overview on the vast landscape of "efficiency" in DL (hardware, compilers, architecture, ...). Fantastic post!
alexzhang13.github.io/blog/2024/ef...
*Modular Duality in Deep Learning*
Develops a theory of "modular duality" for designing principled optimizers that respect the "type semantics" of each layer.
arxiv.org/abs/2410.21265
Develops a theory of "modular duality" for designing principled optimizers that respect the "type semantics" of each layer.
arxiv.org/abs/2410.21265

January 3, 2025 at 2:42 PM
*Modular Duality in Deep Learning*
Develops a theory of "modular duality" for designing principled optimizers that respect the "type semantics" of each layer.
arxiv.org/abs/2410.21265
Develops a theory of "modular duality" for designing principled optimizers that respect the "type semantics" of each layer.
arxiv.org/abs/2410.21265
*Understanding Visual Feature Reliance through the
Lens of Complexity*
by @thomasfel.bsky.social @louisbethune.bsky.social @lampinen.bsky.social
Wonderful work! They rank features' complexity with a variant of mutual information, before analyzing their dynamics.
arxiv.org/abs/2407.06076
Lens of Complexity*
by @thomasfel.bsky.social @louisbethune.bsky.social @lampinen.bsky.social
Wonderful work! They rank features' complexity with a variant of mutual information, before analyzing their dynamics.
arxiv.org/abs/2407.06076


December 28, 2024 at 5:22 PM
*Understanding Visual Feature Reliance through the
Lens of Complexity*
by @thomasfel.bsky.social @louisbethune.bsky.social @lampinen.bsky.social
Wonderful work! They rank features' complexity with a variant of mutual information, before analyzing their dynamics.
arxiv.org/abs/2407.06076
Lens of Complexity*
by @thomasfel.bsky.social @louisbethune.bsky.social @lampinen.bsky.social
Wonderful work! They rank features' complexity with a variant of mutual information, before analyzing their dynamics.
arxiv.org/abs/2407.06076
*Pooling in graph neural networks*
My friend FM Bianchi made an awesome introduction to GNNs and pooling techniques over graphs, full of nice visuals and details! 🔥
gnn-pooling.notion.site/1-3-pooling-...
My friend FM Bianchi made an awesome introduction to GNNs and pooling techniques over graphs, full of nice visuals and details! 🔥
gnn-pooling.notion.site/1-3-pooling-...

December 19, 2024 at 3:10 PM
*Pooling in graph neural networks*
My friend FM Bianchi made an awesome introduction to GNNs and pooling techniques over graphs, full of nice visuals and details! 🔥
gnn-pooling.notion.site/1-3-pooling-...
My friend FM Bianchi made an awesome introduction to GNNs and pooling techniques over graphs, full of nice visuals and details! 🔥
gnn-pooling.notion.site/1-3-pooling-...
*Relaxed Recursive Transformers*
by @talschuster.bsky.social et al.
Converts pre-trained transformers to a more efficient version by turning blocks of layers into a single layer which is iterated. Lots of interesting tricks!
arxiv.org/abs/2410.20672
by @talschuster.bsky.social et al.
Converts pre-trained transformers to a more efficient version by turning blocks of layers into a single layer which is iterated. Lots of interesting tricks!
arxiv.org/abs/2410.20672

December 18, 2024 at 10:28 AM
*Relaxed Recursive Transformers*
by @talschuster.bsky.social et al.
Converts pre-trained transformers to a more efficient version by turning blocks of layers into a single layer which is iterated. Lots of interesting tricks!
arxiv.org/abs/2410.20672
by @talschuster.bsky.social et al.
Converts pre-trained transformers to a more efficient version by turning blocks of layers into a single layer which is iterated. Lots of interesting tricks!
arxiv.org/abs/2410.20672
*Relaxed Equivariance via Multitask Learning*
by @tkrusch.bsky.social @mmbronstein.bsky.social
They propose a regularization approach for exploiting symmetries over data (penalizing variable predictions over augmented data).
arxiv.org/abs/2410.17878
by @tkrusch.bsky.social @mmbronstein.bsky.social
They propose a regularization approach for exploiting symmetries over data (penalizing variable predictions over augmented data).
arxiv.org/abs/2410.17878

December 13, 2024 at 2:28 PM
*Relaxed Equivariance via Multitask Learning*
by @tkrusch.bsky.social @mmbronstein.bsky.social
They propose a regularization approach for exploiting symmetries over data (penalizing variable predictions over augmented data).
arxiv.org/abs/2410.17878
by @tkrusch.bsky.social @mmbronstein.bsky.social
They propose a regularization approach for exploiting symmetries over data (penalizing variable predictions over augmented data).
arxiv.org/abs/2410.17878
*Rethinking Softmax: Self-Attention with Polynomial Activations*
They show that using softmax in the attention computation upper-bounds the Frobenius norm of the attention matrix, and similar results can be obtained with a polynomial normalization.
arxiv.org/abs/2410.18613
They show that using softmax in the attention computation upper-bounds the Frobenius norm of the attention matrix, and similar results can be obtained with a polynomial normalization.
arxiv.org/abs/2410.18613

December 13, 2024 at 1:47 PM
*Rethinking Softmax: Self-Attention with Polynomial Activations*
They show that using softmax in the attention computation upper-bounds the Frobenius norm of the attention matrix, and similar results can be obtained with a polynomial normalization.
arxiv.org/abs/2410.18613
They show that using softmax in the attention computation upper-bounds the Frobenius norm of the attention matrix, and similar results can be obtained with a polynomial normalization.
arxiv.org/abs/2410.18613
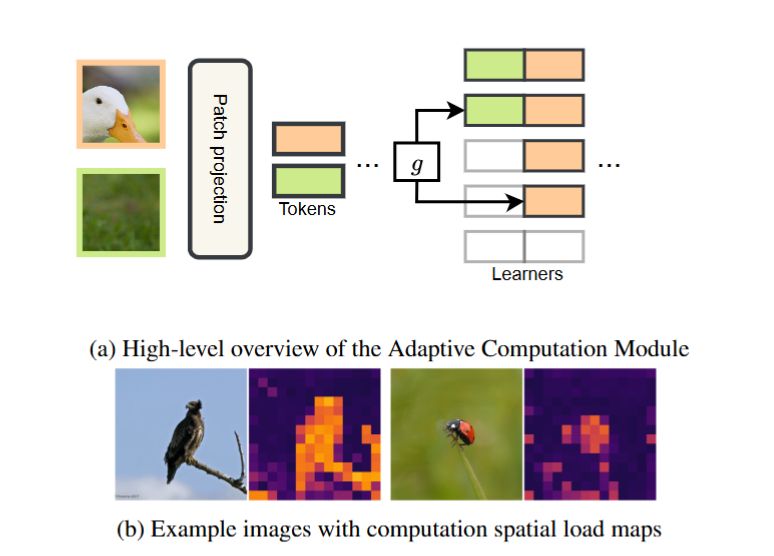
*Adaptive Computation Modules: Granular Conditional Computation For Efficient Inference*
with @alessiodevoto.bsky.social @neuralnoise.com
Happy to share our work on distilling efficient transformers with dynamic modules' activation was accepted at #AAAI2025. 🔥
arxiv.org/abs/2312.10193
with @alessiodevoto.bsky.social @neuralnoise.com
Happy to share our work on distilling efficient transformers with dynamic modules' activation was accepted at #AAAI2025. 🔥
arxiv.org/abs/2312.10193
December 11, 2024 at 2:25 PM
*Adaptive Computation Modules: Granular Conditional Computation For Efficient Inference*
with @alessiodevoto.bsky.social @neuralnoise.com
Happy to share our work on distilling efficient transformers with dynamic modules' activation was accepted at #AAAI2025. 🔥
arxiv.org/abs/2312.10193
with @alessiodevoto.bsky.social @neuralnoise.com
Happy to share our work on distilling efficient transformers with dynamic modules' activation was accepted at #AAAI2025. 🔥
arxiv.org/abs/2312.10193
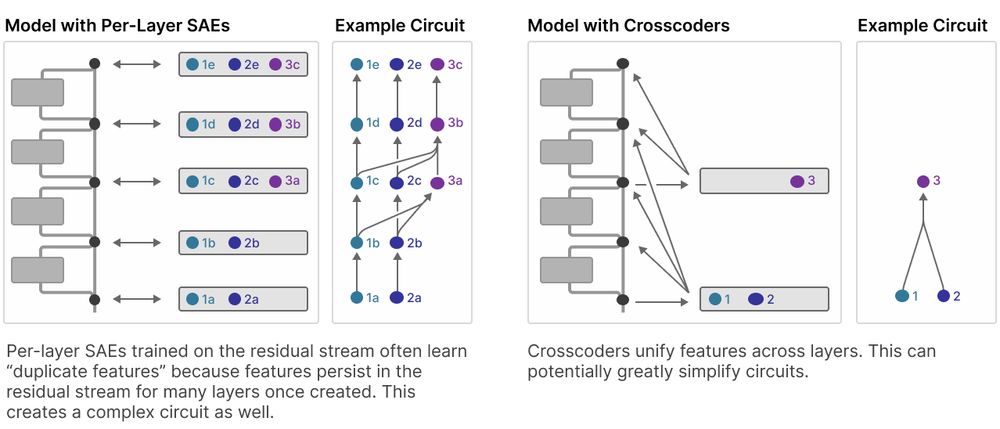
*Sparse Crosscoders for Cross-Layer Features and Model Diffing*
by @colah.bsky.social @anthropic.com
Investigates stability & dynamics of "interpretable features" with cross-layers SAEs. Can also be used to investigate differences in fine-tuned models.
transformer-circuits.pub/2024/crossco...
by @colah.bsky.social @anthropic.com
Investigates stability & dynamics of "interpretable features" with cross-layers SAEs. Can also be used to investigate differences in fine-tuned models.
transformer-circuits.pub/2024/crossco...
December 6, 2024 at 2:02 PM
*Sparse Crosscoders for Cross-Layer Features and Model Diffing*
by @colah.bsky.social @anthropic.com
Investigates stability & dynamics of "interpretable features" with cross-layers SAEs. Can also be used to investigate differences in fine-tuned models.
transformer-circuits.pub/2024/crossco...
by @colah.bsky.social @anthropic.com
Investigates stability & dynamics of "interpretable features" with cross-layers SAEs. Can also be used to investigate differences in fine-tuned models.
transformer-circuits.pub/2024/crossco...