




Skrub
@skrub-data.bsky.social
skrub is a Python library to ease preprocessing and feature engineering for tabular machine learning.
Our long-term goal is to directly connect database tables to machine learning estimators.
https://skrub-data.org
https://discord.gg/ABaPnm7fDC
Our long-term goal is to directly connect database tables to machine learning estimators.
https://skrub-data.org
https://discord.gg/ABaPnm7fDC
ApplyToFrame selects columns in the same way, but then uses all of them at the same time as input to the transformer: this is useful for dimensionality reduction.
SelectCols and DropCols can be used as "filtering blocks" in a pipeline.
SelectCols and DropCols can be used as "filtering blocks" in a pipeline.

October 8, 2025 at 12:43 PM
ApplyToFrame selects columns in the same way, but then uses all of them at the same time as input to the transformer: this is useful for dimensionality reduction.
SelectCols and DropCols can be used as "filtering blocks" in a pipeline.
SelectCols and DropCols can be used as "filtering blocks" in a pipeline.
Skrub includes a powerful set of transformers and selectors that allow to transform columns based on various conditions.
ApplyToCols lets you select a subset of columns in your dataframe, then applies a transformer to each selected column separately.
ApplyToCols lets you select a subset of columns in your dataframe, then applies a transformer to each selected column separately.

October 8, 2025 at 12:43 PM
Skrub includes a powerful set of transformers and selectors that allow to transform columns based on various conditions.
ApplyToCols lets you select a subset of columns in your dataframe, then applies a transformer to each selected column separately.
ApplyToCols lets you select a subset of columns in your dataframe, then applies a transformer to each selected column separately.
@pydataparis.bsky.social 2025 is over, and it was a big success!
Our talk was very well received, and we got a lot of great questions, especially about scalability and how to interface with other libraries in production environments.
Our talk was very well received, and we got a lot of great questions, especially about scalability and how to interface with other libraries in production environments.

October 7, 2025 at 2:36 PM
@pydataparis.bsky.social 2025 is over, and it was a big success!
Our talk was very well received, and we got a lot of great questions, especially about scalability and how to interface with other libraries in production environments.
Our talk was very well received, and we got a lot of great questions, especially about scalability and how to interface with other libraries in production environments.
skrub DataOps help you construct complex and extensive hyperparameter search spaces. However, interpreting results from large grids can be challenging.
To address this, skrub generates a parallel coordinate plot that visualizes all runs and the parameters used to achieve specific results.
To address this, skrub generates a parallel coordinate plot that visualizes all runs and the parameters used to achieve specific results.
September 12, 2025 at 12:56 PM
skrub DataOps help you construct complex and extensive hyperparameter search spaces. However, interpreting results from large grids can be challenging.
To address this, skrub generates a parallel coordinate plot that visualizes all runs and the parameters used to achieve specific results.
To address this, skrub generates a parallel coordinate plot that visualizes all runs and the parameters used to achieve specific results.
Do you have to deal with numerical features that involve large outliers, and need to train linear models or neural networks?
Then you might want to try the skrub SquashingScaler. The SquashingScaler behaves like scikit-learn RobustScaler, but smoothly clips outliers to predefined boundaries.
Then you might want to try the skrub SquashingScaler. The SquashingScaler behaves like scikit-learn RobustScaler, but smoothly clips outliers to predefined boundaries.

September 5, 2025 at 8:47 AM
Do you have to deal with numerical features that involve large outliers, and need to train linear models or neural networks?
Then you might want to try the skrub SquashingScaler. The SquashingScaler behaves like scikit-learn RobustScaler, but smoothly clips outliers to predefined boundaries.
Then you might want to try the skrub SquashingScaler. The SquashingScaler behaves like scikit-learn RobustScaler, but smoothly clips outliers to predefined boundaries.
Form complex DataOps plans to train and tune machine learning models, then export the plans as learners, standalone objects that can be used on new data.
Tune hyperparameters where they're defined, and explore the resulting space with a parallel coordinate plot
Tune hyperparameters where they're defined, and explore the resulting space with a parallel coordinate plot
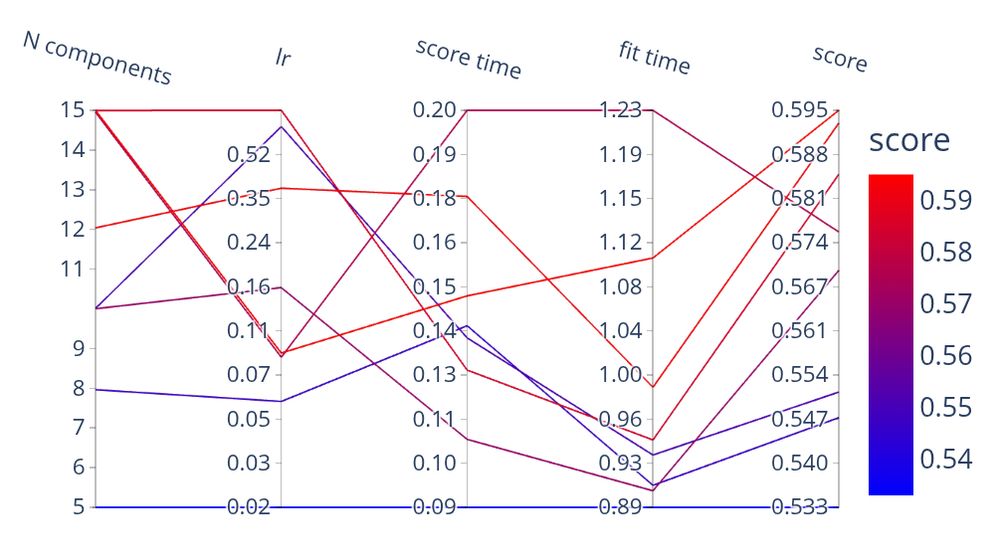
July 24, 2025 at 3:55 PM
Form complex DataOps plans to train and tune machine learning models, then export the plans as learners, standalone objects that can be used on new data.
Tune hyperparameters where they're defined, and explore the resulting space with a parallel coordinate plot
Tune hyperparameters where they're defined, and explore the resulting space with a parallel coordinate plot
🌟 Major feature! Skrub DataOps are a powerful new way of combining dataframe transformations over multiple tables with machine learning pipelines.
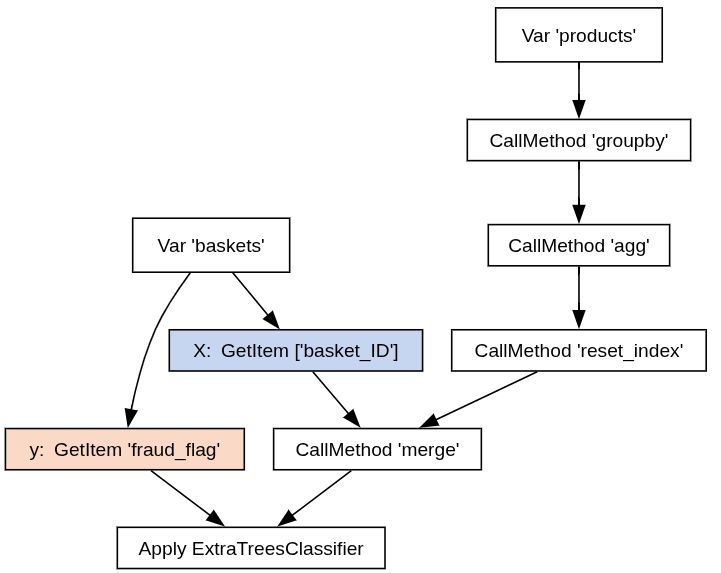
July 24, 2025 at 3:55 PM
🌟 Major feature! Skrub DataOps are a powerful new way of combining dataframe transformations over multiple tables with machine learning pipelines.
⚡ Release 0.6.0 is now out! ⚡
🚀 Major update! Skrub DataOps, various improvements for the TableReport, new tools for applying transformers to the columns, and a new robust transformer for numerical features are only some of the features included in this release.
🚀 Major update! Skrub DataOps, various improvements for the TableReport, new tools for applying transformers to the columns, and a new robust transformer for numerical features are only some of the features included in this release.

July 24, 2025 at 3:55 PM
⚡ Release 0.6.0 is now out! ⚡
🚀 Major update! Skrub DataOps, various improvements for the TableReport, new tools for applying transformers to the columns, and a new robust transformer for numerical features are only some of the features included in this release.
🚀 Major update! Skrub DataOps, various improvements for the TableReport, new tools for applying transformers to the columns, and a new robust transformer for numerical features are only some of the features included in this release.
📅 The skrub API includes various functions and objects that help with dealing with datetime strings. 1/
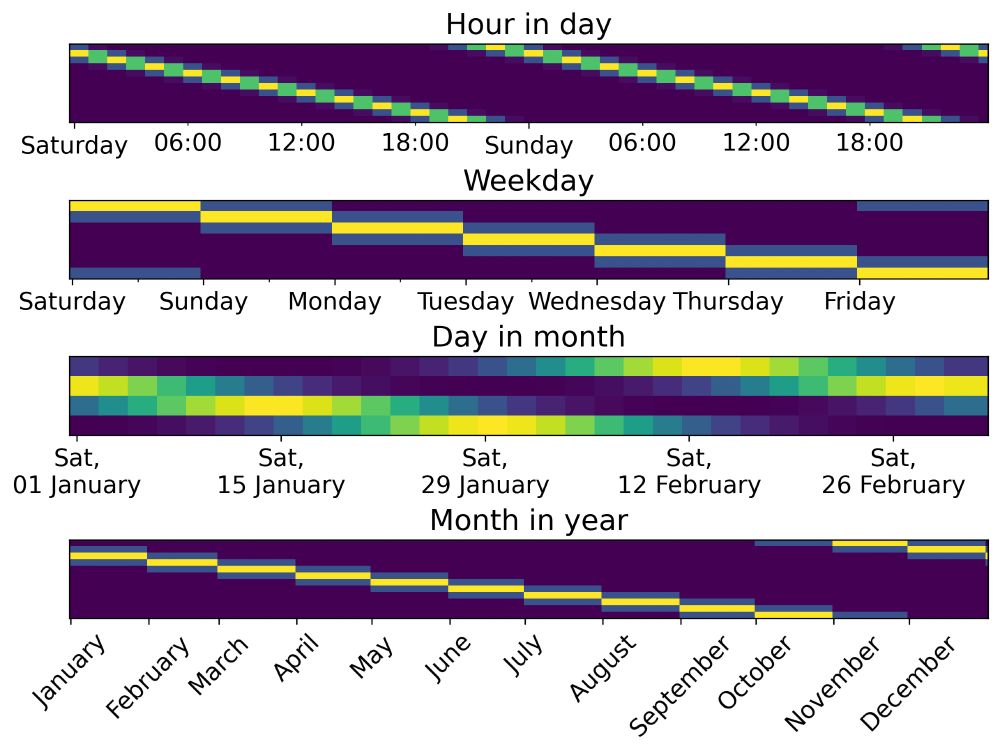
June 19, 2025 at 12:45 PM
📅 The skrub API includes various functions and objects that help with dealing with datetime strings. 1/
Finally, results can be shown with a parallel coordinate plot to find out the impact of different hyperparameters on the prediction task.
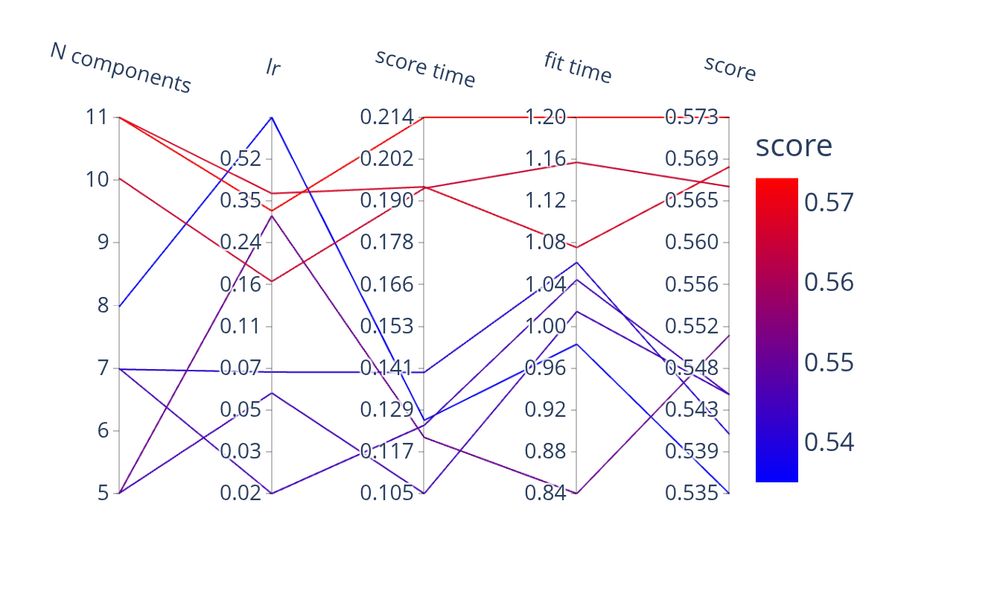
June 4, 2025 at 12:46 PM
Finally, results can be shown with a parallel coordinate plot to find out the impact of different hyperparameters on the prediction task.
👀 This week's post will be another sneak peek into skrub expressions, an upcoming feature that will ease the preparation and execution of machine learning pipelines on dataframes.
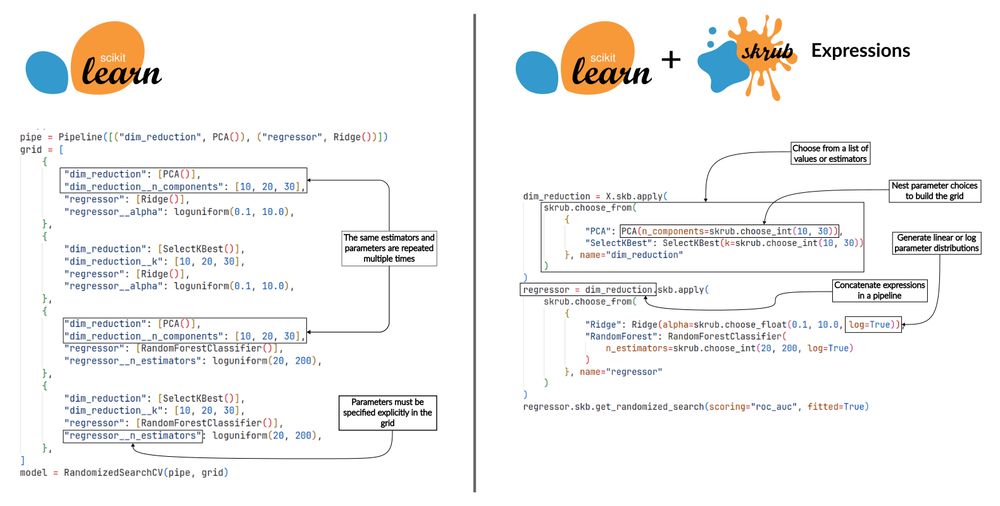
This time we will focus on how expressions can simplify the construction of complex hyperparameter grids.
This time we will focus on how expressions can simplify the construction of complex hyperparameter grids.
June 4, 2025 at 12:46 PM
👀 This week's post will be another sneak peek into skrub expressions, an upcoming feature that will ease the preparation and execution of machine learning pipelines on dataframes.
This time we will focus on how expressions can simplify the construction of complex hyperparameter grids.
This time we will focus on how expressions can simplify the construction of complex hyperparameter grids.
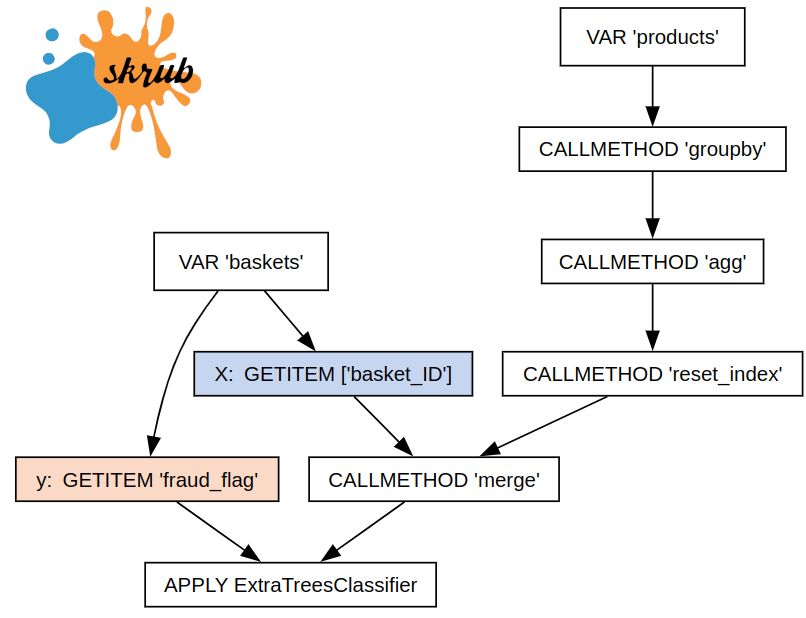
👀 This week's post is a sneak peek into the next major Skrub feature, Skrub expressions 🚀
As this is a preview of an upcoming feature, we are looking for your thoughts and feedback before release.
As this is a preview of an upcoming feature, we are looking for your thoughts and feedback before release.
April 30, 2025 at 10:00 AM
👀 This week's post is a sneak peek into the next major Skrub feature, Skrub expressions 🚀
As this is a preview of an upcoming feature, we are looking for your thoughts and feedback before release.
As this is a preview of an upcoming feature, we are looking for your thoughts and feedback before release.
The Skrub TableReport is a lightweight tool that allows to get a rich overview of a table quickly and easily.
✅ Filter columns
🔎 Look at each column's distribution
📊 Get a high level view of the distributions through stats and plots, including correlated columns
🌐 Export the report as html
✅ Filter columns
🔎 Look at each column's distribution
📊 Get a high level view of the distributions through stats and plots, including correlated columns
🌐 Export the report as html
April 23, 2025 at 11:49 AM
The Skrub TableReport is a lightweight tool that allows to get a rich overview of a table quickly and easily.
✅ Filter columns
🔎 Look at each column's distribution
📊 Get a high level view of the distributions through stats and plots, including correlated columns
🌐 Export the report as html
✅ Filter columns
🔎 Look at each column's distribution
📊 Get a high level view of the distributions through stats and plots, including correlated columns
🌐 Export the report as html
And if you're not familiar with what Skrub is all about, you might want to check out our introductory slide deck here:
skrub-data.org/skrub-materi...
skrub-data.org/skrub-materi...

April 9, 2025 at 9:08 AM
And if you're not familiar with what Skrub is all about, you might want to check out our introductory slide deck here:
skrub-data.org/skrub-materi...
skrub-data.org/skrub-materi...
April 3, 2025 at 4:49 PM
🚀 The Skrub workshop at Campus Cyber in La Défense was a great success! Connecting with professionals from both startups and large companies has given us valuable insights for Skrub's next steps. Stay tuned for more!


January 31, 2025 at 10:38 AM
🚀 The Skrub workshop at Campus Cyber in La Défense was a great success! Connecting with professionals from both startups and large companies has given us valuable insights for Skrub's next steps. Stay tuned for more!
🎉⚡️Release 0.5.1:
◼ Encode strings faster and better with StringEncoder!
StringEncoder applies a tf-idf vectorization followed by SVD to produce high quality and FAST embeddings of textual and categorical features.
◼ Encode strings faster and better with StringEncoder!
StringEncoder applies a tf-idf vectorization followed by SVD to produce high quality and FAST embeddings of textual and categorical features.

January 28, 2025 at 5:19 PM
🎉⚡️Release 0.5.1:
◼ Encode strings faster and better with StringEncoder!
StringEncoder applies a tf-idf vectorization followed by SVD to produce high quality and FAST embeddings of textual and categorical features.
◼ Encode strings faster and better with StringEncoder!
StringEncoder applies a tf-idf vectorization followed by SVD to produce high quality and FAST embeddings of textual and categorical features.
There is much more:
skrub.patch_display() adds the TableReport as a default representation for all dataframes
skrub.column_association to check which columns are linked...
Check out the changelog:
skrub-data.org/stable/CHANG...
skrub.patch_display() adds the TableReport as a default representation for all dataframes
skrub.column_association to check which columns are linked...
Check out the changelog:
skrub-data.org/stable/CHANG...

November 27, 2024 at 8:46 PM
There is much more:
skrub.patch_display() adds the TableReport as a default representation for all dataframes
skrub.column_association to check which columns are linked...
Check out the changelog:
skrub-data.org/stable/CHANG...
skrub.patch_display() adds the TableReport as a default representation for all dataframes
skrub.column_association to check which columns are linked...
Check out the changelog:
skrub-data.org/stable/CHANG...
Improved TableReport:
◼ tighter layout
◼ support any script (any alphabet حب माया) in the plots
◼ robust to outliers
It works without dependencies, in any html-based environment (Jupyter notebooks, @vscode.dev, a simple web page...)
Check it out on skrub-data.org
4/5
◼ tighter layout
◼ support any script (any alphabet حب माया) in the plots
◼ robust to outliers
It works without dependencies, in any html-based environment (Jupyter notebooks, @vscode.dev, a simple web page...)
Check it out on skrub-data.org
4/5

November 27, 2024 at 8:46 PM
Improved TableReport:
◼ tighter layout
◼ support any script (any alphabet حب माया) in the plots
◼ robust to outliers
It works without dependencies, in any html-based environment (Jupyter notebooks, @vscode.dev, a simple web page...)
Check it out on skrub-data.org
4/5
◼ tighter layout
◼ support any script (any alphabet حب माया) in the plots
◼ robust to outliers
It works without dependencies, in any html-based environment (Jupyter notebooks, @vscode.dev, a simple web page...)
Check it out on skrub-data.org
4/5
Skrub can now easily drop columns with too many missing values.
As always the TableVectorizer is very handy for preparation of data-frames, and it now comes with an option to drop those pesky columns
skrub-data.org/stable/refer...
3/5
As always the TableVectorizer is very handy for preparation of data-frames, and it now comes with an option to drop those pesky columns
skrub-data.org/stable/refer...
3/5

November 27, 2024 at 8:46 PM
Skrub can now easily drop columns with too many missing values.
As always the TableVectorizer is very handy for preparation of data-frames, and it now comes with an option to drop those pesky columns
skrub-data.org/stable/refer...
3/5
As always the TableVectorizer is very handy for preparation of data-frames, and it now comes with an option to drop those pesky columns
skrub-data.org/stable/refer...
3/5
Easily combine deep learning (language models on huggingface @hf.co ) for text entries with @scikit-learn.bsky.social gradient-boosted trees
for pipelines that predict great on dataframes of mixed types.
Skrub ensure the language model is downloaded, cached, picklable, everything for easy ops
2/5
for pipelines that predict great on dataframes of mixed types.
Skrub ensure the language model is downloaded, cached, picklable, everything for easy ops
2/5

November 27, 2024 at 8:46 PM
Easily combine deep learning (language models on huggingface @hf.co ) for text entries with @scikit-learn.bsky.social gradient-boosted trees
for pipelines that predict great on dataframes of mixed types.
Skrub ensure the language model is downloaded, cached, picklable, everything for easy ops
2/5
for pipelines that predict great on dataframes of mixed types.
Skrub ensure the language model is downloaded, cached, picklable, everything for easy ops
2/5
🎉⚡️Release 0.4:
◼ Easily use deep learning for text entries
◼ TableVectorizer can remove columns with too many missing values
◼ TableReport more robust and prettier
...
1/5
◼ Easily use deep learning for text entries
◼ TableVectorizer can remove columns with too many missing values
◼ TableReport more robust and prettier
...
1/5

November 27, 2024 at 8:46 PM
🎉⚡️Release 0.4:
◼ Easily use deep learning for text entries
◼ TableVectorizer can remove columns with too many missing values
◼ TableReport more robust and prettier
...
1/5
◼ Easily use deep learning for text entries
◼ TableVectorizer can remove columns with too many missing values
◼ TableReport more robust and prettier
...
1/5
👀 Explore your dataframes interactively with TableReport.
AKA: 📈 we heard you liked plots so we put plots in your tables 📈
AKA: 📈 we heard you liked plots so we put plots in your tables 📈
November 19, 2024 at 3:33 PM
👀 Explore your dataframes interactively with TableReport.
AKA: 📈 we heard you liked plots so we put plots in your tables 📈
AKA: 📈 we heard you liked plots so we put plots in your tables 📈
📆 Encode text and high cardinality categorical data with the GapEncoder and MinHashEncoder, and extract features from dates with the DatetimeEncoder.

November 19, 2024 at 3:33 PM
📆 Encode text and high cardinality categorical data with the GapEncoder and MinHashEncoder, and extract features from dates with the DatetimeEncoder.
🔬 Create strong scikit-learn pipeline baselines effortlessly with TableVectorizer and tabular_learner.

November 19, 2024 at 3:33 PM
🔬 Create strong scikit-learn pipeline baselines effortlessly with TableVectorizer and tabular_learner.