



Shauli Ravfogel
@shauli.bsky.social
Faculty fellow at NYU CDS. Previously: PhD @ BIU NLP.
Are there existing theories that explain the subjective aspect of consciousness (“qualia”)? To my understanding most “theories of consciousness” don’t even make an attempt to do so (either aiming to explain other aspects of consciousness, or claiming that qualia doesn’t “really” exist, etc)
November 2, 2025 at 2:15 AM
Are there existing theories that explain the subjective aspect of consciousness (“qualia”)? To my understanding most “theories of consciousness” don’t even make an attempt to do so (either aiming to explain other aspects of consciousness, or claiming that qualia doesn’t “really” exist, etc)
These findings show, at best, that training data can make an LM act as if it has conscious experience (unsurprising). They don’t support the claim that the model actually has subjective experience, because no mechanistic intervention can establish that (in think you’re already hinting toward this).
November 1, 2025 at 3:26 PM
These findings show, at best, that training data can make an LM act as if it has conscious experience (unsurprising). They don’t support the claim that the model actually has subjective experience, because no mechanistic intervention can establish that (in think you’re already hinting toward this).
Beyond truth-encoding, toy models can be adopted to study other fascinating phenomena, like representation of other concepts in transformers, and the way models utilize the structure of their representations to develop nontrivial capabilities. Arxiv: arxiv.org/pdf/2510.15804
arxiv.org
October 24, 2025 at 3:19 PM
Beyond truth-encoding, toy models can be adopted to study other fascinating phenomena, like representation of other concepts in transformers, and the way models utilize the structure of their representations to develop nontrivial capabilities. Arxiv: arxiv.org/pdf/2510.15804
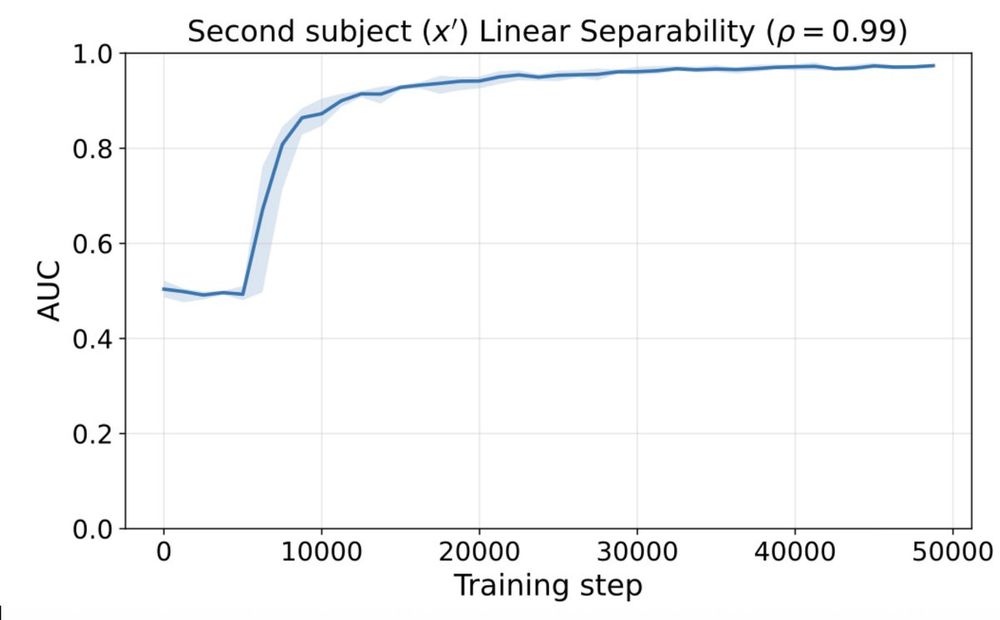
We show that a similar phenomenon is reproduced when using natural language data, instead of our synthetic data, although in “real”, pretrained LMs, the layer normalization doesn’t seem to play such an important role in inducing linear separability.
October 24, 2025 at 3:19 PM
We show that a similar phenomenon is reproduced when using natural language data, instead of our synthetic data, although in “real”, pretrained LMs, the layer normalization doesn’t seem to play such an important role in inducing linear separability.
*Assuming* this structure, we prove that (1) the model represents truth linearly; (2) confidence on the false sequence is decreased. This mechanism relies on a difference in norm between true and false sequence, that the layer normalization translates to linear separability.
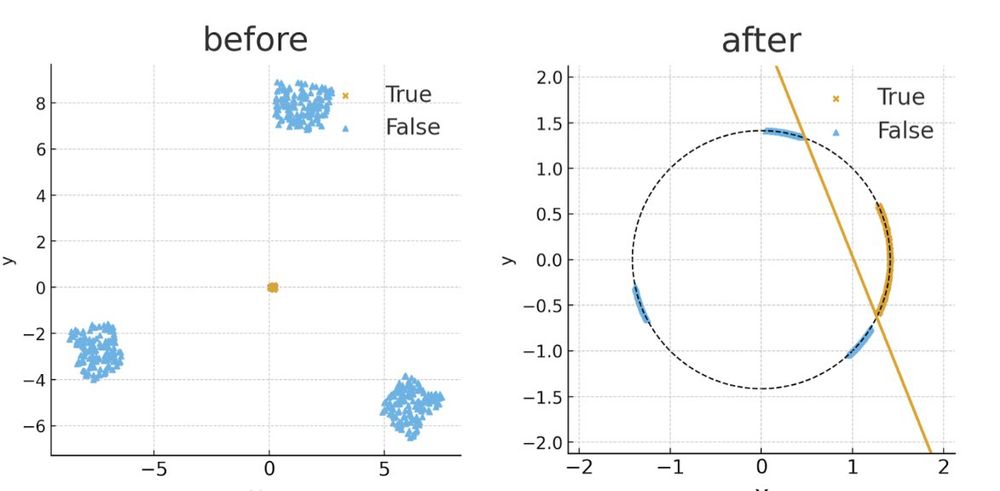
October 24, 2025 at 3:19 PM
*Assuming* this structure, we prove that (1) the model represents truth linearly; (2) confidence on the false sequence is decreased. This mechanism relies on a difference in norm between true and false sequence, that the layer normalization translates to linear separability.
An analysis of the first gradient steps also predicts the gradual emergence of this structure, with the block corresponding to memorization appearing first, followed by the block that gives rise to linear separability and confidence modulation.

October 24, 2025 at 3:19 PM
An analysis of the first gradient steps also predicts the gradual emergence of this structure, with the block corresponding to memorization appearing first, followed by the block that gives rise to linear separability and confidence modulation.
To understand the emergence, we study the structure of the attention matrix. It turns out that it is highly structured, with blocks corresponding to mapping subjects to attributes (lower left), attributes to subjects (upper middle), and additional ones.
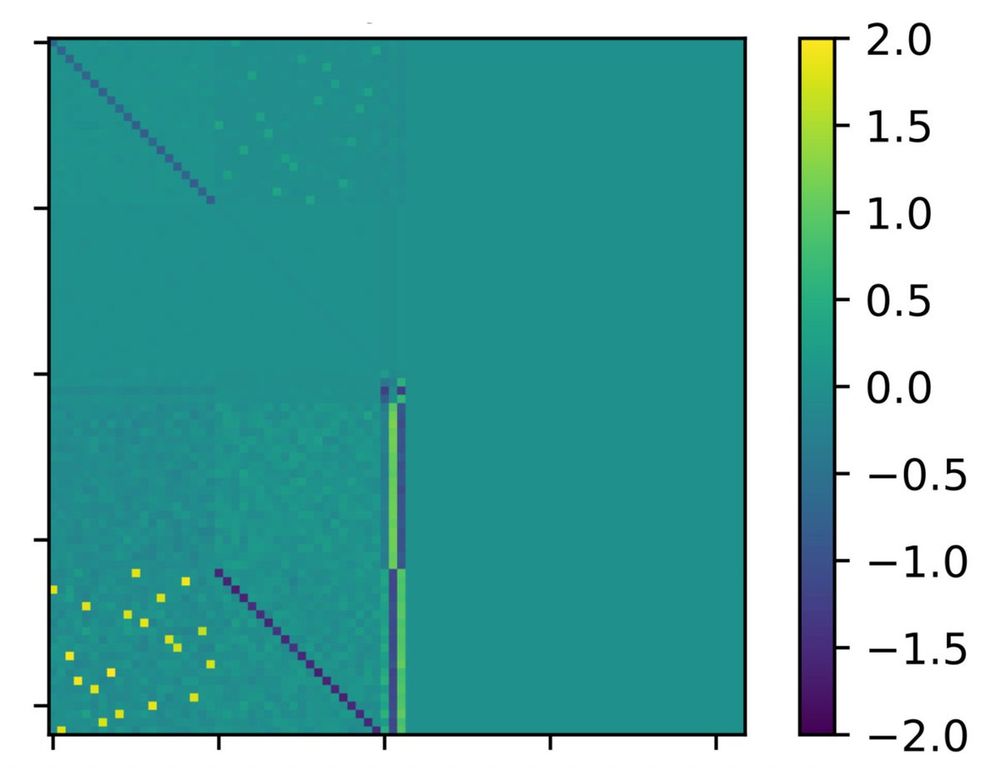
October 24, 2025 at 3:19 PM
To understand the emergence, we study the structure of the attention matrix. It turns out that it is highly structured, with blocks corresponding to mapping subjects to attributes (lower left), attributes to subjects (upper middle), and additional ones.
False sequences contain a uniform attribute (instead of the memorized one), so the ideal behavior on them is to output a uniform guess. We see that the probability the model allocates to the memorized attribute starts dropping *exactly* when the linear truth signal emerges.

October 24, 2025 at 3:19 PM
False sequences contain a uniform attribute (instead of the memorized one), so the ideal behavior on them is to output a uniform guess. We see that the probability the model allocates to the memorized attribute starts dropping *exactly* when the linear truth signal emerges.
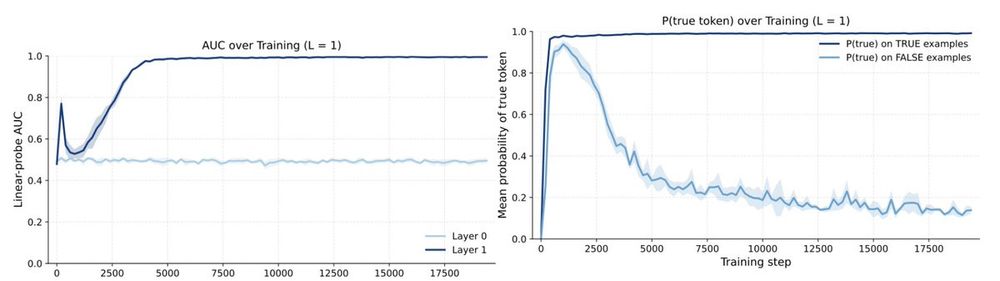
We train a simplified transformer model on this task, with a single layer and a single attention head. We see an abrupt emergence of linear separability of the hidden representations by factuality.
October 24, 2025 at 3:19 PM
We train a simplified transformer model on this task, with a single layer and a single attention head. We see an abrupt emergence of linear separability of the hidden representations by factuality.
We start with a “truth co-occurrence" hypothesis: false assertions tend to co-occur. Thus, LMs are incentivized to infer the truth latent variable to reduce future loss. We define a factual recall task, where each instance contains two sequences, whose truthfulness correlates.

October 24, 2025 at 3:19 PM
We start with a “truth co-occurrence" hypothesis: false assertions tend to co-occur. Thus, LMs are incentivized to infer the truth latent variable to reduce future loss. We define a factual recall task, where each instance contains two sequences, whose truthfulness correlates.
8/8 We advocate moving from benchmark- to skill-centric evaluation. Modeling latent structure clarifies strengths and gaps in evaluation, guiding dataset design and LLM development.
Shout-out to the first author Aviya Maimon for her principled, and at times painstaking, work!
Shout-out to the first author Aviya Maimon for her principled, and at times painstaking, work!
July 31, 2025 at 12:37 PM
8/8 We advocate moving from benchmark- to skill-centric evaluation. Modeling latent structure clarifies strengths and gaps in evaluation, guiding dataset design and LLM development.
Shout-out to the first author Aviya Maimon for her principled, and at times painstaking, work!
Shout-out to the first author Aviya Maimon for her principled, and at times painstaking, work!
7/8 This factor space lets us (i) flag benchmarks that add little new information, (ii) predict a new model’s full profile from a small task subset, and (iii) choose the best model for an unseen task with minimal trials.

July 31, 2025 at 12:37 PM
7/8 This factor space lets us (i) flag benchmarks that add little new information, (ii) predict a new model’s full profile from a small task subset, and (iii) choose the best model for an unseen task with minimal trials.
6/8 From this analysis, eight main latent skills emerge—e.g., General NLU, Long-document comprehension, Precision-sensitive answers—allowing each model to receive a more fine-grained skill profile instead of one aggregated number.

July 31, 2025 at 12:37 PM
6/8 From this analysis, eight main latent skills emerge—e.g., General NLU, Long-document comprehension, Precision-sensitive answers—allowing each model to receive a more fine-grained skill profile instead of one aggregated number.
5/8 Using Principal-Axis Factoring, we separate shared variance (true shared skills) from task-specific noise, yielding an interpretable low-dimensional latent space.

July 31, 2025 at 12:37 PM
5/8 Using Principal-Axis Factoring, we separate shared variance (true shared skills) from task-specific noise, yielding an interpretable low-dimensional latent space.
4/8 We built a 60-model × 44-task performance matrix, harmonizing diverse metrics onto a 0–10 scale. This sets our empirical foundation for the analysis. Our goal is to identify a small set of underlying latent model capabilities that explain these scores in a data-drive way.
July 31, 2025 at 12:37 PM
4/8 We built a 60-model × 44-task performance matrix, harmonizing diverse metrics onto a 0–10 scale. This sets our empirical foundation for the analysis. Our goal is to identify a small set of underlying latent model capabilities that explain these scores in a data-drive way.
3/8 Drawing on psychometrics, we treat every benchmark item as a test question and apply Exploratory Factor Analysis to uncover the latent abilities those tasks only approximate.
July 31, 2025 at 12:37 PM
3/8 Drawing on psychometrics, we treat every benchmark item as a test question and apply Exploratory Factor Analysis to uncover the latent abilities those tasks only approximate.
2/8 Today’s practice relies on partially redundant benchmarks that aim to measure latent, underlying capabilities. Evaluation usually collapses them into a single average, obscuring a model’s real strengths and weaknesses.
July 31, 2025 at 12:37 PM
2/8 Today’s practice relies on partially redundant benchmarks that aim to measure latent, underlying capabilities. Evaluation usually collapses them into a single average, obscuring a model’s real strengths and weaknesses.
There's still more to explore—especially in making the reconstruction process more faithful and generalizable across data distributions—but we see this as a promising step toward improving the interpretability of interventions in natural language.
Arxiv: arxiv.org/pdf/2402.11355 (6/6)
Arxiv: arxiv.org/pdf/2402.11355 (6/6)
arxiv.org
February 12, 2025 at 3:19 PM
There's still more to explore—especially in making the reconstruction process more faithful and generalizable across data distributions—but we see this as a promising step toward improving the interpretability of interventions in natural language.
Arxiv: arxiv.org/pdf/2402.11355 (6/6)
Arxiv: arxiv.org/pdf/2402.11355 (6/6)