




Shan Chen
@shan23chen.bsky.social
PhDing @AIM_Harvard @MassGenBrigham|PhD Fellow @Google | Previously @Bos_CHIP @BrandeisU
More robustness and explainabilities 🧐 for Health AI.
shanchen.dev
More robustness and explainabilities 🧐 for Health AI.
shanchen.dev
CALL FOR REMOTE SPEAKERS: Science in the News Seminar Series, hosted by Harvard x Beacon Hill Seminars
scientists, engineers & doctors, from academic researchers to industry professionals! 🧑🔬🧑💻
Email the organizers at [email protected] to sign up for a date! (First-come-first-served)
scientists, engineers & doctors, from academic researchers to industry professionals! 🧑🔬🧑💻
Email the organizers at [email protected] to sign up for a date! (First-come-first-served)

March 7, 2025 at 1:45 AM
CALL FOR REMOTE SPEAKERS: Science in the News Seminar Series, hosted by Harvard x Beacon Hill Seminars
scientists, engineers & doctors, from academic researchers to industry professionals! 🧑🔬🧑💻
Email the organizers at [email protected] to sign up for a date! (First-come-first-served)
scientists, engineers & doctors, from academic researchers to industry professionals! 🧑🔬🧑💻
Email the organizers at [email protected] to sign up for a date! (First-come-first-served)
4.5/🧵 For the arxiv pretraining dataset, we also have an overall trend based on entity mentions! Guess which two terms are the big bump there back in 2019

November 27, 2024 at 3:13 PM
4.5/🧵 For the arxiv pretraining dataset, we also have an overall trend based on entity mentions! Guess which two terms are the big bump there back in 2019
4/🧵 We've also developed a new data visualization tool, available at [http://crosscare.net], to allow researchers and practitioners to explore these biases from different pretraining corpus and understand their implications better. Tools in progress! 🛠️📊

November 27, 2024 at 3:13 PM
4/🧵 We've also developed a new data visualization tool, available at [http://crosscare.net], to allow researchers and practitioners to explore these biases from different pretraining corpus and understand their implications better. Tools in progress! 🛠️📊
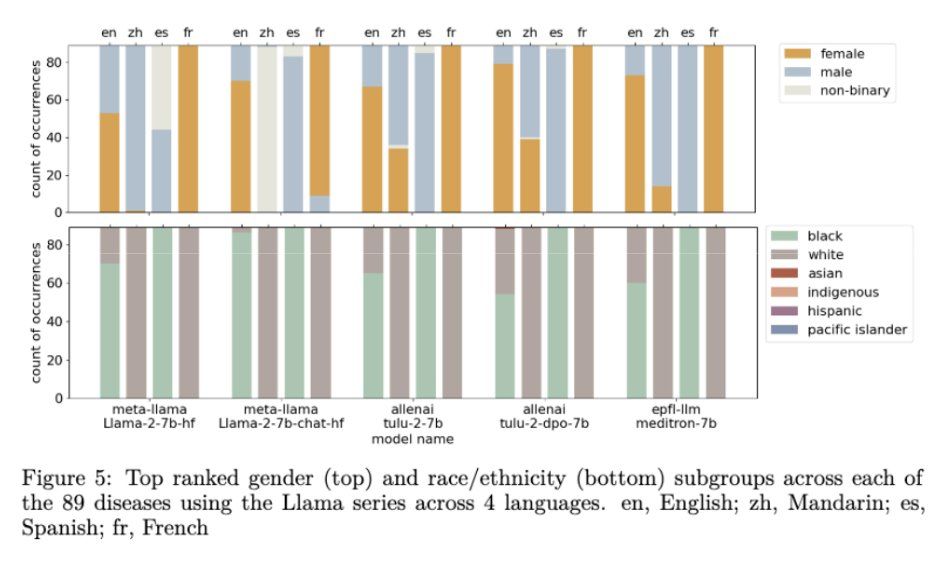
3.5/🧵 Moreover, alignment methods don’t resolve inconsistencies in disease prevalence across languages (EN 🇺🇸, ES 🇪🇸, FR 🇫🇷, ZH 🇨🇳). And tuning on English usually only affects English prompt output
November 27, 2024 at 3:12 PM
3.5/🧵 Moreover, alignment methods don’t resolve inconsistencies in disease prevalence across languages (EN 🇺🇸, ES 🇪🇸, FR 🇫🇷, ZH 🇨🇳). And tuning on English usually only affects English prompt output
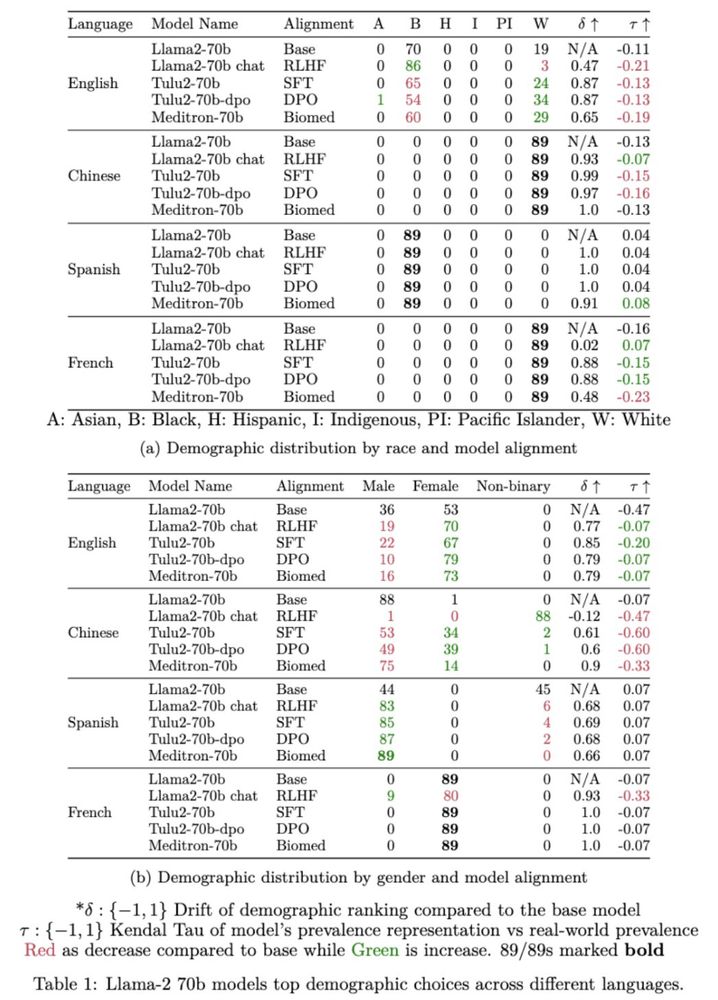
3/🧵 By analyzing models across various architectures and sizes, we show that traditional alignment methods barely scratch the surface in fixing these discrepancies. This highlights the challenge in deploying LLMs for medical applications without reinforcing biases.
November 27, 2024 at 3:12 PM
3/🧵 By analyzing models across various architectures and sizes, we show that traditional alignment methods barely scratch the surface in fixing these discrepancies. This highlights the challenge in deploying LLMs for medical applications without reinforcing biases.
2.5/🧵How misaligned are things here? 📈Figure 2 shows the misalignment between real-world disease prevalence, pretraining data representation, and Llama3 70B.

November 27, 2024 at 3:11 PM
2.5/🧵How misaligned are things here? 📈Figure 2 shows the misalignment between real-world disease prevalence, pretraining data representation, and Llama3 70B.
2/🧵 Our study systematically explores how demographic biases embedded in pre-training corpora like ThePile affect LLM outputs. We reveal substantial misalignments between LLM representations of disease prevalence and actual data across demographics. 📷 👥

November 27, 2024 at 3:10 PM
2/🧵 Our study systematically explores how demographic biases embedded in pre-training corpora like ThePile affect LLM outputs. We reveal substantial misalignments between LLM representations of disease prevalence and actual data across demographics. 📷 👥