



Sham Kakade
@shamkakade.bsky.social
(5/n) 🤝 Shoutout to some great collaborators:
@hanlin_zhang, @depen_morwani, @vyasnikhil96, @uuujingfeng, @difanzou, @udayaghai
#AI #ML #ScalingLaws
@hanlin_zhang, @depen_morwani, @vyasnikhil96, @uuujingfeng, @difanzou, @udayaghai
#AI #ML #ScalingLaws
November 22, 2024 at 8:19 PM
(5/n) 🤝 Shoutout to some great collaborators:
@hanlin_zhang, @depen_morwani, @vyasnikhil96, @uuujingfeng, @difanzou, @udayaghai
#AI #ML #ScalingLaws
@hanlin_zhang, @depen_morwani, @vyasnikhil96, @uuujingfeng, @difanzou, @udayaghai
#AI #ML #ScalingLaws
(4/n) 🧠 Want theory? We provide rigorous justifications, provide critical hyperparameters, and characterize lr decay to the overtraining regime.
Check out the details here:
📄 arxiv.org/abs/2410.21676
📝 Blog: tinyurl.com/ysufbwsr
Check out the details here:
📄 arxiv.org/abs/2410.21676
📝 Blog: tinyurl.com/ysufbwsr

How Does Critical Batch Size Scale in Pre-training?
Training large-scale models under given resources requires careful design of parallelism strategies. In particular, the efficiency notion of critical batch size (CBS), concerning the compromise betwee...
arxiv.org
November 22, 2024 at 8:19 PM
(4/n) 🧠 Want theory? We provide rigorous justifications, provide critical hyperparameters, and characterize lr decay to the overtraining regime.
Check out the details here:
📄 arxiv.org/abs/2410.21676
📝 Blog: tinyurl.com/ysufbwsr
Check out the details here:
📄 arxiv.org/abs/2410.21676
📝 Blog: tinyurl.com/ysufbwsr
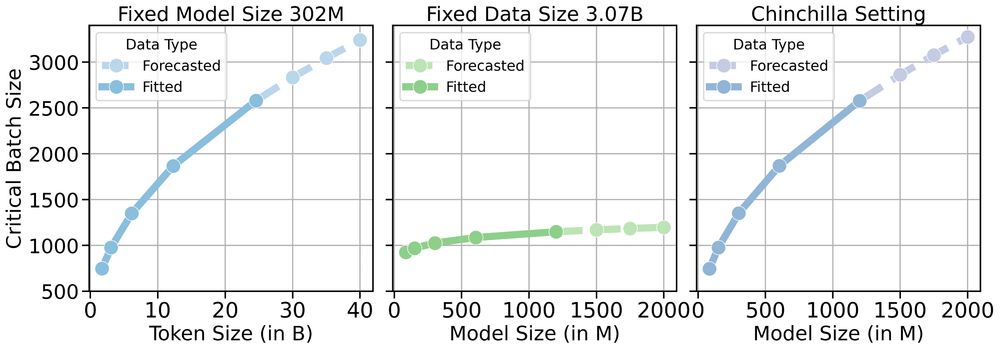
(3/n) 📊 From our controlled experiments on language models:
📈CBS increases as dataset size grows
🤏CBS remains weakly dependent on model size
Data size, not model size, drives parallel efficiency for large-scale pre-training.
📈CBS increases as dataset size grows
🤏CBS remains weakly dependent on model size
Data size, not model size, drives parallel efficiency for large-scale pre-training.
November 22, 2024 at 8:19 PM
(3/n) 📊 From our controlled experiments on language models:
📈CBS increases as dataset size grows
🤏CBS remains weakly dependent on model size
Data size, not model size, drives parallel efficiency for large-scale pre-training.
📈CBS increases as dataset size grows
🤏CBS remains weakly dependent on model size
Data size, not model size, drives parallel efficiency for large-scale pre-training.
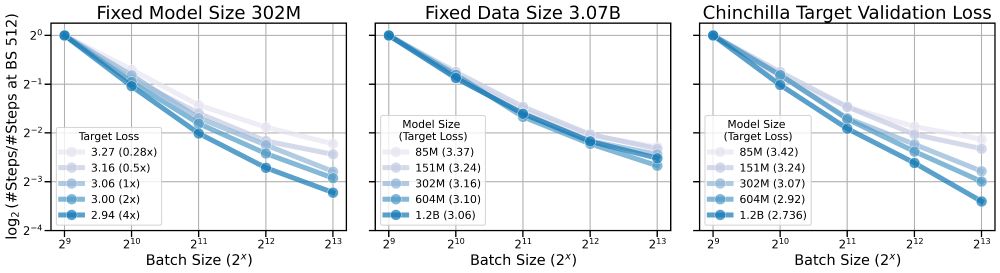
(2/n) 🤔 How does CBS scale with model size and data size in pre-training? We find that CBS scales with data size and is largely invariant to model size. Prior beliefs that CBS scales with model size may have stemmed from Chinchilla’s coupled N-D scaling.
November 22, 2024 at 8:19 PM
(2/n) 🤔 How does CBS scale with model size and data size in pre-training? We find that CBS scales with data size and is largely invariant to model size. Prior beliefs that CBS scales with model size may have stemmed from Chinchilla’s coupled N-D scaling.