



Sander Dieleman
@sedielem.bsky.social
Blog: https://sander.ai/
🐦: https://x.com/sedielem
Research Scientist at Google DeepMind (WaveNet, Imagen 3, Veo, ...). I tweet about deep learning (research + software), music, generative models (personal account).
🐦: https://x.com/sedielem
Research Scientist at Google DeepMind (WaveNet, Imagen 3, Veo, ...). I tweet about deep learning (research + software), music, generative models (personal account).
Pinned
Sander Dieleman
@sedielem.bsky.social
· Apr 15

Generative modelling in latent space
Latent representations for generative models.
sander.ai
New blog post: let's talk about latents!
sander.ai/2025/04/15/l...
sander.ai/2025/04/15/l...
Great blog post on rotary position embeddings (RoPE) in more than one dimension, with interactive visualisations, a bunch of experimental results, and code!
On N-dimensional Rotary Positional Embeddings
An exploration of N-dimensional rotary positional embeddings (RoPE) for vision transformers.
jerryxio.ng
July 28, 2025 at 2:51 PM
Great blog post on rotary position embeddings (RoPE) in more than one dimension, with interactive visualisations, a bunch of experimental results, and code!
I blog and give talks to help build people's intuition for diffusion models. YouTubers like @3blue1brown.com and Welch Labs have been a huge inspiration: their ability to make complex ideas in maths and physics approachable is unmatched. Really great to see them tackle this topic!

New video on the details of diffusion models: youtu.be/iv-5mZ_9CPY
Produced by Welch Labs, this is the first in a short series of 3b1b this summer. I enjoyed providing editorial feedback throughout the last several months, and couldn't be happier with the result.
Produced by Welch Labs, this is the first in a short series of 3b1b this summer. I enjoyed providing editorial feedback throughout the last several months, and couldn't be happier with the result.

But how do AI videos actually work? | Guest video by @WelchLabsVideo
YouTube video by 3Blue1Brown
youtu.be
July 26, 2025 at 9:59 PM
I blog and give talks to help build people's intuition for diffusion models. YouTubers like @3blue1brown.com and Welch Labs have been a huge inspiration: their ability to make complex ideas in maths and physics approachable is unmatched. Really great to see them tackle this topic!
Hello #ICML2025👋, anyone up for a diffusion circle? We'll just sit down somewhere and talk shop.
🕒Join us at 3PM on Thursday July 17. We'll meet here (see photo, near the west building's west entrance), and venture out from there to find a good spot to sit. Tell your friends!
🕒Join us at 3PM on Thursday July 17. We'll meet here (see photo, near the west building's west entrance), and venture out from there to find a good spot to sit. Tell your friends!

July 15, 2025 at 9:34 PM
Hello #ICML2025👋, anyone up for a diffusion circle? We'll just sit down somewhere and talk shop.
🕒Join us at 3PM on Thursday July 17. We'll meet here (see photo, near the west building's west entrance), and venture out from there to find a good spot to sit. Tell your friends!
🕒Join us at 3PM on Thursday July 17. We'll meet here (see photo, near the west building's west entrance), and venture out from there to find a good spot to sit. Tell your friends!
Diffusion models have analytical solutions, but they involve sums over the entire training set, and they don't generalise at all. They are mainly useful to help us understand how practical diffusion models generalise.
Nice blog + code by Raymond Fan: rfangit.github.io/blog/2025/op...
Nice blog + code by Raymond Fan: rfangit.github.io/blog/2025/op...

July 5, 2025 at 4:01 PM
Diffusion models have analytical solutions, but they involve sums over the entire training set, and they don't generalise at all. They are mainly useful to help us understand how practical diffusion models generalise.
Nice blog + code by Raymond Fan: rfangit.github.io/blog/2025/op...
Nice blog + code by Raymond Fan: rfangit.github.io/blog/2025/op...
Here's the third and final part of Slater Stich's "History of diffusion" interview series!
The other two interviewees' research played a pivotal role in the rise of diffusion models, whereas I just like to yap about them 😬 this was a wonderful opportunity to do exactly that!
The other two interviewees' research played a pivotal role in the rise of diffusion models, whereas I just like to yap about them 😬 this was a wonderful opportunity to do exactly that!

History of Diffusion - Sander Dieleman
YouTube video by Bain Capital Ventures
www.youtube.com
May 14, 2025 at 4:11 PM
Here's the third and final part of Slater Stich's "History of diffusion" interview series!
The other two interviewees' research played a pivotal role in the rise of diffusion models, whereas I just like to yap about them 😬 this was a wonderful opportunity to do exactly that!
The other two interviewees' research played a pivotal role in the rise of diffusion models, whereas I just like to yap about them 😬 this was a wonderful opportunity to do exactly that!
The ML for audio 🗣️🎵🔊 workshop is back at ICML 2025 in Vancouver! It will take place on Saturday, July 19. Featuring invited talks from Dan Ellis, Albert Gu, James Betker, Laura Laurenti and Pratyusha Sharma.
Submission deadline: May 23 (Friday next week)
mlforaudioworkshop.github.io
Submission deadline: May 23 (Friday next week)
mlforaudioworkshop.github.io
[“Machine Learning for Audio Workshop”]
[“Discover the harmony of AI and sound.”]
mlforaudioworkshop.github.io
May 14, 2025 at 12:16 PM
The ML for audio 🗣️🎵🔊 workshop is back at ICML 2025 in Vancouver! It will take place on Saturday, July 19. Featuring invited talks from Dan Ellis, Albert Gu, James Betker, Laura Laurenti and Pratyusha Sharma.
Submission deadline: May 23 (Friday next week)
mlforaudioworkshop.github.io
Submission deadline: May 23 (Friday next week)
mlforaudioworkshop.github.io
Reposted by Sander Dieleman

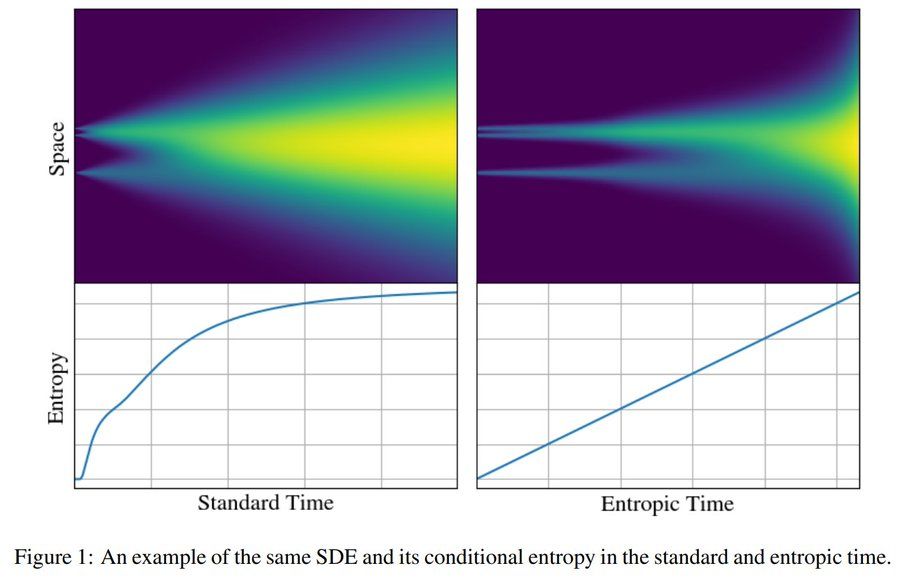
I am very happy to share our latest work on the information theory of generative diffusion:
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
April 29, 2025 at 1:17 PM
I am very happy to share our latest work on the information theory of generative diffusion:
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
One weird trick for better diffusion models: concatenate some DINOv2 features to your latent channels!
Combining latents with PCA components extracted from DINOv2 features yields faster training and better samples. Also enables a new guidance strategy. Simple and effective!
Combining latents with PCA components extracted from DINOv2 features yields faster training and better samples. Also enables a new guidance strategy. Simple and effective!

1/n Introducing ReDi (Representation Diffusion): a new generative approach that leverages a diffusion model to jointly capture
– Low-level image details (via VAE latents)
– High-level semantic features (via DINOv2)🧵
– Low-level image details (via VAE latents)
– High-level semantic features (via DINOv2)🧵

April 25, 2025 at 1:03 PM
One weird trick for better diffusion models: concatenate some DINOv2 features to your latent channels!
Combining latents with PCA components extracted from DINOv2 features yields faster training and better samples. Also enables a new guidance strategy. Simple and effective!
Combining latents with PCA components extracted from DINOv2 features yields faster training and better samples. Also enables a new guidance strategy. Simple and effective!
New blog post: let's talk about latents!
sander.ai/2025/04/15/l...
sander.ai/2025/04/15/l...
Generative modelling in latent space
Latent representations for generative models.
sander.ai
April 15, 2025 at 9:40 AM
New blog post: let's talk about latents!
sander.ai/2025/04/15/l...
sander.ai/2025/04/15/l...
Amazing interview with Yang Song, one of the key researchers we have to thank for diffusion models.
The most important lesson: be fearless! The community's view on score matching was quite pessimistic at the time, he went against the grain and made it work at scale!
www.youtube.com/watch?v=ud6z...
The most important lesson: be fearless! The community's view on score matching was quite pessimistic at the time, he went against the grain and made it work at scale!
www.youtube.com/watch?v=ud6z...

History of Diffusion - Yang Song
YouTube video by Bain Capital Ventures
www.youtube.com
April 14, 2025 at 4:47 PM
Amazing interview with Yang Song, one of the key researchers we have to thank for diffusion models.
The most important lesson: be fearless! The community's view on score matching was quite pessimistic at the time, he went against the grain and made it work at scale!
www.youtube.com/watch?v=ud6z...
The most important lesson: be fearless! The community's view on score matching was quite pessimistic at the time, he went against the grain and made it work at scale!
www.youtube.com/watch?v=ud6z...
Reposted by Sander Dieleman

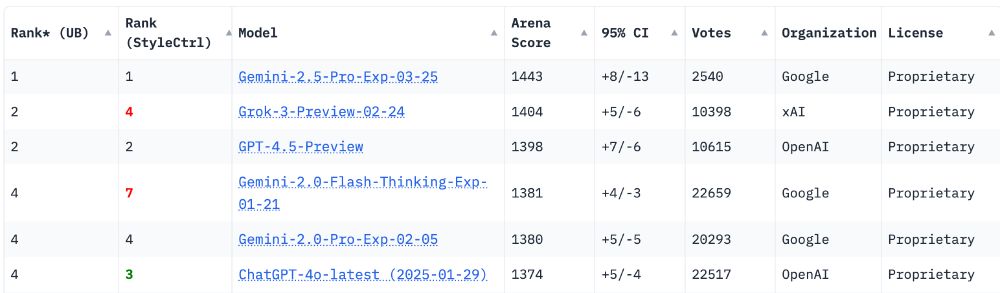
🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇

March 25, 2025 at 5:25 PM
🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
We are hiring on the Generative Media team in London: boards.greenhouse.io/deepmind/job...
We work on Imagen, Veo, Lyria and all that good stuff. Come work with us! If you're interested, apply before Feb 28.
We work on Imagen, Veo, Lyria and all that good stuff. Come work with us! If you're interested, apply before Feb 28.

Research Scientist, Generative Media
London, UK
boards.greenhouse.io
February 21, 2025 at 7:00 PM
We are hiring on the Generative Media team in London: boards.greenhouse.io/deepmind/job...
We work on Imagen, Veo, Lyria and all that good stuff. Come work with us! If you're interested, apply before Feb 28.
We work on Imagen, Veo, Lyria and all that good stuff. Come work with us! If you're interested, apply before Feb 28.
Great interview with @jascha.sohldickstein.com about diffusion models! This is the first in a series: similar interviews with Yang Song and yours truly will follow soon.
(One of these is not like the others -- both of them basically invented the field, and I occasionally write a blog post 🥲)
(One of these is not like the others -- both of them basically invented the field, and I occasionally write a blog post 🥲)

History of Diffusion - Jascha Sohl-Dickstein
YouTube video by Bain Capital Ventures
www.youtube.com
February 10, 2025 at 10:28 PM
Great interview with @jascha.sohldickstein.com about diffusion models! This is the first in a series: similar interviews with Yang Song and yours truly will follow soon.
(One of these is not like the others -- both of them basically invented the field, and I occasionally write a blog post 🥲)
(One of these is not like the others -- both of them basically invented the field, and I occasionally write a blog post 🥲)
📢PSA: #NeurIPS2024 recordings are now publicly available!
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
January 22, 2025 at 9:04 PM
📢PSA: #NeurIPS2024 recordings are now publicly available!
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
Why do diffusion models generalise at all? It's not obvious that they would. It turns out underfitting plays an important role, as well as the architectural inductive biases of locality and translation equivariance. What other kinds of symmetry and structure could we hardcode? 🤔

Excited to finally share this work w/ @suryaganguli.bsky.social Tl;dr: we find the first closed-form analytical theory that replicates the outputs of the very simplest diffusion models, with median pixel wise r^2 values of 90%+. arxiv.org/abs/2412.20292

January 1, 2025 at 12:26 PM
Why do diffusion models generalise at all? It's not obvious that they would. It turns out underfitting plays an important role, as well as the architectural inductive biases of locality and translation equivariance. What other kinds of symmetry and structure could we hardcode? 🤔
Reposted by Sander Dieleman

I ran across a busy Sander at a #neurips party with a similar question - he was still patient enough to explain stuff. This talk further clarifies a good amount of my doubts. Recommend watching if you're working on diffusion / LLMs for generation!
I've been getting a lot of questions about autoregression vs diffusion at #NeurIPS2024 this week! I'm speaking at the adaptive foundation models workshop at 9AM tomorrow (West Hall A), about what happens when we combine modalities and modelling paradigms.
adaptive-foundation-models.org
adaptive-foundation-models.org
NeurIPS 2024 Workshop on Adaptive Foundation Models
adaptive-foundation-models.org
December 25, 2024 at 11:43 PM
I ran across a busy Sander at a #neurips party with a similar question - he was still patient enough to explain stuff. This talk further clarifies a good amount of my doubts. Recommend watching if you're working on diffusion / LLMs for generation!
The recording of my #NeurIPS2024 workshop talk on multimodal iterative refinement is now available to everyone who registered: neurips.cc/virtual/2024...
My talk starts at 1:10:45 into the recording.
I believe this will be made publicly available eventually, but I'm not sure when exactly!
My talk starts at 1:10:45 into the recording.
I believe this will be made publicly available eventually, but I'm not sure when exactly!
December 18, 2024 at 4:38 AM
The recording of my #NeurIPS2024 workshop talk on multimodal iterative refinement is now available to everyone who registered: neurips.cc/virtual/2024...
My talk starts at 1:10:45 into the recording.
I believe this will be made publicly available eventually, but I'm not sure when exactly!
My talk starts at 1:10:45 into the recording.
I believe this will be made publicly available eventually, but I'm not sure when exactly!
Here's Veo 2, the latest version of our video generation model, as well as a substantial upgrade for Imagen 3 🧑🍳🚢
(Did I mention we are hiring on the Generative Media team, btw 👀)
blog.google/technology/g...
(Did I mention we are hiring on the Generative Media team, btw 👀)
blog.google/technology/g...

State-of-the-art video and image generation with Veo 2 and Imagen 3
We’re rolling out a new, state-of-the-art video model, Veo 2, and updates to Imagen 3. Plus, check out our new experiment, Whisk.
blog.google
December 16, 2024 at 5:35 PM
Here's Veo 2, the latest version of our video generation model, as well as a substantial upgrade for Imagen 3 🧑🍳🚢
(Did I mention we are hiring on the Generative Media team, btw 👀)
blog.google/technology/g...
(Did I mention we are hiring on the Generative Media team, btw 👀)
blog.google/technology/g...
I've been getting a lot of questions about autoregression vs diffusion at #NeurIPS2024 this week! I'm speaking at the adaptive foundation models workshop at 9AM tomorrow (West Hall A), about what happens when we combine modalities and modelling paradigms.
adaptive-foundation-models.org
adaptive-foundation-models.org
NeurIPS 2024 Workshop on Adaptive Foundation Models
adaptive-foundation-models.org
December 14, 2024 at 4:02 AM
I've been getting a lot of questions about autoregression vs diffusion at #NeurIPS2024 this week! I'm speaking at the adaptive foundation models workshop at 9AM tomorrow (West Hall A), about what happens when we combine modalities and modelling paradigms.
adaptive-foundation-models.org
adaptive-foundation-models.org
If you're at #NeurIPS2024, join us this afternoon to talk diffusion, flows and all that jazz. Be there or be non-circular!
When a bunch of diffusers sit down and talk shop, their flow cannot be matched😎
It's time for the #NeurIPS2024 diffusion circle!
🕒Join us at 3PM on Friday December 13. We'll meet near this thing, and venture out from there and find a good spot to sit. Tell your friends!
It's time for the #NeurIPS2024 diffusion circle!
🕒Join us at 3PM on Friday December 13. We'll meet near this thing, and venture out from there and find a good spot to sit. Tell your friends!

December 13, 2024 at 6:28 PM
If you're at #NeurIPS2024, join us this afternoon to talk diffusion, flows and all that jazz. Be there or be non-circular!
When a bunch of diffusers sit down and talk shop, their flow cannot be matched😎
It's time for the #NeurIPS2024 diffusion circle!
🕒Join us at 3PM on Friday December 13. We'll meet near this thing, and venture out from there and find a good spot to sit. Tell your friends!
It's time for the #NeurIPS2024 diffusion circle!
🕒Join us at 3PM on Friday December 13. We'll meet near this thing, and venture out from there and find a good spot to sit. Tell your friends!
December 12, 2024 at 1:15 AM
When a bunch of diffusers sit down and talk shop, their flow cannot be matched😎
It's time for the #NeurIPS2024 diffusion circle!
🕒Join us at 3PM on Friday December 13. We'll meet near this thing, and venture out from there and find a good spot to sit. Tell your friends!
It's time for the #NeurIPS2024 diffusion circle!
🕒Join us at 3PM on Friday December 13. We'll meet near this thing, and venture out from there and find a good spot to sit. Tell your friends!
Reposted by Sander Dieleman

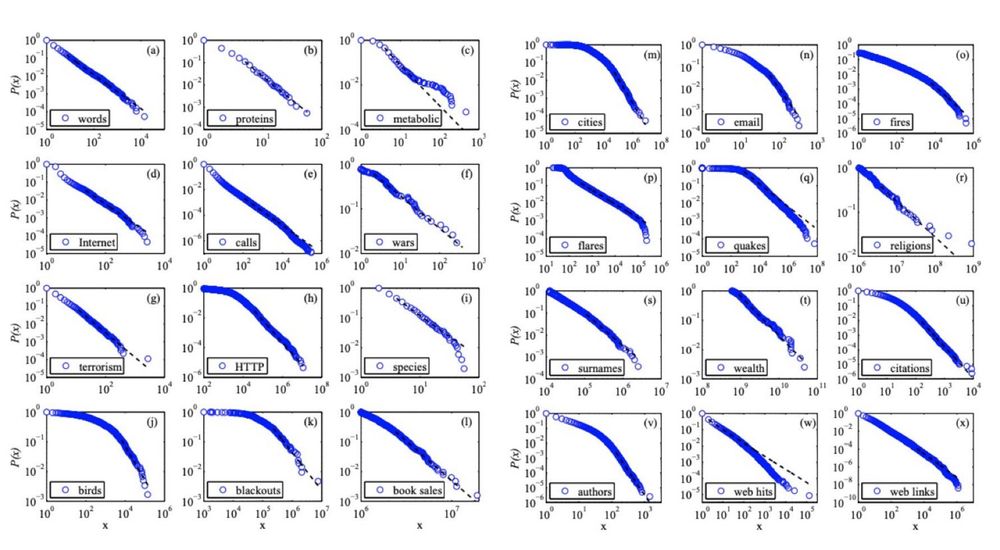
“On a log-log plot, my grandmother fits on a straight line.”
-Physicist Fritz Houtermans
There's a lot of truth to this. log-log plots are often abused and can be very misleading
1/5
-Physicist Fritz Houtermans
There's a lot of truth to this. log-log plots are often abused and can be very misleading
1/5
December 3, 2024 at 4:41 AM
“On a log-log plot, my grandmother fits on a straight line.”
-Physicist Fritz Houtermans
There's a lot of truth to this. log-log plots are often abused and can be very misleading
1/5
-Physicist Fritz Houtermans
There's a lot of truth to this. log-log plots are often abused and can be very misleading
1/5
Better VQ-VAEs with this one weird rotation trick!
I missed this when it came out, but I love papers like this: a simple change to an already powerful technique, that significantly improves results without introducing complexity or hyperparameters.
I missed this when it came out, but I love papers like this: a simple change to an already powerful technique, that significantly improves results without introducing complexity or hyperparameters.

December 2, 2024 at 7:52 PM
Better VQ-VAEs with this one weird rotation trick!
I missed this when it came out, but I love papers like this: a simple change to an already powerful technique, that significantly improves results without introducing complexity or hyperparameters.
I missed this when it came out, but I love papers like this: a simple change to an already powerful technique, that significantly improves results without introducing complexity or hyperparameters.
There is a lot of great writing on flow matching out there all of a sudden! This post clarifies the connection with diffusion models -- they are essentially two different ways to describe the same class of models.

A common question nowadays: Which is better, diffusion or flow matching? 🤔
Our answer: They’re two sides of the same coin. We wrote a blog post to show how diffusion models and Gaussian flow matching are equivalent. That’s great: It means you can use them interchangeably.
Our answer: They’re two sides of the same coin. We wrote a blog post to show how diffusion models and Gaussian flow matching are equivalent. That’s great: It means you can use them interchangeably.

December 2, 2024 at 7:11 PM
There is a lot of great writing on flow matching out there all of a sudden! This post clarifies the connection with diffusion models -- they are essentially two different ways to describe the same class of models.
In arxiv.org/abs/2303.00848, @dpkingma.bsky.social and @ruiqigao.bsky.social had suggested that noise augmentation could be used to make other likelihood-based models optimise perceptually weighted losses, like diffusion models do. So cool to see this working well in practice!
December 2, 2024 at 6:36 PM
In arxiv.org/abs/2303.00848, @dpkingma.bsky.social and @ruiqigao.bsky.social had suggested that noise augmentation could be used to make other likelihood-based models optimise perceptually weighted losses, like diffusion models do. So cool to see this working well in practice!