




Andrew Saxe
@saxelab.bsky.social
Professor at the Gatsby Unit and Sainsbury Wellcome Centre, UCL, trying to figure out how we learn
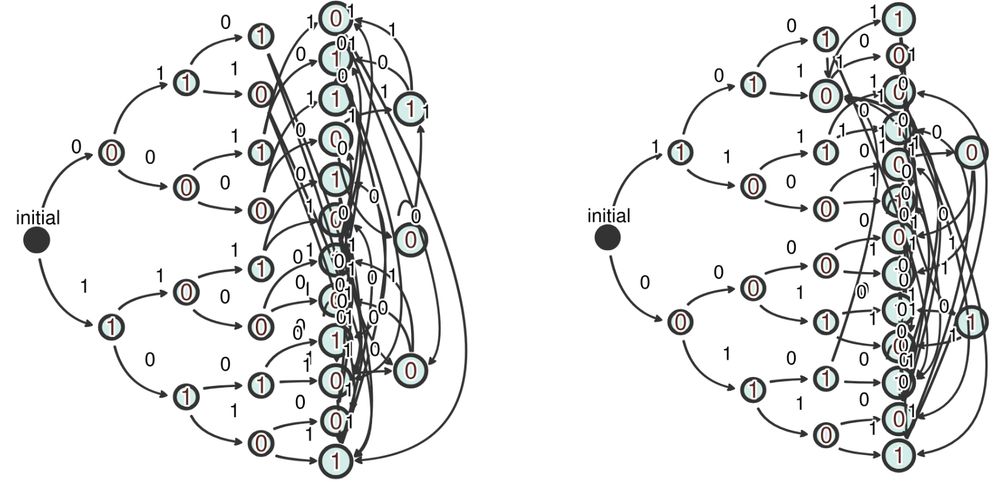
Not all pairs of representations which can merge are actually expected to merge. Thus, the final learned automaton may look different for different training runs, even when in practice they implement an identical algorithm.
(10/11)
(10/11)
July 14, 2025 at 9:25 PM
Not all pairs of representations which can merge are actually expected to merge. Thus, the final learned automaton may look different for different training runs, even when in practice they implement an identical algorithm.
(10/11)
(10/11)
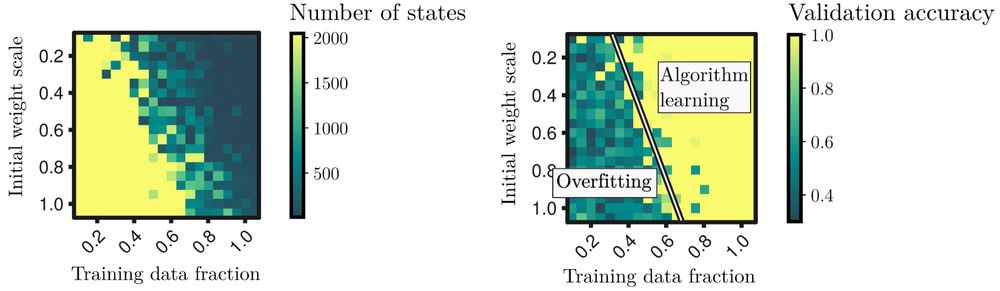
The theory predicts mergers can only occur given enough training data and small enough initial weights, resulting in a phase transition between an overfitting regime and an algorithm-learning regime.
(9/11)
(9/11)
July 14, 2025 at 9:25 PM
The theory predicts mergers can only occur given enough training data and small enough initial weights, resulting in a phase transition between an overfitting regime and an algorithm-learning regime.
(9/11)
(9/11)
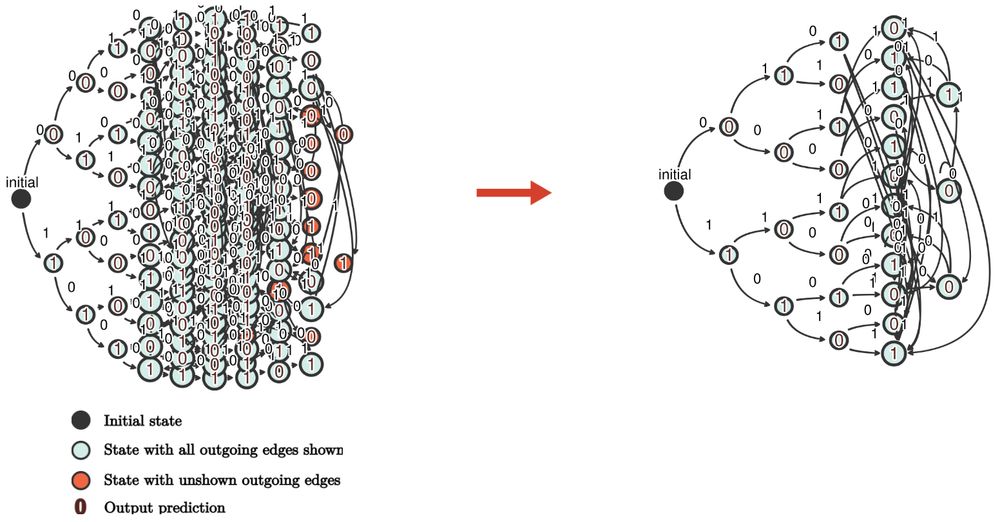
Since these pairs share outputs, mergers do not affect the automaton's computation.
With enough mergers, the automaton becomes finite, fixing its behavior for long sequences.
If the training data uniquely specifies the task, this results in full generalization.
(8/11)
With enough mergers, the automaton becomes finite, fixing its behavior for long sequences.
If the training data uniquely specifies the task, this results in full generalization.
(8/11)
July 14, 2025 at 9:25 PM
Since these pairs share outputs, mergers do not affect the automaton's computation.
With enough mergers, the automaton becomes finite, fixing its behavior for long sequences.
If the training data uniquely specifies the task, this results in full generalization.
(8/11)
With enough mergers, the automaton becomes finite, fixing its behavior for long sequences.
If the training data uniquely specifies the task, this results in full generalization.
(8/11)
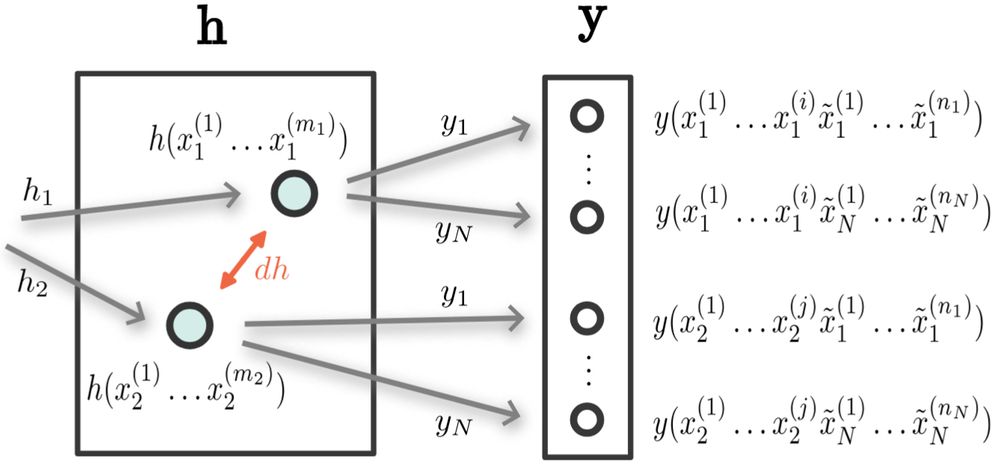
Using intuitions based on continuity, we derive local interactions between pairs of representations.
We find that pairs of sequences which always agree on target outputs after receiving any possible additional symbols will merge representations under certain conditions.
(7/11)
We find that pairs of sequences which always agree on target outputs after receiving any possible additional symbols will merge representations under certain conditions.
(7/11)
July 14, 2025 at 9:25 PM
Using intuitions based on continuity, we derive local interactions between pairs of representations.
We find that pairs of sequences which always agree on target outputs after receiving any possible additional symbols will merge representations under certain conditions.
(7/11)
We find that pairs of sequences which always agree on target outputs after receiving any possible additional symbols will merge representations under certain conditions.
(7/11)
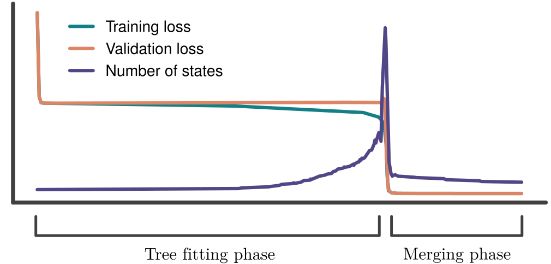
We find two phases:
-An initial phase where the RNN builds an infinite tree and fits it to the training data, reducing only the training loss.
-A second merging phase, where representations merge until the automaton becomes finite, with a sudden drop in validation loss.
(6/11)
-An initial phase where the RNN builds an infinite tree and fits it to the training data, reducing only the training loss.
-A second merging phase, where representations merge until the automaton becomes finite, with a sudden drop in validation loss.
(6/11)
July 14, 2025 at 9:25 PM
We find two phases:
-An initial phase where the RNN builds an infinite tree and fits it to the training data, reducing only the training loss.
-A second merging phase, where representations merge until the automaton becomes finite, with a sudden drop in validation loss.
(6/11)
-An initial phase where the RNN builds an infinite tree and fits it to the training data, reducing only the training loss.
-A second merging phase, where representations merge until the automaton becomes finite, with a sudden drop in validation loss.
(6/11)
To understand what is happening in the RNN, we extract automata from its hidden representations during training, which visualize the computational algorithm as it is being developed.
(5/11)
(5/11)
July 14, 2025 at 9:25 PM
To understand what is happening in the RNN, we extract automata from its hidden representations during training, which visualize the computational algorithm as it is being developed.
(5/11)
(5/11)
When training only on sequences up to length 10, we find complete generalization for any possible sequence length.
This cannot be explained by smooth interpolation of the training data, and suggests some kind of algorithm is being learned.
(4/11)
This cannot be explained by smooth interpolation of the training data, and suggests some kind of algorithm is being learned.
(4/11)
July 14, 2025 at 9:25 PM
When training only on sequences up to length 10, we find complete generalization for any possible sequence length.
This cannot be explained by smooth interpolation of the training data, and suggests some kind of algorithm is being learned.
(4/11)
This cannot be explained by smooth interpolation of the training data, and suggests some kind of algorithm is being learned.
(4/11)
Whoops, here's a working version of that starting video--dynamics visit a series of plateaus.
June 4, 2025 at 12:41 PM
Whoops, here's a working version of that starting video--dynamics visit a series of plateaus.
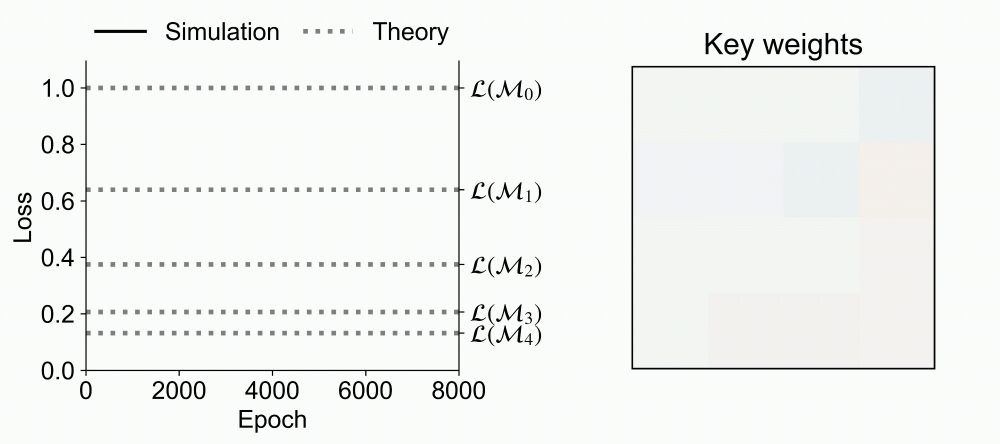
For linear attention with separate key and query, we show that the training dynamics has exponentially many fixed points and the loss exhibits saddle-to-saddle dynamics, which we reduce to scalar ordinary differential equations.
What in-context learning algorithm is implemented at each plateau?
What in-context learning algorithm is implemented at each plateau?

June 4, 2025 at 11:22 AM
For linear attention with separate key and query, we show that the training dynamics has exponentially many fixed points and the loss exhibits saddle-to-saddle dynamics, which we reduce to scalar ordinary differential equations.
What in-context learning algorithm is implemented at each plateau?
What in-context learning algorithm is implemented at each plateau?
For linear attention with merged key and query, we show that its training dynamics has two fixed points and the loss trajectory exhibits a single, abrupt drop.
We derive an exact analytical time-course solution for a class of datasets and initializations.
We derive an exact analytical time-course solution for a class of datasets and initializations.

June 4, 2025 at 11:22 AM
For linear attention with merged key and query, we show that its training dynamics has two fixed points and the loss trajectory exhibits a single, abrupt drop.
We derive an exact analytical time-course solution for a class of datasets and initializations.
We derive an exact analytical time-course solution for a class of datasets and initializations.
We study the gradient descent dynamics of multi-head linear self-attention trained for in-context linear regression.
We examine 2 common parametrizations of linear attention: one with the key and query weights merged as a single matrix, and one with separate key and query weights
We examine 2 common parametrizations of linear attention: one with the key and query weights merged as a single matrix, and one with separate key and query weights

June 4, 2025 at 11:22 AM
We study the gradient descent dynamics of multi-head linear self-attention trained for in-context linear regression.
We examine 2 common parametrizations of linear attention: one with the key and query weights merged as a single matrix, and one with separate key and query weights
We examine 2 common parametrizations of linear attention: one with the key and query weights merged as a single matrix, and one with separate key and query weights
How does in-context learning emerge in attention models during gradient descent training?
Sharing our new Spotlight paper @icmlconf.bsky.social: Training Dynamics of In-Context Learning in Linear Attention
arxiv.org/abs/2501.16265
Led by Yedi Zhang with @aaditya6284.bsky.social and Peter Latham
Sharing our new Spotlight paper @icmlconf.bsky.social: Training Dynamics of In-Context Learning in Linear Attention
arxiv.org/abs/2501.16265
Led by Yedi Zhang with @aaditya6284.bsky.social and Peter Latham
June 4, 2025 at 11:22 AM
How does in-context learning emerge in attention models during gradient descent training?
Sharing our new Spotlight paper @icmlconf.bsky.social: Training Dynamics of In-Context Learning in Linear Attention
arxiv.org/abs/2501.16265
Led by Yedi Zhang with @aaditya6284.bsky.social and Peter Latham
Sharing our new Spotlight paper @icmlconf.bsky.social: Training Dynamics of In-Context Learning in Linear Attention
arxiv.org/abs/2501.16265
Led by Yedi Zhang with @aaditya6284.bsky.social and Peter Latham