



Sara Hooker
@sarahooker.bsky.social
I lead Cohere For AI. Formerly Research
Google Brain. ML Efficiency, LLMs,
@trustworthy_ml.
Google Brain. ML Efficiency, LLMs,
@trustworthy_ml.
We tried very hard to get this right, and have spent the last 5 months working carefully to ensure rigor.
If you made it this far, take a look at the full 68 pages: arxiv.org/abs/2504.20879
Any feedback or corrections are of course very welcome.
If you made it this far, take a look at the full 68 pages: arxiv.org/abs/2504.20879
Any feedback or corrections are of course very welcome.

April 30, 2025 at 2:58 PM
We tried very hard to get this right, and have spent the last 5 months working carefully to ensure rigor.
If you made it this far, take a look at the full 68 pages: arxiv.org/abs/2504.20879
Any feedback or corrections are of course very welcome.
If you made it this far, take a look at the full 68 pages: arxiv.org/abs/2504.20879
Any feedback or corrections are of course very welcome.
This was an uncomfortable paper to work on because it asks us to look in the mirror as a community.
As scientists, we must do better.
As a community, I hope we can demand better. We make very clear the 5 changes needed.
As scientists, we must do better.
As a community, I hope we can demand better. We make very clear the 5 changes needed.

April 30, 2025 at 2:55 PM
This was an uncomfortable paper to work on because it asks us to look in the mirror as a community.
As scientists, we must do better.
As a community, I hope we can demand better. We make very clear the 5 changes needed.
As scientists, we must do better.
As a community, I hope we can demand better. We make very clear the 5 changes needed.
Overall, our work suggests that engagement from a handful of providers and preferential policies from
Arena towards the same small group have created conditions to overfit to Arena-specific dynamics rather than general model quality.
Arena towards the same small group have created conditions to overfit to Arena-specific dynamics rather than general model quality.

April 30, 2025 at 2:55 PM
Overall, our work suggests that engagement from a handful of providers and preferential policies from
Arena towards the same small group have created conditions to overfit to Arena-specific dynamics rather than general model quality.
Arena towards the same small group have created conditions to overfit to Arena-specific dynamics rather than general model quality.
We show that access to Chatbot Arena data yields substantial benefits.
While using Arena-style data in training boosts win rates by 112%, this improvement doesn't transfer to tasks like MMLU, indicating overfitting to Arena's quirks rather than general performance gains.
While using Arena-style data in training boosts win rates by 112%, this improvement doesn't transfer to tasks like MMLU, indicating overfitting to Arena's quirks rather than general performance gains.

April 30, 2025 at 2:55 PM
We show that access to Chatbot Arena data yields substantial benefits.
While using Arena-style data in training boosts win rates by 112%, this improvement doesn't transfer to tasks like MMLU, indicating overfitting to Arena's quirks rather than general performance gains.
While using Arena-style data in training boosts win rates by 112%, this improvement doesn't transfer to tasks like MMLU, indicating overfitting to Arena's quirks rather than general performance gains.
These data differences stem from some key policies that benefit a handful of providers:
1) proprietary models sampled at higher rates to appear in battles 📶
2) open-weights + open-source models removed from Arena more often 🚮
3) How many private variants 🔍
1) proprietary models sampled at higher rates to appear in battles 📶
2) open-weights + open-source models removed from Arena more often 🚮
3) How many private variants 🔍

April 30, 2025 at 2:55 PM
These data differences stem from some key policies that benefit a handful of providers:
1) proprietary models sampled at higher rates to appear in battles 📶
2) open-weights + open-source models removed from Arena more often 🚮
3) How many private variants 🔍
1) proprietary models sampled at higher rates to appear in battles 📶
2) open-weights + open-source models removed from Arena more often 🚮
3) How many private variants 🔍
We also observe large differences in Arena Data Access
Chatbot Arena is a open community resource that provides free feedback but 61.3% of all data goes to proprietary model providers.
Chatbot Arena is a open community resource that provides free feedback but 61.3% of all data goes to proprietary model providers.

April 30, 2025 at 2:55 PM
We also observe large differences in Arena Data Access
Chatbot Arena is a open community resource that provides free feedback but 61.3% of all data goes to proprietary model providers.
Chatbot Arena is a open community resource that provides free feedback but 61.3% of all data goes to proprietary model providers.
There is no reasonable scientific justification for this practice.
Being able to choose the best score to disclose enables systematic gaming of Arena score.
This advantage increases with number of variants and if all other providers don’t know they can also private test.
Being able to choose the best score to disclose enables systematic gaming of Arena score.
This advantage increases with number of variants and if all other providers don’t know they can also private test.

April 30, 2025 at 2:55 PM
There is no reasonable scientific justification for this practice.
Being able to choose the best score to disclose enables systematic gaming of Arena score.
This advantage increases with number of variants and if all other providers don’t know they can also private test.
Being able to choose the best score to disclose enables systematic gaming of Arena score.
This advantage increases with number of variants and if all other providers don’t know they can also private test.
There is an unspoken policy of hidden testing that benefits a small subset of providers.
Providers can choose what score to disclose and retract all others.
At an extreme, we see testing of up to 27 models in lead up to releases.
Providers can choose what score to disclose and retract all others.
At an extreme, we see testing of up to 27 models in lead up to releases.

April 30, 2025 at 2:55 PM
There is an unspoken policy of hidden testing that benefits a small subset of providers.
Providers can choose what score to disclose and retract all others.
At an extreme, we see testing of up to 27 models in lead up to releases.
Providers can choose what score to disclose and retract all others.
At an extreme, we see testing of up to 27 models in lead up to releases.
We spent 5 months analyzing 2.8M battles on the Arena, covering 238 models across 43 providers.
We show that preferential policies engaged in by a handful of providers lead to overfitting to Arena-specific metrics rather than genuine AI progress.
We show that preferential policies engaged in by a handful of providers lead to overfitting to Arena-specific metrics rather than genuine AI progress.

April 30, 2025 at 2:55 PM
We spent 5 months analyzing 2.8M battles on the Arena, covering 238 models across 43 providers.
We show that preferential policies engaged in by a handful of providers lead to overfitting to Arena-specific metrics rather than genuine AI progress.
We show that preferential policies engaged in by a handful of providers lead to overfitting to Arena-specific metrics rather than genuine AI progress.
It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.

April 30, 2025 at 2:55 PM
It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
It is rare I get to completely disconnect. Very grateful for this week in Patagonia.




March 19, 2025 at 9:48 PM
It is rare I get to completely disconnect. Very grateful for this week in Patagonia.
... but we should be careful that an emphasis on sovereign AI doesn't undermine our shared experience.
At the Elysee dinner, Macron put this tension well --saying it would be unfortunate if we end up with a Chinese, French, US model – biased towards our differences.
At the Elysee dinner, Macron put this tension well --saying it would be unfortunate if we end up with a Chinese, French, US model – biased towards our differences.

February 13, 2025 at 9:13 AM
... but we should be careful that an emphasis on sovereign AI doesn't undermine our shared experience.
At the Elysee dinner, Macron put this tension well --saying it would be unfortunate if we end up with a Chinese, French, US model – biased towards our differences.
At the Elysee dinner, Macron put this tension well --saying it would be unfortunate if we end up with a Chinese, French, US model – biased towards our differences.
Many people have asked me about the France Action Summit.
I think a summit is typically most valuable as a catalyst, not as a solution in itself.
But, will share some observations.
I think a summit is typically most valuable as a catalyst, not as a solution in itself.
But, will share some observations.

February 13, 2025 at 9:08 AM
Many people have asked me about the France Action Summit.
I think a summit is typically most valuable as a catalyst, not as a solution in itself.
But, will share some observations.
I think a summit is typically most valuable as a catalyst, not as a solution in itself.
But, will share some observations.
British gardens are beautiful even in the gloom

December 26, 2024 at 7:00 AM
British gardens are beautiful even in the gloom
Culturally Sensitive 🗽 tasks also increase variability in model rankings, for all languages across all resource levels ↕️.
This shows how performance on western concepts impacts model rankings.
This shows how performance on western concepts impacts model rankings.

December 5, 2024 at 4:31 PM
Culturally Sensitive 🗽 tasks also increase variability in model rankings, for all languages across all resource levels ↕️.
This shows how performance on western concepts impacts model rankings.
This shows how performance on western concepts impacts model rankings.
To build Global-MMLU, we:
✍️ greatly improve translation quality with human translations and post-edits
🗂️ Use professional annotators to trace what questions into Culturally Sensitive (CS 🗽) and Culturally Agnostic (CA ⚖️) subsets.
We release on HuggingFace: huggingface.co/datasets/Coh...
✍️ greatly improve translation quality with human translations and post-edits
🗂️ Use professional annotators to trace what questions into Culturally Sensitive (CS 🗽) and Culturally Agnostic (CA ⚖️) subsets.
We release on HuggingFace: huggingface.co/datasets/Coh...
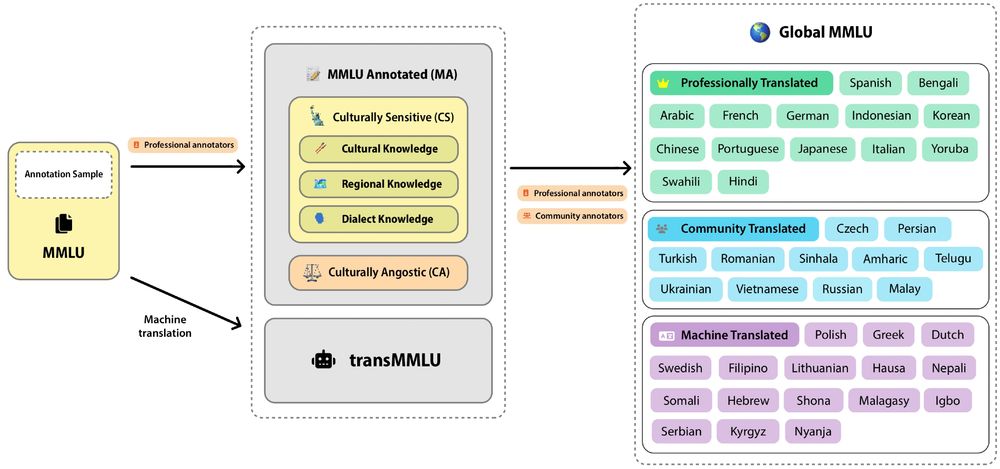
December 5, 2024 at 4:31 PM
To build Global-MMLU, we:
✍️ greatly improve translation quality with human translations and post-edits
🗂️ Use professional annotators to trace what questions into Culturally Sensitive (CS 🗽) and Culturally Agnostic (CA ⚖️) subsets.
We release on HuggingFace: huggingface.co/datasets/Coh...
✍️ greatly improve translation quality with human translations and post-edits
🗂️ Use professional annotators to trace what questions into Culturally Sensitive (CS 🗽) and Culturally Agnostic (CA ⚖️) subsets.
We release on HuggingFace: huggingface.co/datasets/Coh...
We found out that 28% of MMLU requires cultural context to be answered correctly.
An outsanding 85% are tagged as specific to Western culture 🗽 or western regions 🗺️
Progress on MMLU requires excelling at western culture.
An outsanding 85% are tagged as specific to Western culture 🗽 or western regions 🗺️
Progress on MMLU requires excelling at western culture.

December 5, 2024 at 4:31 PM
We found out that 28% of MMLU requires cultural context to be answered correctly.
An outsanding 85% are tagged as specific to Western culture 🗽 or western regions 🗺️
Progress on MMLU requires excelling at western culture.
An outsanding 85% are tagged as specific to Western culture 🗽 or western regions 🗺️
Progress on MMLU requires excelling at western culture.
Is MMLU Western-centric? 🤔
As part of a massive cross-institutional collaboration:
🗽Find MMLU is heavily overfit to western culture
🔍 Professional annotation of cultural sensitivity data
🌍 Release improved Global-MMLU 42 languages
📜 Paper: arxiv.org/pdf/2412.03304
📂 Data: hf.co/datasets/Coh...
As part of a massive cross-institutional collaboration:
🗽Find MMLU is heavily overfit to western culture
🔍 Professional annotation of cultural sensitivity data
🌍 Release improved Global-MMLU 42 languages
📜 Paper: arxiv.org/pdf/2412.03304
📂 Data: hf.co/datasets/Coh...

December 5, 2024 at 4:31 PM
Is MMLU Western-centric? 🤔
As part of a massive cross-institutional collaboration:
🗽Find MMLU is heavily overfit to western culture
🔍 Professional annotation of cultural sensitivity data
🌍 Release improved Global-MMLU 42 languages
📜 Paper: arxiv.org/pdf/2412.03304
📂 Data: hf.co/datasets/Coh...
As part of a massive cross-institutional collaboration:
🗽Find MMLU is heavily overfit to western culture
🔍 Professional annotation of cultural sensitivity data
🌍 Release improved Global-MMLU 42 languages
📜 Paper: arxiv.org/pdf/2412.03304
📂 Data: hf.co/datasets/Coh...
A collaboration led by Aidan Peppin with Anka Reuel, Stephen Casper, Elliot Jones, Andrew Strait, Usman Anwar,
Anurag Agrawal, Sayash Kapoor, Sanmi Koyejo, Marie Pellat, Rishi Bommasani and Nick Frosst. 🔥
Learn more about the work here: arxiv.org/abs/2412.01946
Anurag Agrawal, Sayash Kapoor, Sanmi Koyejo, Marie Pellat, Rishi Bommasani and Nick Frosst. 🔥
Learn more about the work here: arxiv.org/abs/2412.01946

December 4, 2024 at 5:15 AM
A collaboration led by Aidan Peppin with Anka Reuel, Stephen Casper, Elliot Jones, Andrew Strait, Usman Anwar,
Anurag Agrawal, Sayash Kapoor, Sanmi Koyejo, Marie Pellat, Rishi Bommasani and Nick Frosst. 🔥
Learn more about the work here: arxiv.org/abs/2412.01946
Anurag Agrawal, Sayash Kapoor, Sanmi Koyejo, Marie Pellat, Rishi Bommasani and Nick Frosst. 🔥
Learn more about the work here: arxiv.org/abs/2412.01946
AI amplifying biorisk has been a major focus in AI policy & governance work. Is the spotlight merited?
Our recent cross-institutional work asks: Does the available evidence match the current level of attention?
📜 arxiv.org/abs/2412.01946
Our recent cross-institutional work asks: Does the available evidence match the current level of attention?
📜 arxiv.org/abs/2412.01946

December 4, 2024 at 5:05 AM
AI amplifying biorisk has been a major focus in AI policy & governance work. Is the spotlight merited?
Our recent cross-institutional work asks: Does the available evidence match the current level of attention?
📜 arxiv.org/abs/2412.01946
Our recent cross-institutional work asks: Does the available evidence match the current level of attention?
📜 arxiv.org/abs/2412.01946
I just found this photo on my drive and can't remember where it I took it.
Does anyone know what airport this is?
Does anyone know what airport this is?

April 27, 2023 at 4:33 AM
I just found this photo on my drive and can't remember where it I took it.
Does anyone know what airport this is?
Does anyone know what airport this is?