



Riccardo Cappuzzo
@riccardocappuzzo.com
Research engineer at Inria Saclay, working on the Skrub library.
Python, data preparation, ML, tabular learning.
ORCID: 0000-0002-4448-2959
Hoshiyomi ☄️
https://www.riccardocappuzzo.com
https://github.com/rcap107
Python, data preparation, ML, tabular learning.
ORCID: 0000-0002-4448-2959
Hoshiyomi ☄️
https://www.riccardocappuzzo.com
https://github.com/rcap107
"ok the test run is done, let's see"
...
"this will be hard to debug"
...
"this will be hard to debug"

October 9, 2025 at 1:29 PM
"ok the test run is done, let's see"
...
"this will be hard to debug"
...
"this will be hard to debug"
Working hard on the next @skrub-data.bsky.social slide deck...


September 4, 2025 at 10:19 PM
Working hard on the next @skrub-data.bsky.social slide deck...
Really cool graffiti I spotted while walking around in the town where I live




June 13, 2025 at 9:10 PM
Really cool graffiti I spotted while walking around in the town where I live
Now that the paper is out, I can finally share the totally-not-confusing script/plot/table map I made to track which scripts prepare which figures and tables and from what data.
If it wasn't clear, don't do this. If you *really* have to, I used the @obsidian.md canvas for this.
If it wasn't clear, don't do this. If you *really* have to, I used the @obsidian.md canvas for this.

May 20, 2025 at 8:26 AM
Now that the paper is out, I can finally share the totally-not-confusing script/plot/table map I made to track which scripts prepare which figures and tables and from what data.
If it wasn't clear, don't do this. If you *really* have to, I used the @obsidian.md canvas for this.
If it wasn't clear, don't do this. If you *really* have to, I used the @obsidian.md canvas for this.
A bit of a mess up with this figure! This is what it's supposed to look like 🙈

May 19, 2025 at 4:01 PM
A bit of a mess up with this figure! This is what it's supposed to look like 🙈
⏱️ Complex aggregation methods are slower and don't significantly boost prediction performance.
6/
6/

May 19, 2025 at 3:43 PM
⏱️ Complex aggregation methods are slower and don't significantly boost prediction performance.
6/
6/
⚖️ Beware of diminishing returns! Performance plateaus as more candidates are retrieved, while resource costs (time and RAM) keep rising.
5/
5/

May 19, 2025 at 3:43 PM
⚖️ Beware of diminishing returns! Performance plateaus as more candidates are retrieved, while resource costs (time and RAM) keep rising.
5/
5/
🎯 Simple metric-based retrieval and candidate selection methods often outperform complex methods and are more efficient.
4/
4/

May 19, 2025 at 3:43 PM
🎯 Simple metric-based retrieval and candidate selection methods often outperform complex methods and are more efficient.
4/
4/
🔍 Good table retrieval is crucial helps finding candidates with useful features and fewer missing values. Jaccard containment is helpful but has its limits.
3/
3/

May 19, 2025 at 3:43 PM
🔍 Good table retrieval is crucial helps finding candidates with useful features and fewer missing values. Jaccard containment is helpful but has its limits.
3/
3/
🌳 Tree-based models offer better prediction and computational performance than deep learning-based methods in our setting, which involves training models over features that contain a large fraction of missing values.
2/
2/

May 19, 2025 at 3:43 PM
🌳 Tree-based models offer better prediction and computational performance than deep learning-based methods in our setting, which involves training models over features that contain a large fraction of missing values.
2/
2/
🌟 New paper alert! 🌟
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/

May 19, 2025 at 3:43 PM
🌟 New paper alert! 🌟
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
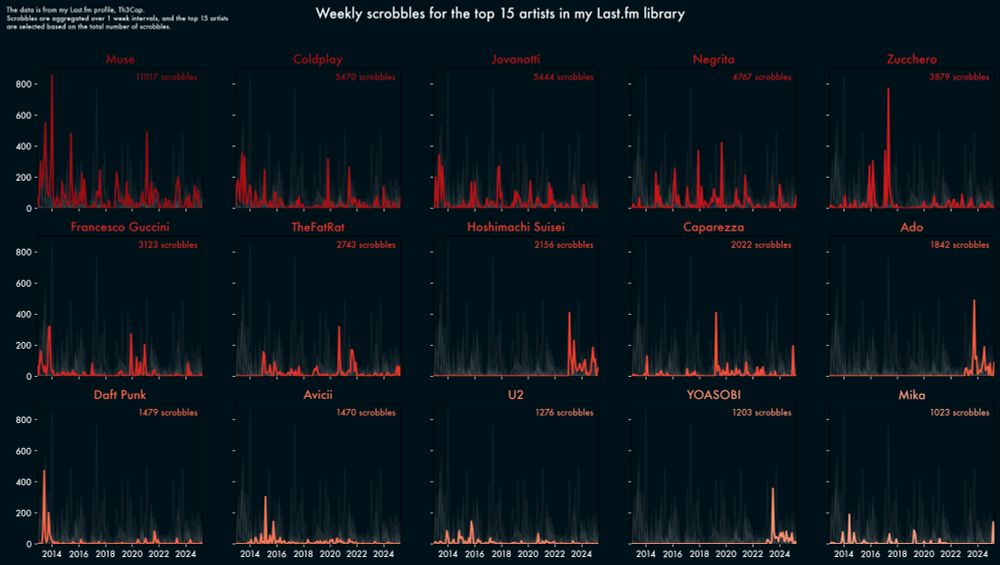
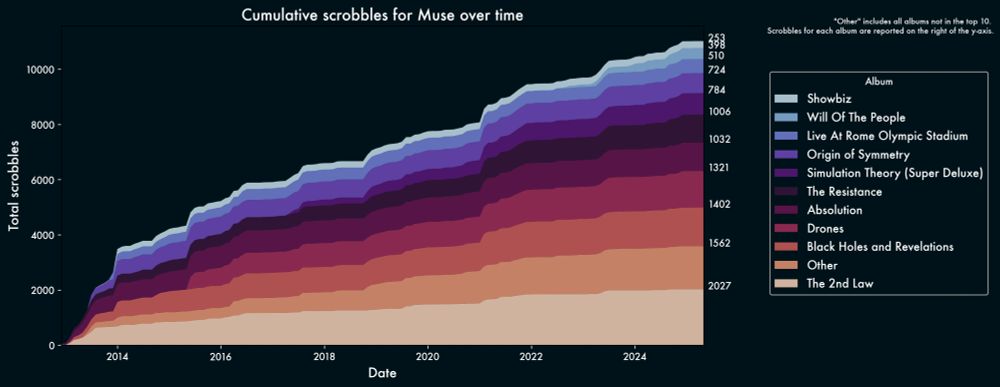
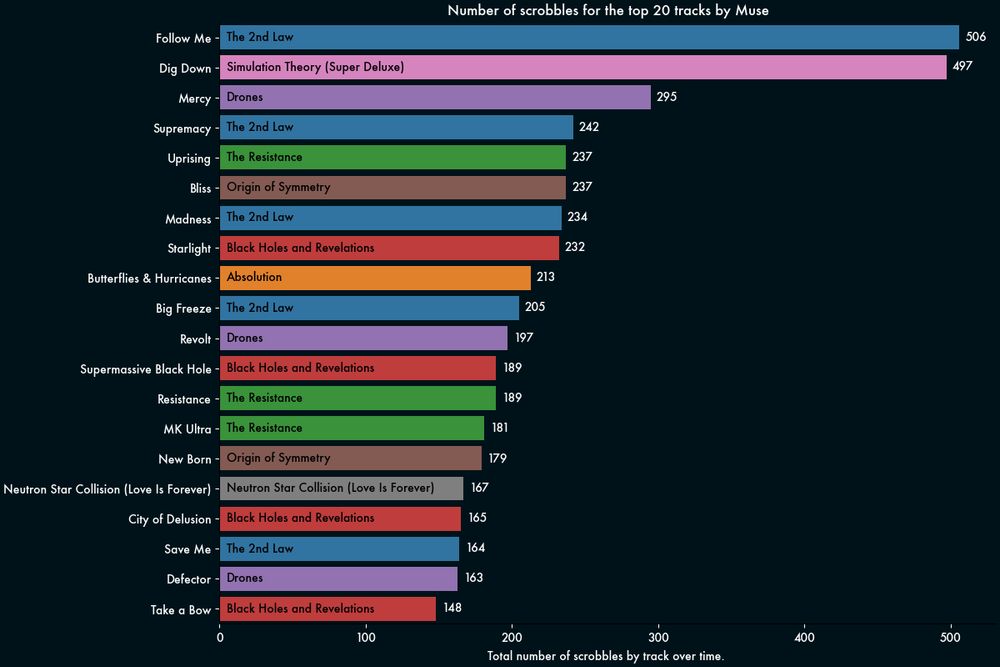
More fun digging around my @last.fm scrobbles using with @matplotlib.org
I had no idea how much of a difference changing fonts and background color could make
I had no idea how much of a difference changing fonts and background color could make
May 1, 2025 at 11:00 PM
More fun digging around my @last.fm scrobbles using with @matplotlib.org
I had no idea how much of a difference changing fonts and background color could make
I had no idea how much of a difference changing fonts and background color could make
I haven't been using a lot of Copilot until very recently, so I'm still learning what it can do.
It just blew my mind by autocompleting the dictionary "release_dates" with the correct dates for Muse albums based on the fact I am looking at data about Muse in the script.
wow
It just blew my mind by autocompleting the dictionary "release_dates" with the correct dates for Muse albums based on the fact I am looking at data about Muse in the script.
wow

May 1, 2025 at 6:51 PM
I haven't been using a lot of Copilot until very recently, so I'm still learning what it can do.
It just blew my mind by autocompleting the dictionary "release_dates" with the correct dates for Muse albums based on the fact I am looking at data about Muse in the script.
wow
It just blew my mind by autocompleting the dictionary "release_dates" with the correct dates for Muse albums based on the fact I am looking at data about Muse in the script.
wow
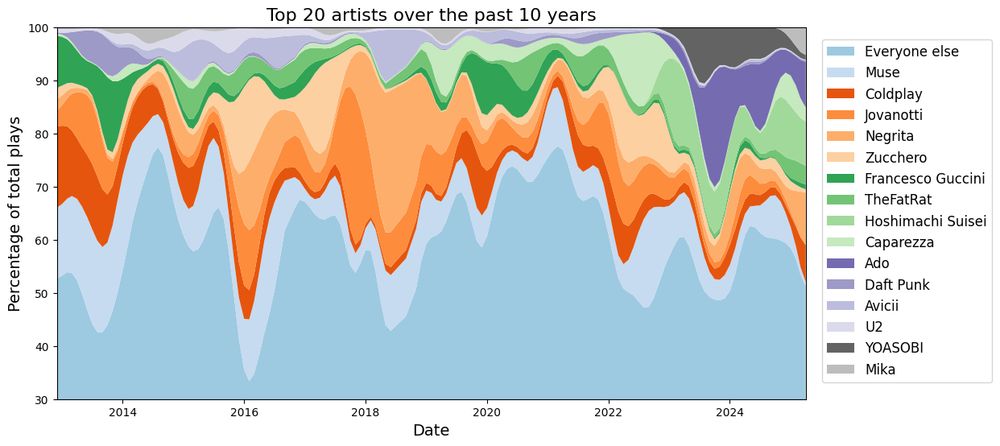
First experiment plotting my Last.fm scrobbles
With 10 years worth of data, I'll be working on this for a while.
Also first time working with @matplotlib.org stackplots, much finagling was involved
With 10 years worth of data, I'll be working on this for a while.
Also first time working with @matplotlib.org stackplots, much finagling was involved
April 30, 2025 at 10:33 PM
First experiment plotting my Last.fm scrobbles
With 10 years worth of data, I'll be working on this for a while.
Also first time working with @matplotlib.org stackplots, much finagling was involved
With 10 years worth of data, I'll be working on this for a while.
Also first time working with @matplotlib.org stackplots, much finagling was involved
The similarity is uncanny

April 10, 2025 at 2:07 PM
The similarity is uncanny

One good thing about living in Paris is that, well, you're living in Paris.




December 14, 2024 at 11:51 PM
One good thing about living in Paris is that, well, you're living in Paris.
The good thing about running experiments in France is that I can feel slightly less guilty about my emissions, but still
yikes
yikes

December 12, 2024 at 10:45 AM
The good thing about running experiments in France is that I can feel slightly less guilty about my emissions, but still
yikes
yikes
Sister's Christmas cat

November 28, 2024 at 8:01 PM
Sister's Christmas cat

November 27, 2024 at 11:25 AM
This is a very simple example of what I am working with, only I have potentially thousands of lines like this.
Looking at the documentation, it does look like I wouldn't need a lot of the features of SSSOM (and it might just add overhead in my scenario).
Still, thanks for the clarification 👍
Looking at the documentation, it does look like I wouldn't need a lot of the features of SSSOM (and it might just add overhead in my scenario).
Still, thanks for the clarification 👍

November 19, 2024 at 9:38 AM
This is a very simple example of what I am working with, only I have potentially thousands of lines like this.
Looking at the documentation, it does look like I wouldn't need a lot of the features of SSSOM (and it might just add overhead in my scenario).
Still, thanks for the clarification 👍
Looking at the documentation, it does look like I wouldn't need a lot of the features of SSSOM (and it might just add overhead in my scenario).
Still, thanks for the clarification 👍