



Raphaël Merx
@rapha.dev
PhD @ UniMelb
NLP, with a healthy dose of MT
Based in 🇮🇩, worked in 🇹🇱 🇵🇬 , from 🇫🇷
NLP, with a healthy dose of MT
Based in 🇮🇩, worked in 🇹🇱 🇵🇬 , from 🇫🇷
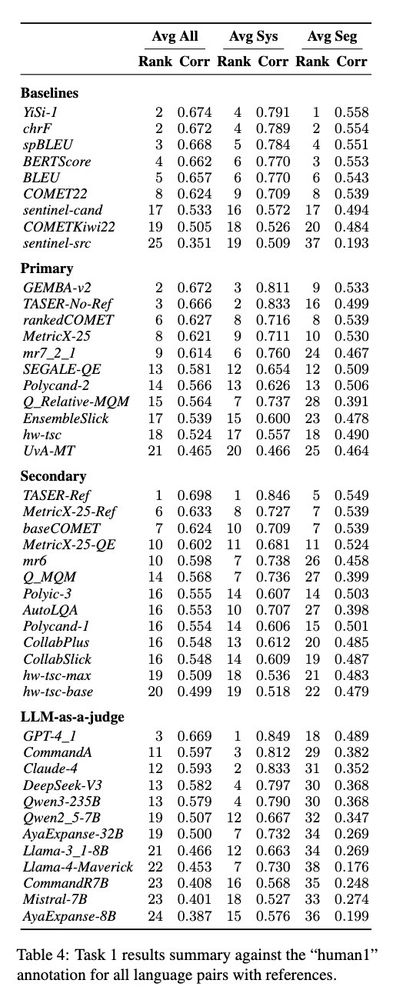
in Vienna for ACL, presenting Tulun, a system for low-resource in-domain translation, using LLMs
Tuesday @ 4pm
Working w 2 real use cases: medical translation into Tetun 🇹🇱 & disaster relief speech translation in Bislama 🇻🇺
Tuesday @ 4pm
Working w 2 real use cases: medical translation into Tetun 🇹🇱 & disaster relief speech translation in Bislama 🇻🇺

July 27, 2025 at 4:00 PM
in Vienna for ACL, presenting Tulun, a system for low-resource in-domain translation, using LLMs
Tuesday @ 4pm
Working w 2 real use cases: medical translation into Tetun 🇹🇱 & disaster relief speech translation in Bislama 🇻🇺
Tuesday @ 4pm
Working w 2 real use cases: medical translation into Tetun 🇹🇱 & disaster relief speech translation in Bislama 🇻🇺
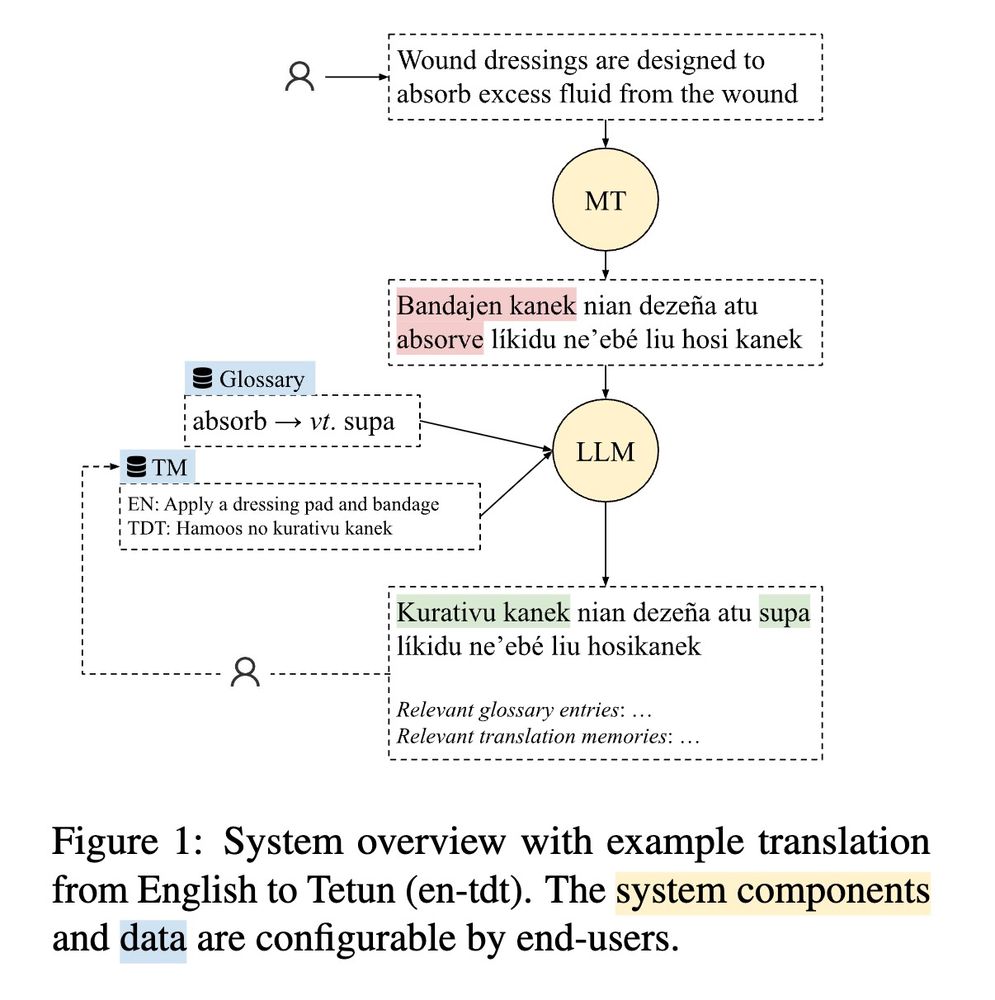
(3) The vast majority of usage is on mobile (over 90% of users / over 80k devices)
Takeaway: publishing MT model in mobile apps is probably more impactful than setting up a website / HuggingFace space.
Takeaway: publishing MT model in mobile apps is probably more impactful than setting up a website / HuggingFace space.
May 25, 2025 at 1:11 AM
(3) The vast majority of usage is on mobile (over 90% of users / over 80k devices)
Takeaway: publishing MT model in mobile apps is probably more impactful than setting up a website / HuggingFace space.
Takeaway: publishing MT model in mobile apps is probably more impactful than setting up a website / HuggingFace space.
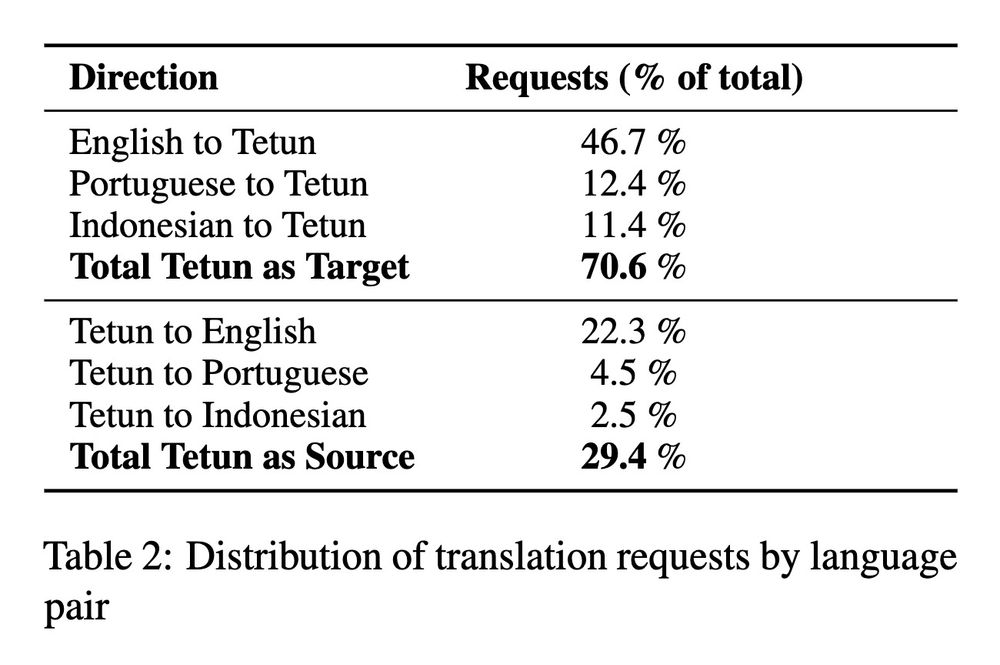
(2) Translation into Tetun is in higher demand (by >2x) than translation from Tetun
Takeaway for us MT folks: focus on translation into low-res langs, harder but more impactful
Takeaway for us MT folks: focus on translation into low-res langs, harder but more impactful
May 25, 2025 at 1:11 AM
(2) Translation into Tetun is in higher demand (by >2x) than translation from Tetun
Takeaway for us MT folks: focus on translation into low-res langs, harder but more impactful
Takeaway for us MT folks: focus on translation into low-res langs, harder but more impactful
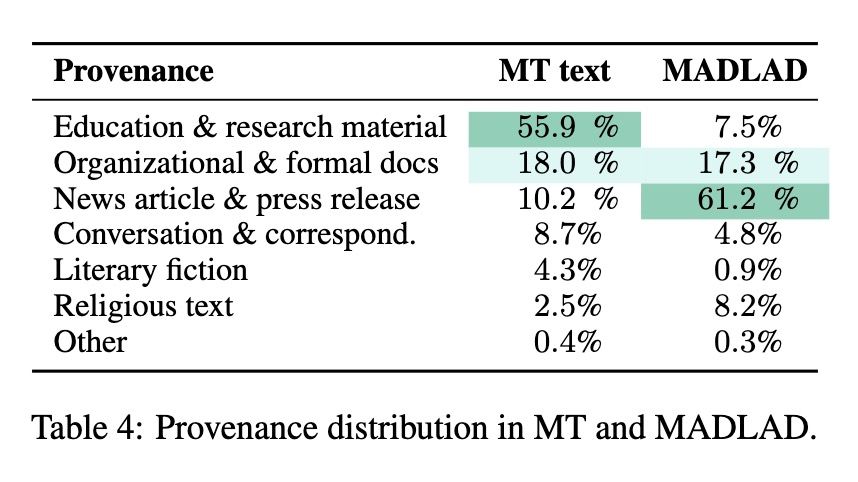
We find that
(1) a LOT of usage is for educational purposes (>50% of translated text)
--> contrasts sharply with Tetun corpora (e.g. MADLAD), dominated by news & religion.
Takeaway: don't evaluate MT on overrepresented domains (e.g. religion)! You risk misrepresenting end-user exp.
(1) a LOT of usage is for educational purposes (>50% of translated text)
--> contrasts sharply with Tetun corpora (e.g. MADLAD), dominated by news & religion.
Takeaway: don't evaluate MT on overrepresented domains (e.g. religion)! You risk misrepresenting end-user exp.
May 25, 2025 at 1:11 AM
We find that
(1) a LOT of usage is for educational purposes (>50% of translated text)
--> contrasts sharply with Tetun corpora (e.g. MADLAD), dominated by news & religion.
Takeaway: don't evaluate MT on overrepresented domains (e.g. religion)! You risk misrepresenting end-user exp.
(1) a LOT of usage is for educational purposes (>50% of translated text)
--> contrasts sharply with Tetun corpora (e.g. MADLAD), dominated by news & religion.
Takeaway: don't evaluate MT on overrepresented domains (e.g. religion)! You risk misrepresenting end-user exp.
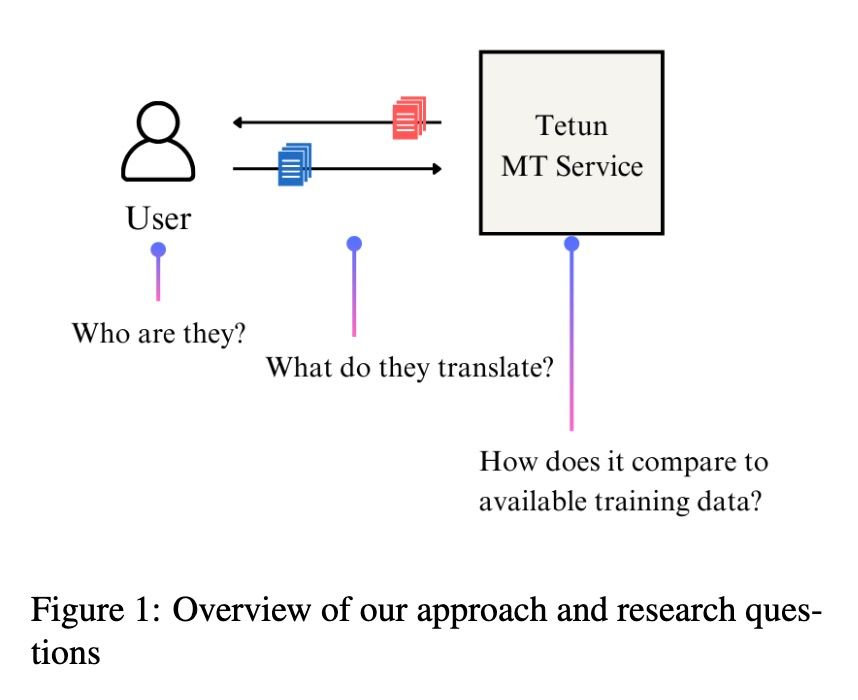
Our paper on who uses tetun.org, and what for, got published at the LoResMT 2025 workshop! An emotional paper for me, going back to the project that got me into a machine learning PhD in the first place.
May 25, 2025 at 1:11 AM
Our paper on who uses tetun.org, and what for, got published at the LoResMT 2025 workshop! An emotional paper for me, going back to the project that got me into a machine learning PhD in the first place.
My favourite ICLR paper so far. Methodology, findings and their implications are all very cool.
In particular Fig. 2 + this discussion point:
In particular Fig. 2 + this discussion point:

May 8, 2025 at 10:20 AM
My favourite ICLR paper so far. Methodology, findings and their implications are all very cool.
In particular Fig. 2 + this discussion point:
In particular Fig. 2 + this discussion point:
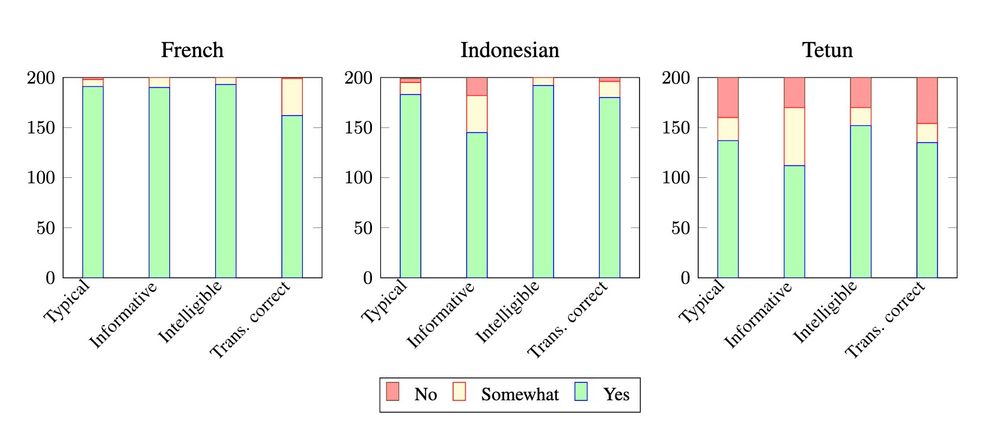
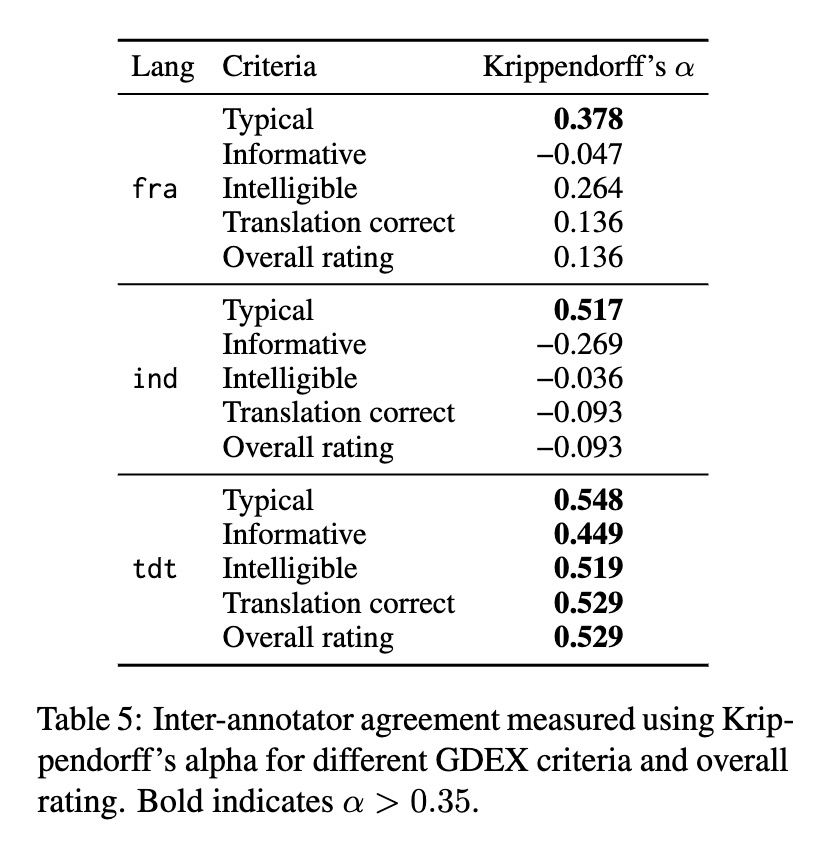
Our paper on generating bilingual example sentences with LLMs got best paper award @ ALTA in Canberra!
arxiv.org/abs/2410.03182
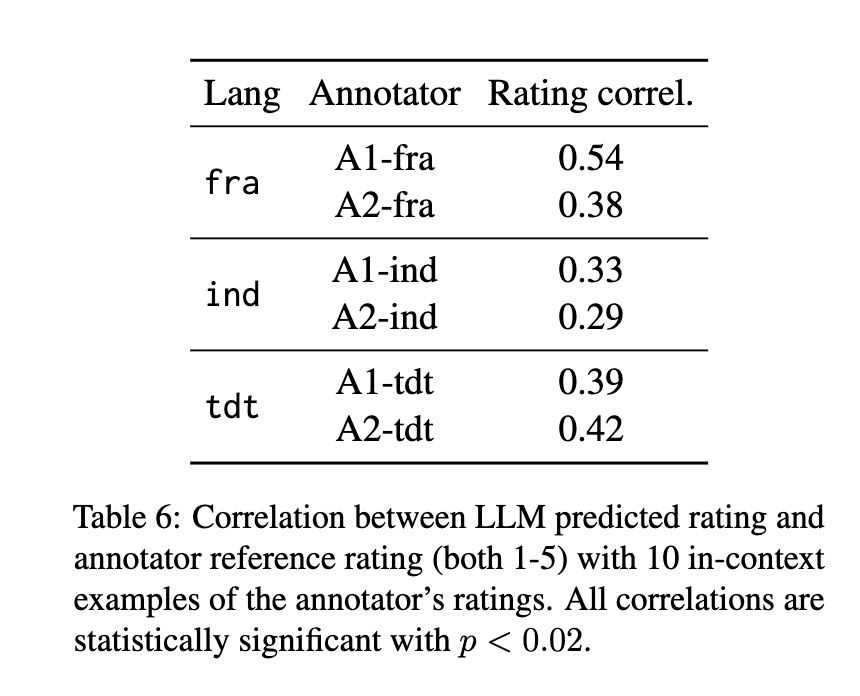
We work with French / Indonesian / Tetun, find that annotators don't agree about what's a "good example", but that LLMs can align with a specific annotator.
arxiv.org/abs/2410.03182
We work with French / Indonesian / Tetun, find that annotators don't agree about what's a "good example", but that LLMs can align with a specific annotator.

December 5, 2024 at 3:12 AM
Our paper on generating bilingual example sentences with LLMs got best paper award @ ALTA in Canberra!
arxiv.org/abs/2410.03182
We work with French / Indonesian / Tetun, find that annotators don't agree about what's a "good example", but that LLMs can align with a specific annotator.
arxiv.org/abs/2410.03182
We work with French / Indonesian / Tetun, find that annotators don't agree about what's a "good example", but that LLMs can align with a specific annotator.
this guy lives rent free in my hippocampus
November 20, 2024 at 7:01 AM
this guy lives rent free in my hippocampus