




Levi Lelis
@programsynthesis.bsky.social
Associate Professor - University of Alberta
Canada CIFAR AI Chair with Amii
Machine Learning and Program Synthesis
he/him; ele/dele 🇨🇦 🇧🇷
https://www.cs.ualberta.ca/~santanad
Canada CIFAR AI Chair with Amii
Machine Learning and Program Synthesis
he/him; ele/dele 🇨🇦 🇧🇷
https://www.cs.ualberta.ca/~santanad
Sometimes, neural networks (with little tweaks) are enough. Other times, solving the task requires a programmatic representation to capture algorithmic structure.
Preprint: arxiv.org/abs/2506.14162
Preprint: arxiv.org/abs/2506.14162

Common Benchmarks Undervalue the Generalization Power of Programmatic Policies
Algorithms for learning programmatic representations for sequential decision-making problems are often evaluated on out-of-distribution (OOD) problems, with the common conclusion that programmatic pol...
arxiv.org
July 2, 2025 at 10:12 PM
Sometimes, neural networks (with little tweaks) are enough. Other times, solving the task requires a programmatic representation to capture algorithmic structure.
Preprint: arxiv.org/abs/2506.14162
Preprint: arxiv.org/abs/2506.14162
1. Is the representation expressive enough to find solutions that generalize?
2. Can our search procedure find a policy that generalizes?
2. Can our search procedure find a policy that generalizes?
July 2, 2025 at 10:12 PM
1. Is the representation expressive enough to find solutions that generalize?
2. Can our search procedure find a policy that generalizes?
2. Can our search procedure find a policy that generalizes?
So, when should we use neural vs. programmatic policies for OOD generalization?
Rather than treating programmatic policies as the default, we should ask:
Rather than treating programmatic policies as the default, we should ask:
July 2, 2025 at 10:12 PM
So, when should we use neural vs. programmatic policies for OOD generalization?
Rather than treating programmatic policies as the default, we should ask:
Rather than treating programmatic policies as the default, we should ask:
As an illustrative example, we changed the grid-world task so that a solution policy must use a queue or stack to solve a navigation task. FunSearch found a Python program that provably generalizes. As one would expect, neural nets couldn’t solve the problem.
July 2, 2025 at 10:12 PM
As an illustrative example, we changed the grid-world task so that a solution policy must use a queue or stack to solve a navigation task. FunSearch found a Python program that provably generalizes. As one would expect, neural nets couldn’t solve the problem.
Are neural and programmatic policies similar in terms OOD generalization? We don't think so. We think that benchmark problems used in previous work actually undervalue what programmatic representations can do.
July 2, 2025 at 10:12 PM
Are neural and programmatic policies similar in terms OOD generalization? We don't think so. We think that benchmark problems used in previous work actually undervalue what programmatic representations can do.
Programmatic policies appeared to generalize better in previous work because they never learned to go fast in the easy training tracks. Neural nets optimized speed well, which made it difficult to generalize to tracks with sharp curves.
July 2, 2025 at 10:12 PM
Programmatic policies appeared to generalize better in previous work because they never learned to go fast in the easy training tracks. Neural nets optimized speed well, which made it difficult to generalize to tracks with sharp curves.
In a car-racing task, we adjusted the reward to encourage cautious driving. Neural nets generalized just as well as programmatic policies.
July 2, 2025 at 10:12 PM
In a car-racing task, we adjusted the reward to encourage cautious driving. Neural nets generalized just as well as programmatic policies.
We had to perform simple changes to the neural policies' training pipeline to attain similar OOD generalization to that exhibited by programmatic ones.
In a grid-world problem, we used the same sparse observation space as used with the programmatic policies augmented with the agent's last action.
In a grid-world problem, we used the same sparse observation space as used with the programmatic policies augmented with the agent's last action.
July 2, 2025 at 10:12 PM
We had to perform simple changes to the neural policies' training pipeline to attain similar OOD generalization to that exhibited by programmatic ones.
In a grid-world problem, we used the same sparse observation space as used with the programmatic policies augmented with the agent's last action.
In a grid-world problem, we used the same sparse observation space as used with the programmatic policies augmented with the agent's last action.
In a preprint, led by my Master's student Amirhossein Rajabpour, we revisit some of these OOD generalization claims and show that neural policies generalize just as well as programmatic ones on benchmark problems used in previous work.
Preprint: arxiv.org/abs/2506.14162
Preprint: arxiv.org/abs/2506.14162
arXiv.org e-Print archive
arxiv.org
July 2, 2025 at 10:12 PM
In a preprint, led by my Master's student Amirhossein Rajabpour, we revisit some of these OOD generalization claims and show that neural policies generalize just as well as programmatic ones on benchmark problems used in previous work.
Preprint: arxiv.org/abs/2506.14162
Preprint: arxiv.org/abs/2506.14162
In addition to Sat's pointers, I would also take a look at the following recent paper by @swarat.bsky.social:
www.cs.utexas.edu/~swarat/pubs...
Also, the following paper covers most of the recent works on neuro-guided bottom-up synthesis algorithms:
webdocs.cs.ualberta.ca/~santanad/pa...
www.cs.utexas.edu/~swarat/pubs...
Also, the following paper covers most of the recent works on neuro-guided bottom-up synthesis algorithms:
webdocs.cs.ualberta.ca/~santanad/pa...
www.cs.utexas.edu
June 17, 2025 at 3:19 AM
In addition to Sat's pointers, I would also take a look at the following recent paper by @swarat.bsky.social:
www.cs.utexas.edu/~swarat/pubs...
Also, the following paper covers most of the recent works on neuro-guided bottom-up synthesis algorithms:
webdocs.cs.ualberta.ca/~santanad/pa...
www.cs.utexas.edu/~swarat/pubs...
Also, the following paper covers most of the recent works on neuro-guided bottom-up synthesis algorithms:
webdocs.cs.ualberta.ca/~santanad/pa...
I wanted to thank the folks who reviewed our paper. Your feedback helped us improve our work, especially by asking us to include experiments on more difficult instances and the TSP. Thank you!
June 13, 2025 at 3:29 AM
I wanted to thank the folks who reviewed our paper. Your feedback helped us improve our work, especially by asking us to include experiments on more difficult instances and the TSP. Thank you!
Still, many important problems with real-world applications, such as the TSP and program synthesis, share some of the properties we assume in this work.
June 13, 2025 at 3:29 AM
Still, many important problems with real-world applications, such as the TSP and program synthesis, share some of the properties we assume in this work.
The work has a few limitations. The policy learning scheme was evaluated only on needle-in-the-haystack deterministic problems. Also, since we are using tree search algorithms, we assume the agent has access to an efficient forward model.
June 13, 2025 at 3:29 AM
The work has a few limitations. The policy learning scheme was evaluated only on needle-in-the-haystack deterministic problems. Also, since we are using tree search algorithms, we assume the agent has access to an efficient forward model.
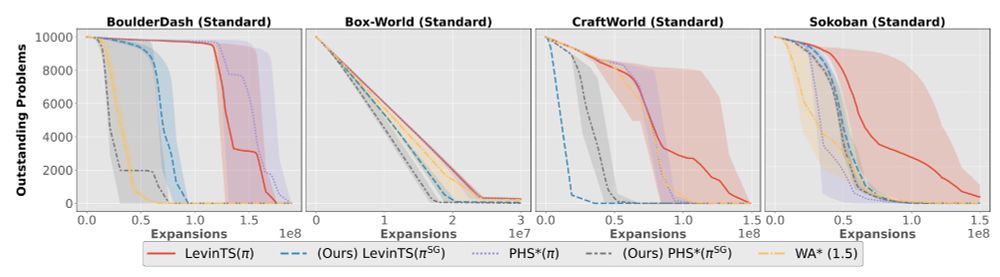
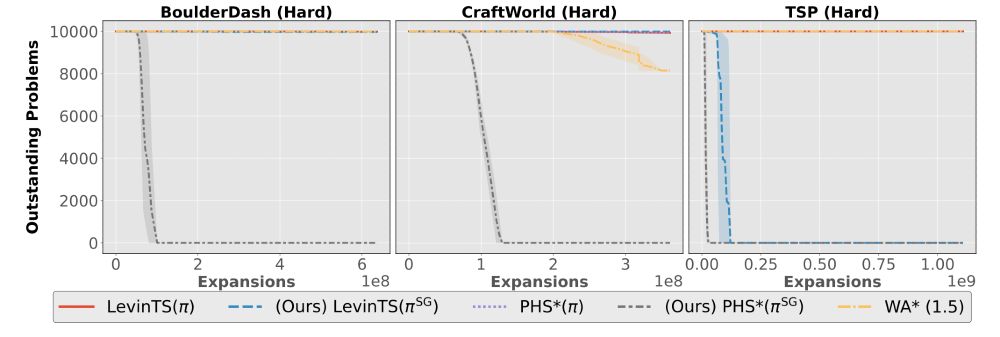
In other cases, where clustering seems unable to find relevant structure, the subgoal-based policies do not seem to harm the search, as in Sokoban problems.
June 13, 2025 at 3:29 AM
In other cases, where clustering seems unable to find relevant structure, the subgoal-based policies do not seem to harm the search, as in Sokoban problems.
The empirical results are strong when clustering effectively detects the problem's underlying structure.
June 13, 2025 at 3:29 AM
The empirical results are strong when clustering effectively detects the problem's underlying structure.