




Bradley Love
@profdata.bsky.social
Senior research scientist at Los Alamos National Laboratory. Former UCL, UTexas, Alan Turing Institute, Ellis EU. CogSci, AI, Comp Neuro, AI for scientific discovery https://bradlove.org
We developed a straightforward method of combining confidence-weighted judgments for any number of humans and AIs. w Felipe Yáñez, Omar Valerio Minero, @ken-lxl.bsky.social 2/2

November 25, 2025 at 7:05 PM
We developed a straightforward method of combining confidence-weighted judgments for any number of humans and AIs. w Felipe Yáñez, Omar Valerio Minero, @ken-lxl.bsky.social 2/2
New blog, "Backwards Compatible: The Strange Math Behind Word Order in AI" w @ken-lxl.bsky.social It turns out the language learning problem is the same for any word order, but is that true in practice for large language models? paper: arxiv.org/abs/2505.08739 BLOG: bradlove.org/blog/prob-ll...

May 28, 2025 at 2:15 PM
New blog, "Backwards Compatible: The Strange Math Behind Word Order in AI" w @ken-lxl.bsky.social It turns out the language learning problem is the same for any word order, but is that true in practice for large language models? paper: arxiv.org/abs/2505.08739 BLOG: bradlove.org/blog/prob-ll...
Finally, LLMs can be augmented with neuroscience knowledge for better performance. We tuned Mistral on 20 years of the neuroscience literature using LoRA. The tuned model, which we refer to as BrainGPT, performed better on BrainBench. 7/8

November 27, 2024 at 2:13 PM
Finally, LLMs can be augmented with neuroscience knowledge for better performance. We tuned Mistral on 20 years of the neuroscience literature using LoRA. The tuned model, which we refer to as BrainGPT, performed better on BrainBench. 7/8
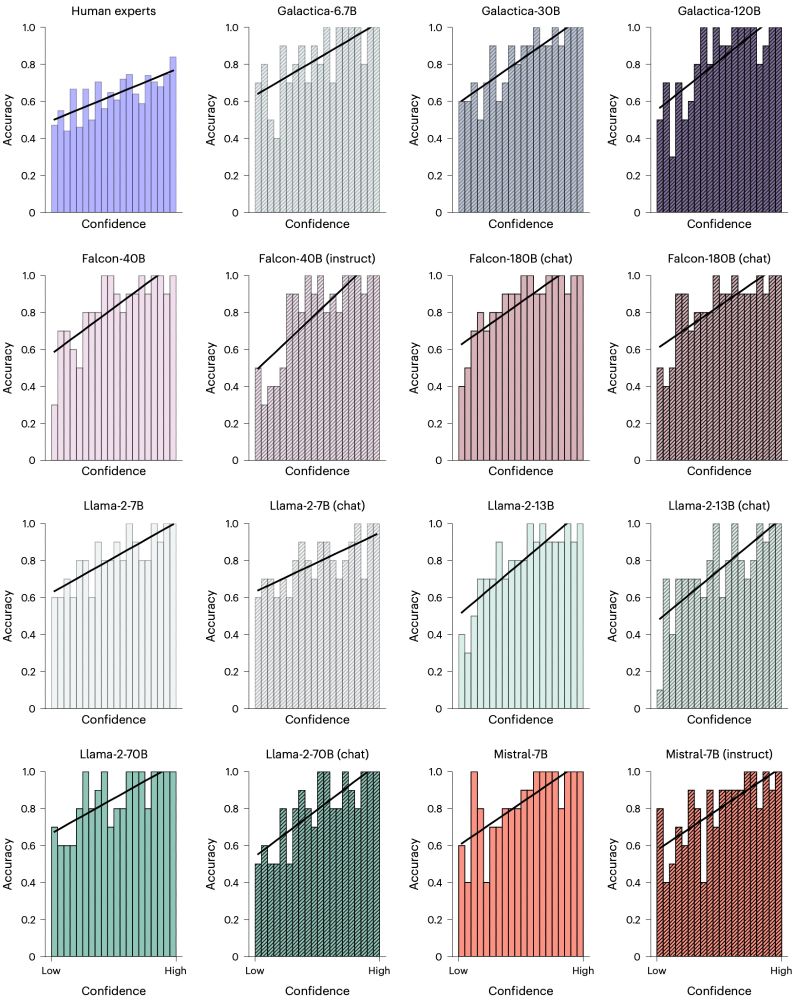
In the Nature HB paper, both human experts and LLMs were well calibrated - when they were more certain of their decisions, they were more likely to be correct. Calibration is beneficial for human-machine teaming. 5/8
November 27, 2024 at 2:13 PM
In the Nature HB paper, both human experts and LLMs were well calibrated - when they were more certain of their decisions, they were more likely to be correct. Calibration is beneficial for human-machine teaming. 5/8
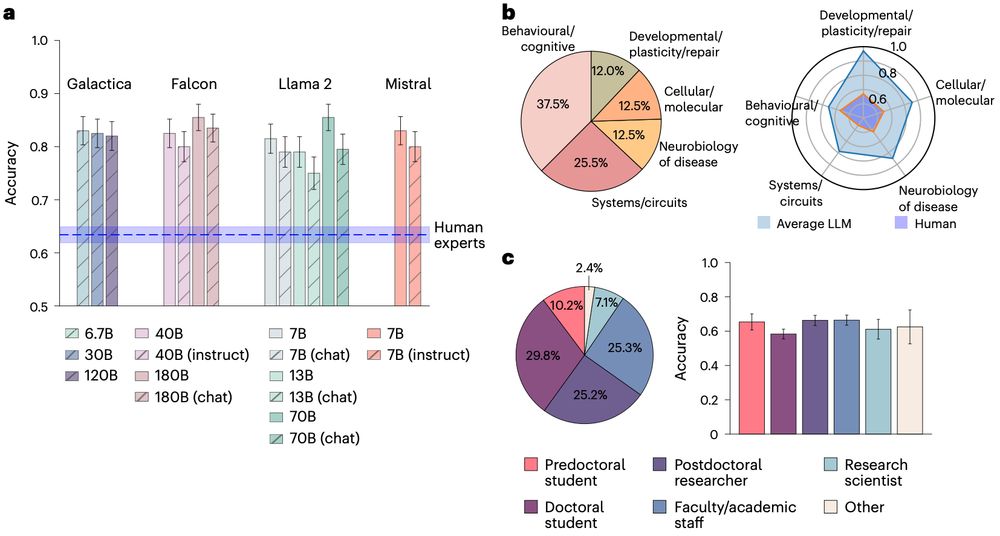
All 15 LLMs considered crushed human experts at BrainBench's predictive task. LLMs correctly predicted neuroscience results (across all sub areas) dramatically better than human experts, including those with decades of experience. 3/8
November 27, 2024 at 2:13 PM
All 15 LLMs considered crushed human experts at BrainBench's predictive task. LLMs correctly predicted neuroscience results (across all sub areas) dramatically better than human experts, including those with decades of experience. 3/8
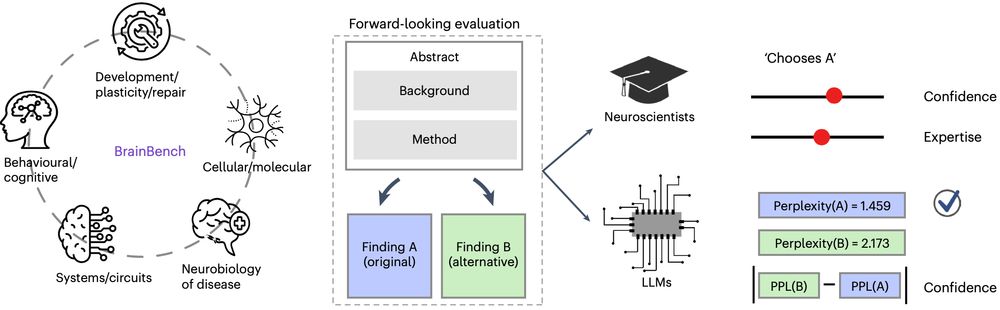
To test, we created BrainBench, a forward-looking benchmark that stresses prediction over retrieval of facts, avoiding LLM's "hallucination" issue. The task was to predict which version of a Journal of Neuroscience abstract gave the actual result. 2/6
November 27, 2024 at 2:13 PM
To test, we created BrainBench, a forward-looking benchmark that stresses prediction over retrieval of facts, avoiding LLM's "hallucination" issue. The task was to predict which version of a Journal of Neuroscience abstract gave the actual result. 2/6
"Large language models surpass human experts in predicting neuroscience results" w @ken-lxl.bsky.social
and braingpt.org. LLMs integrate a noisy yet interrelated scientific literature to forecast outcomes. nature.com/articles/s41... 1/8
and braingpt.org. LLMs integrate a noisy yet interrelated scientific literature to forecast outcomes. nature.com/articles/s41... 1/8

November 27, 2024 at 2:13 PM
"Large language models surpass human experts in predicting neuroscience results" w @ken-lxl.bsky.social
and braingpt.org. LLMs integrate a noisy yet interrelated scientific literature to forecast outcomes. nature.com/articles/s41... 1/8
and braingpt.org. LLMs integrate a noisy yet interrelated scientific literature to forecast outcomes. nature.com/articles/s41... 1/8
"Beyond Human-Like Processing: Large Language Models Perform Equivalently on Forward and Backward Scientific Text" Our take is that large language models (LLMs) are neither stochastic parrots nor faithful models of human language processing. arxiv.org/abs/2411.11061 1/2

November 19, 2024 at 1:21 PM
"Beyond Human-Like Processing: Large Language Models Perform Equivalently on Forward and Backward Scientific Text" Our take is that large language models (LLMs) are neither stochastic parrots nor faithful models of human language processing. arxiv.org/abs/2411.11061 1/2
LLMs can be augmented with neuroscience knowledge for better performance. We tuned Llama-2-7b (chat) on 20 years of the neuroscience literature using LoRA. The tuned model, which we refer to as BrainGPT, performed better on BrainBench. 5/6

March 7, 2024 at 10:51 AM
LLMs can be augmented with neuroscience knowledge for better performance. We tuned Llama-2-7b (chat) on 20 years of the neuroscience literature using LoRA. The tuned model, which we refer to as BrainGPT, performed better on BrainBench. 5/6
Both human experts and LLMs were well calibrated - when they were more certain of their decisions, they were more likely to be correct. Calibration is beneficial for human-machine teaming. 4/6

March 7, 2024 at 10:50 AM
Both human experts and LLMs were well calibrated - when they were more certain of their decisions, they were more likely to be correct. Calibration is beneficial for human-machine teaming. 4/6
All 15 LLMs considered crushed human experts at BrainBench's predictive task. LLMs correctly predicted neuroscience results (across all sub areas) dramatically better than human experts, including those with decades of experience. 3/6

March 7, 2024 at 10:50 AM
All 15 LLMs considered crushed human experts at BrainBench's predictive task. LLMs correctly predicted neuroscience results (across all sub areas) dramatically better than human experts, including those with decades of experience. 3/6
To test, we created BrainBench, a forward-looking benchmark that stresses prediction over retrieval of facts, avoiding LLM's "hallucination" issue. The task was to predict which version of a Journal of Neuroscience abstract gave the actual result. 2/6

March 7, 2024 at 10:49 AM
To test, we created BrainBench, a forward-looking benchmark that stresses prediction over retrieval of facts, avoiding LLM's "hallucination" issue. The task was to predict which version of a Journal of Neuroscience abstract gave the actual result. 2/6
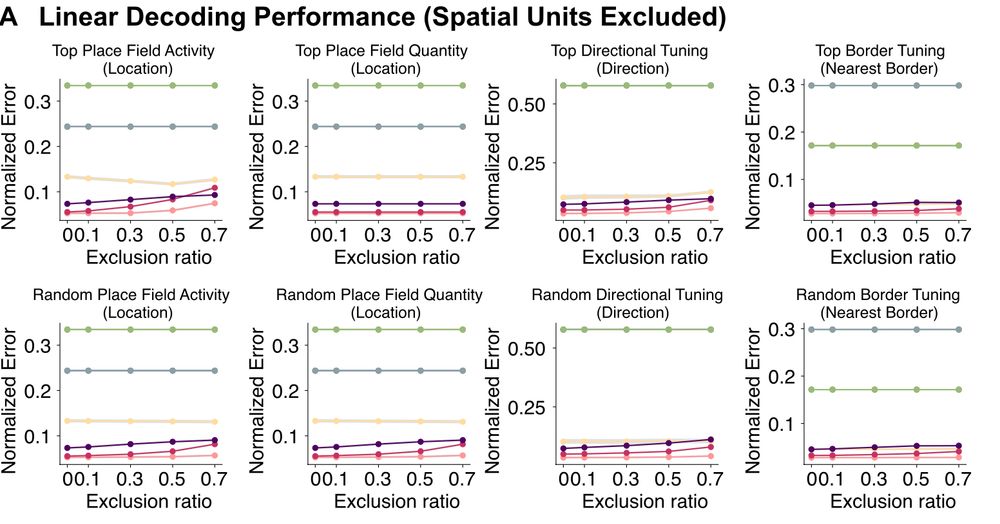
Further, excluding these "spatial" units has little affect on decoding performance. They are SUPERFLUOUS. 5/6
January 18, 2024 at 2:49 PM
Further, excluding these "spatial" units has little affect on decoding performance. They are SUPERFLUOUS. 5/6
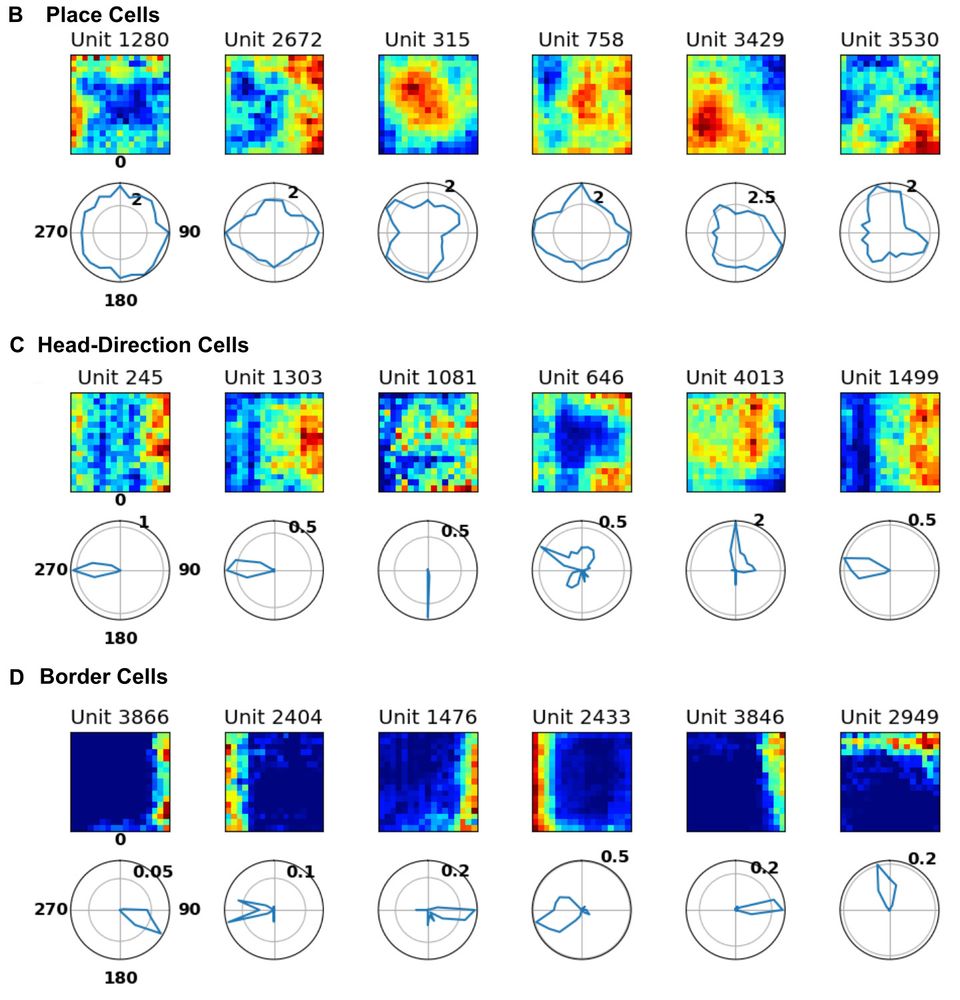
All your favorite cell types can be found in these models, despite these networks performing decidedly non-spatial functions. Units with these response properties appear INEVITABLE in complex networks, including random nets. 4/6
January 18, 2024 at 2:48 PM
All your favorite cell types can be found in these models, despite these networks performing decidedly non-spatial functions. Units with these response properties appear INEVITABLE in complex networks, including random nets. 4/6
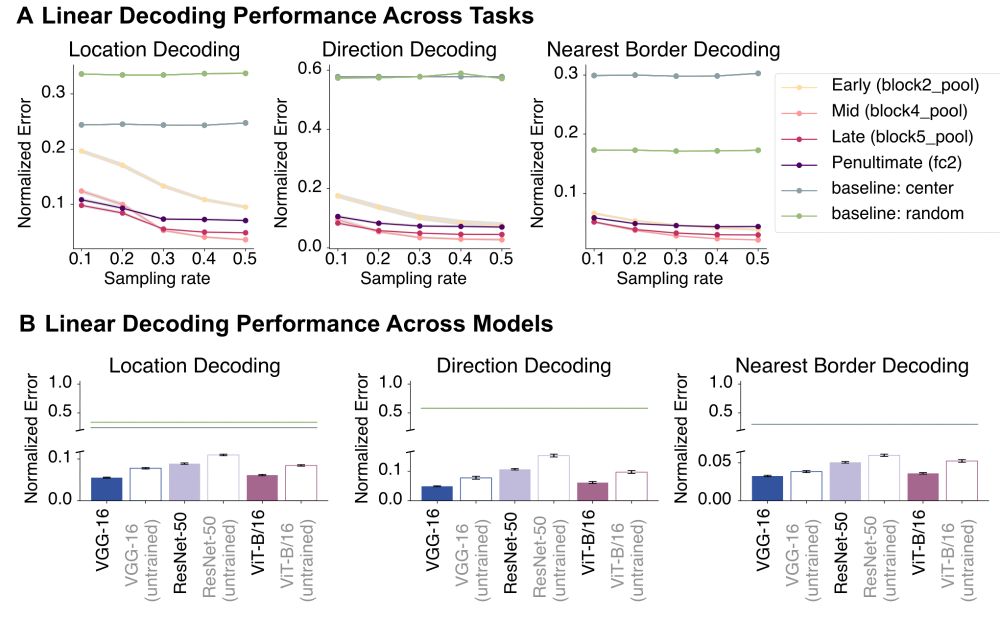
Object recognition models are non-spatial. Indeed, they are trained to be translation invariant. Nevertheless, direction and position are easily decoded from these models, including visual transformers and convolution nets with random weights. 3/6
January 18, 2024 at 2:48 PM
Object recognition models are non-spatial. Indeed, they are trained to be translation invariant. Nevertheless, direction and position are easily decoded from these models, including visual transformers and convolution nets with random weights. 3/6
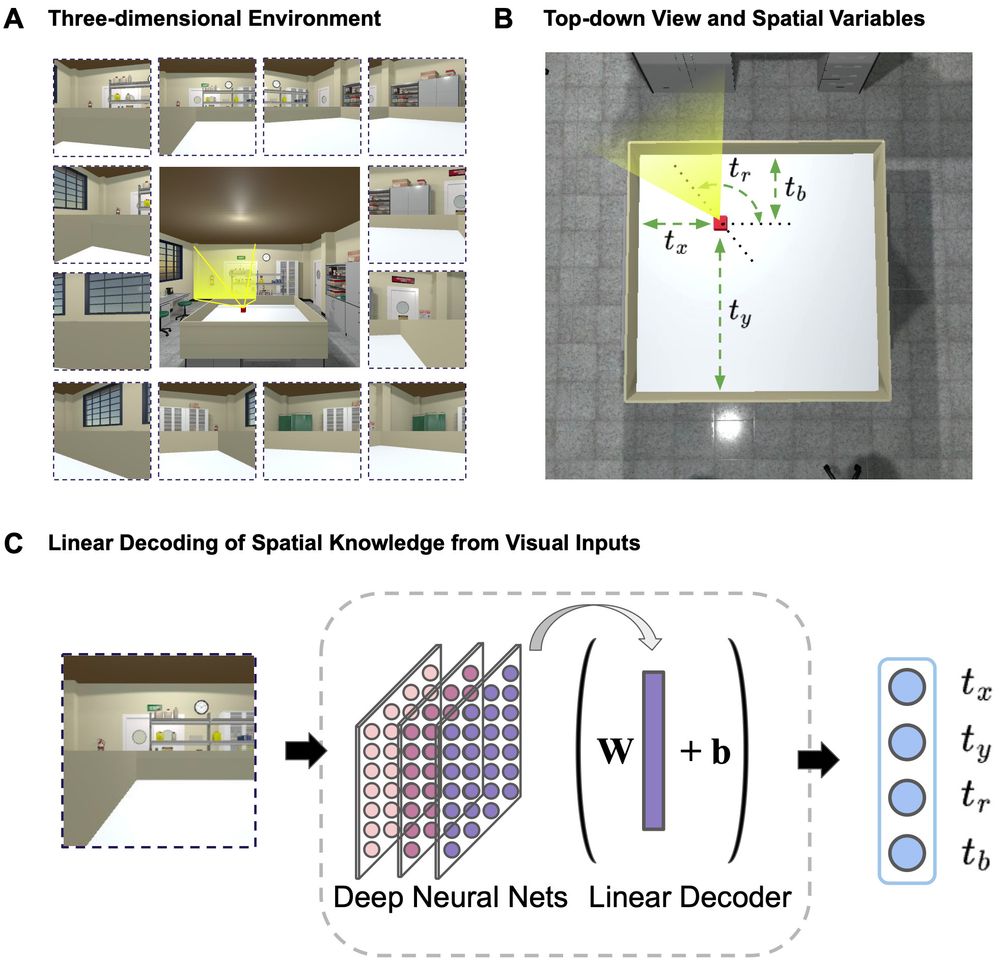
We find spatial cell types are (1) INEVITABLE: they occur in sufficiently complex (incl. random) networks and (2) SUPERFLUOUS: decoding is fine without these units. We tested an agent in a VR rodent enclosure with viewpoints as inputs to a deep net for object recognition. 2/6
January 18, 2024 at 2:47 PM
We find spatial cell types are (1) INEVITABLE: they occur in sufficiently complex (incl. random) networks and (2) SUPERFLUOUS: decoding is fine without these units. We tested an agent in a VR rodent enclosure with viewpoints as inputs to a deep net for object recognition. 2/6
Neuroscientists, please complete the BrainGPT.org survey to build a benchmark to develop and evaluate LLMs as tools for scientific discovery. Here's a link to the 11 question, 15-20 minute survey, research.sc/participant/... Below is a mock up of BrainGPT t-shirts we'll raffle off to participants.

December 18, 2023 at 8:11 PM
Neuroscientists, please complete the BrainGPT.org survey to build a benchmark to develop and evaluate LLMs as tools for scientific discovery. Here's a link to the 11 question, 15-20 minute survey, research.sc/participant/... Below is a mock up of BrainGPT t-shirts we'll raffle off to participants.