



Noam Brown
@polynoamial.bsky.social
Researching reasoning at OpenAI | Co-created Libratus/Pluribus superhuman poker AIs, CICERO Diplomacy AI, and OpenAI o-series / 🍓
GPT-5 Thinking isn’t perfect, but it’s the first AI model I can trust more than many common sources of truth on the internet.

August 25, 2025 at 9:39 AM
GPT-5 Thinking isn’t perfect, but it’s the first AI model I can trust more than many common sources of truth on the internet.
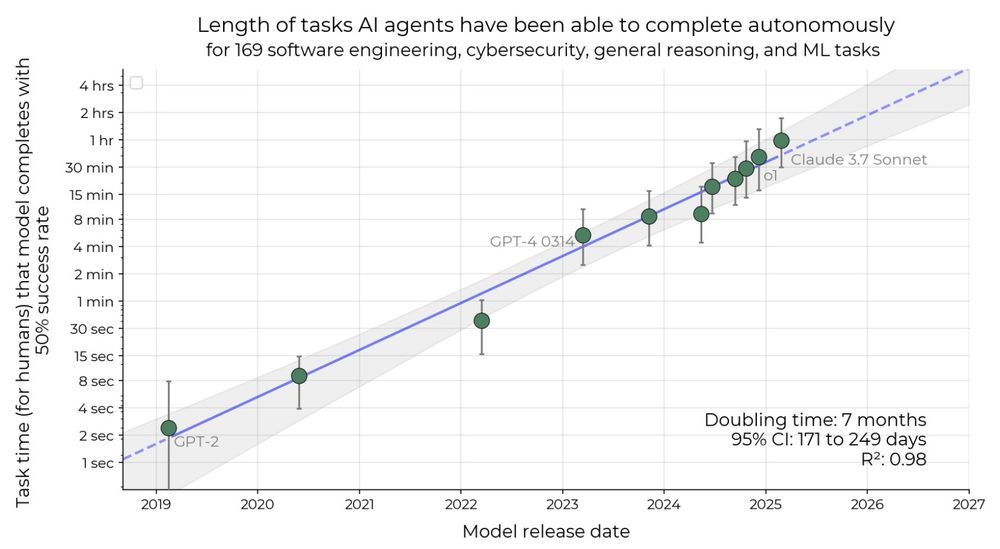
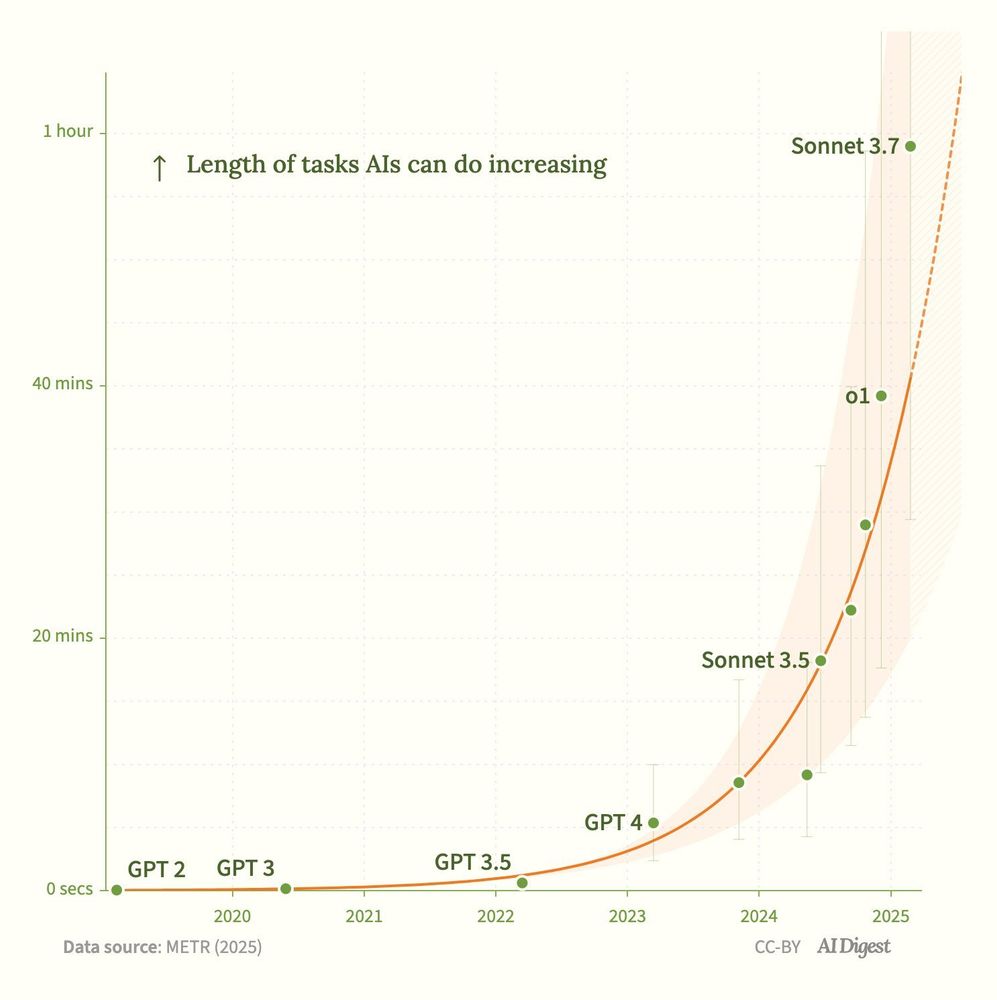
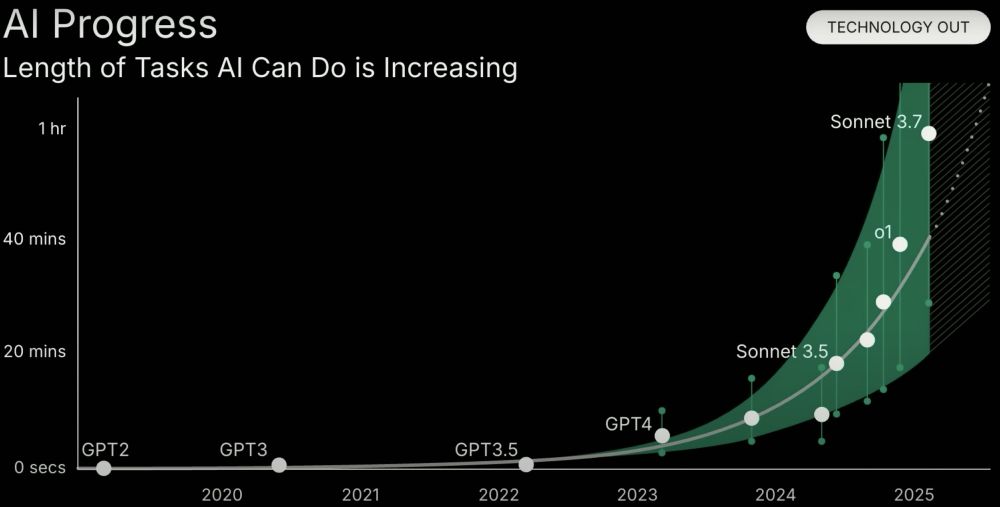
The paper itself does a good job highlighting the limitation. But notice the difference in the plot from the paper vs the plots that are commonly shared.
The paper is here: arxiv.org/pdf/2503.14499
The paper is here: arxiv.org/pdf/2503.14499

May 11, 2025 at 5:48 PM
The paper itself does a good job highlighting the limitation. But notice the difference in the plot from the paper vs the plots that are commonly shared.
The paper is here: arxiv.org/pdf/2503.14499
The paper is here: arxiv.org/pdf/2503.14499
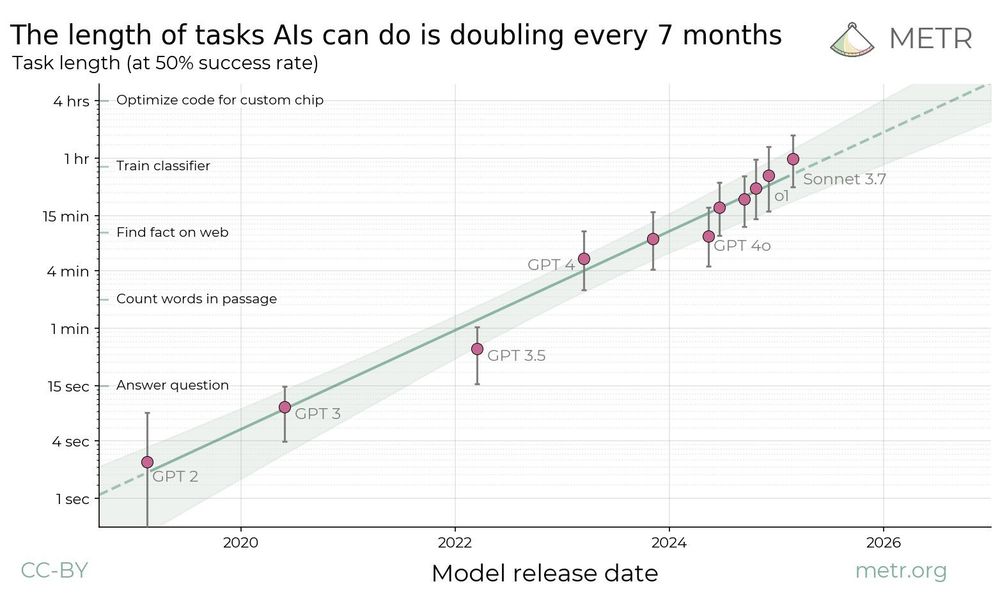
This METR "doubling every ∼7 mo" plot keeps popping up. It's striking, but let's be precise about what's measured: self‑contained code and ML tasks.
I think agentic AI may move faster than the METR trend, but we should report the data faithfully rather than over‑generalize to fit a belief we hold.
I think agentic AI may move faster than the METR trend, but we should report the data faithfully rather than over‑generalize to fit a belief we hold.
May 11, 2025 at 5:48 PM
This METR "doubling every ∼7 mo" plot keeps popping up. It's striking, but let's be precise about what's measured: self‑contained code and ML tasks.
I think agentic AI may move faster than the METR trend, but we should report the data faithfully rather than over‑generalize to fit a belief we hold.
I think agentic AI may move faster than the METR trend, but we should report the data faithfully rather than over‑generalize to fit a belief we hold.
I recently made this plot for a talk I gave on AI progress and it helped me appreciate how quickly AI models are improving.
I know there's still a lot of benchmarks where progress is flat, but progress on Codeforces was quite flat for a long time too.
I know there's still a lot of benchmarks where progress is flat, but progress on Codeforces was quite flat for a long time too.
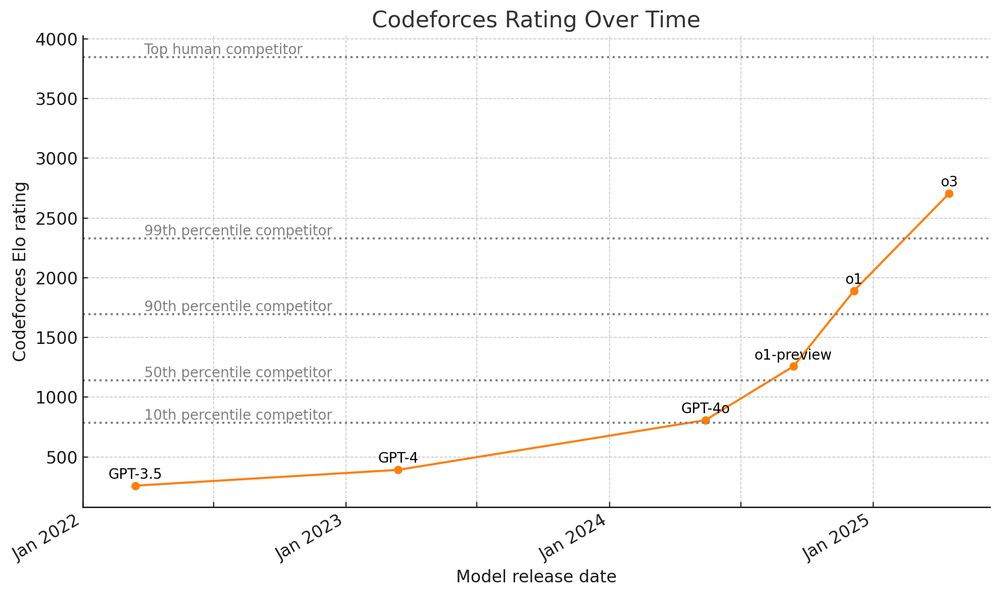
May 3, 2025 at 7:37 PM
I recently made this plot for a talk I gave on AI progress and it helped me appreciate how quickly AI models are improving.
I know there's still a lot of benchmarks where progress is flat, but progress on Codeforces was quite flat for a long time too.
I know there's still a lot of benchmarks where progress is flat, but progress on Codeforces was quite flat for a long time too.
Today, we're releasing OpenAI o3/o4-mini. The eval numbers are SOTA (2700 Elo is among the top 200 competition coders)
But what I'm most excited about is the stuff we can't benchmark. I expect o3/o4-mini will aid scientists in their research and I'm excited to see what they do!
But what I'm most excited about is the stuff we can't benchmark. I expect o3/o4-mini will aid scientists in their research and I'm excited to see what they do!
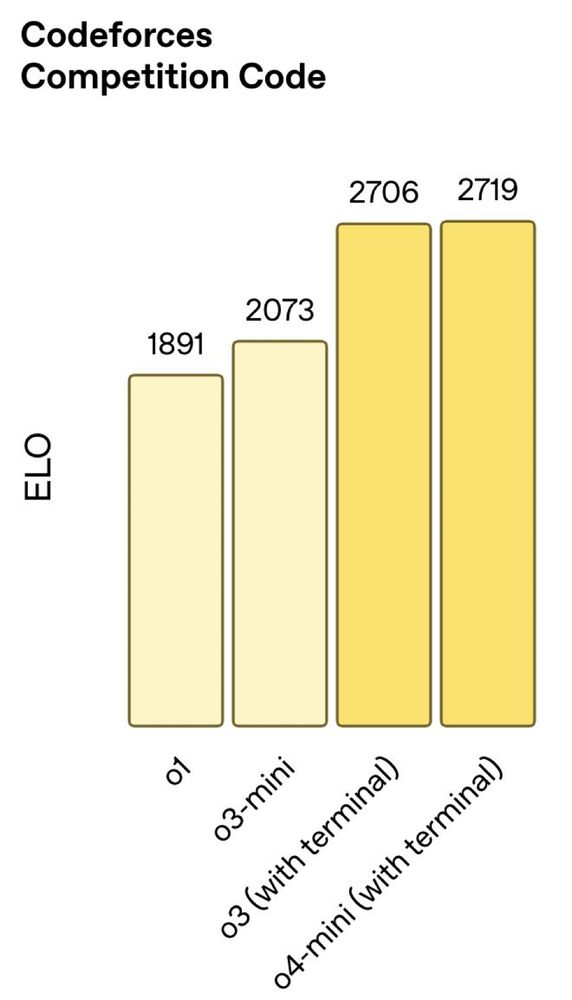
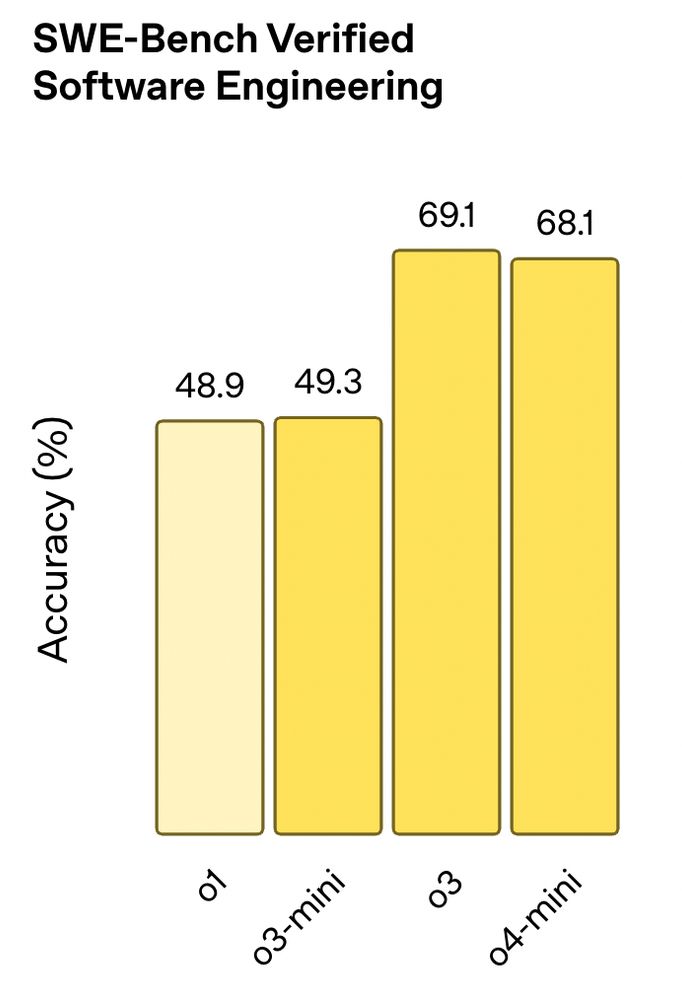
April 16, 2025 at 5:33 PM
Today, we're releasing OpenAI o3/o4-mini. The eval numbers are SOTA (2700 Elo is among the top 200 competition coders)
But what I'm most excited about is the stuff we can't benchmark. I expect o3/o4-mini will aid scientists in their research and I'm excited to see what they do!
But what I'm most excited about is the stuff we can't benchmark. I expect o3/o4-mini will aid scientists in their research and I'm excited to see what they do!
Our latest OpenAI model in the API, GPT-4.1, achieves 55% on SWE-Bench Verified *without being a reasoning model*. It also has 1M token context. Michelle Pokrass and team did an amazing job on this! Blog post with more details: openai.com/index/gpt-4-1/
(New reasoning models coming soon too.)
(New reasoning models coming soon too.)

April 14, 2025 at 5:40 PM
Our latest OpenAI model in the API, GPT-4.1, achieves 55% on SWE-Bench Verified *without being a reasoning model*. It also has 1M token context. Michelle Pokrass and team did an amazing job on this! Blog post with more details: openai.com/index/gpt-4-1/
(New reasoning models coming soon too.)
(New reasoning models coming soon too.)
Today, OpenAI is starting to roll out a new memory feature to ChatGPT. It signals a shift from episodic interactions (call center) to evolving ones (colleague or friend).
Still a lot of research to do but it's a step toward fundamentally changing how we interact with LLMs openai.com/index/memory...
Still a lot of research to do but it's a step toward fundamentally changing how we interact with LLMs openai.com/index/memory...

April 10, 2025 at 5:47 PM
Today, OpenAI is starting to roll out a new memory feature to ChatGPT. It signals a shift from episodic interactions (call center) to evolving ones (colleague or friend).
Still a lot of research to do but it's a step toward fundamentally changing how we interact with LLMs openai.com/index/memory...
Still a lot of research to do but it's a step toward fundamentally changing how we interact with LLMs openai.com/index/memory...
LLM evals are slow to adapt. MMLU/GSM8K continued to be reported long after they were obsolete. I think the next thing to go away will be comparing models on evals by a single number. Intelligence/$ is a much better metric. I loved this plot from o1-mini's blog for example openai.com/index/openai...
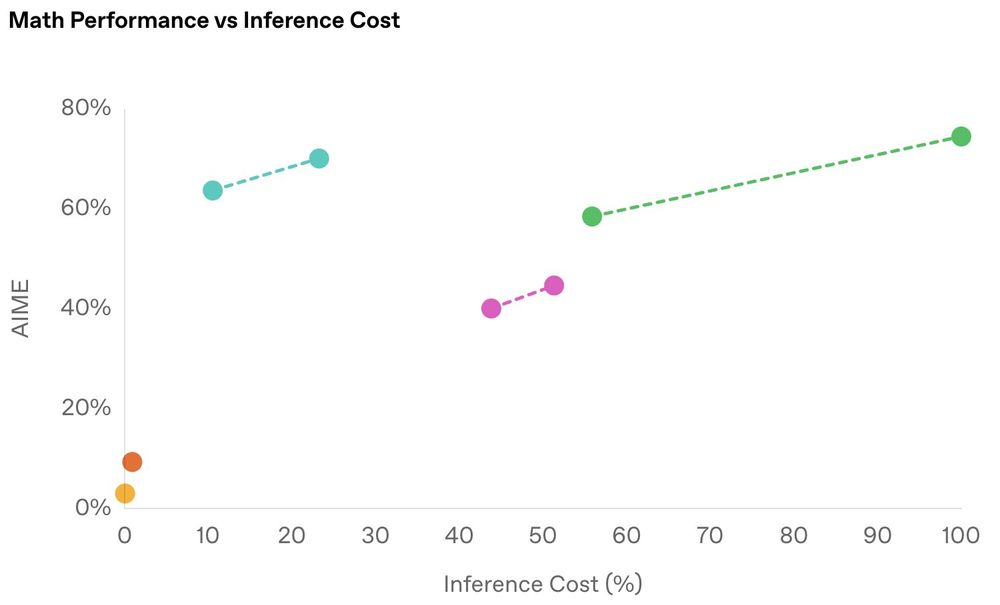
February 21, 2025 at 2:56 AM
LLM evals are slow to adapt. MMLU/GSM8K continued to be reported long after they were obsolete. I think the next thing to go away will be comparing models on evals by a single number. Intelligence/$ is a much better metric. I loved this plot from o1-mini's blog for example openai.com/index/openai...
o3-mini is the first LLM released that can consistently play tic-tac-toe well.
The summarized CoT is pretty unhinged but you can see on the right that by the end it figures it out.
The summarized CoT is pretty unhinged but you can see on the right that by the end it figures it out.
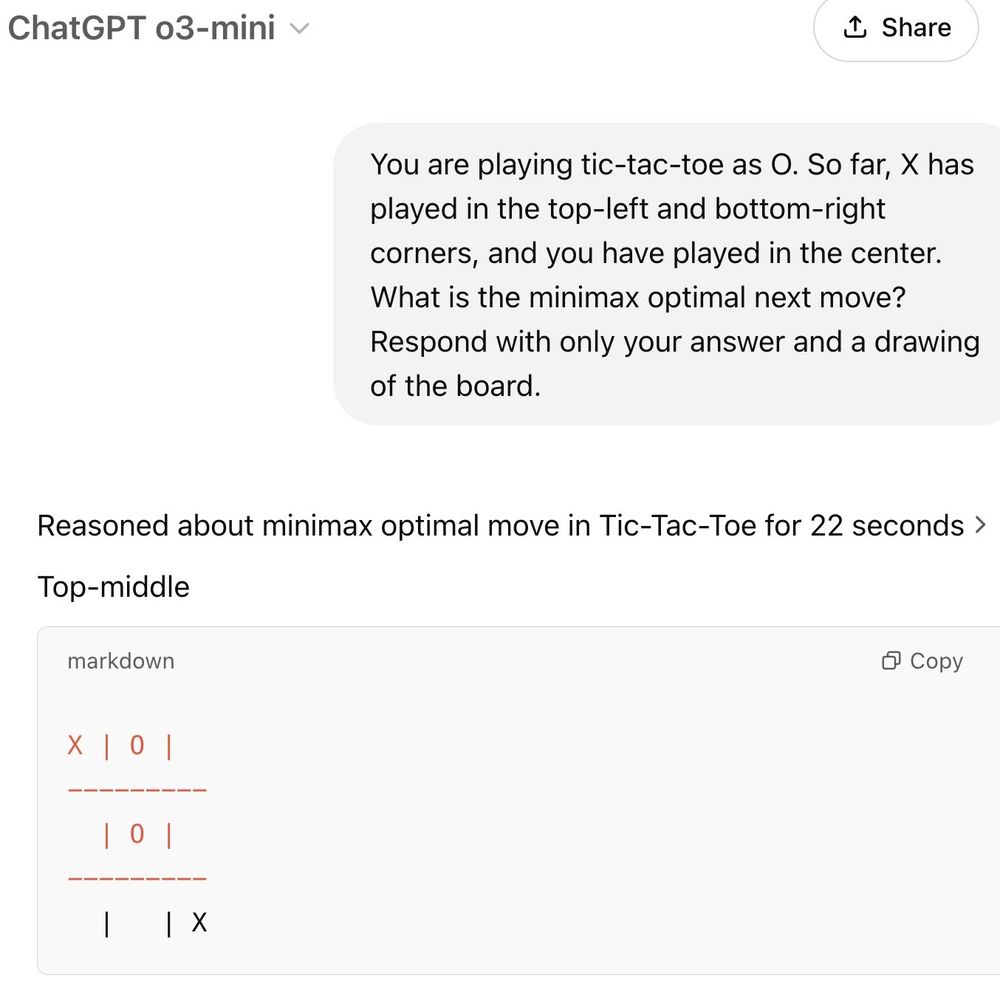

February 8, 2025 at 10:31 PM
o3-mini is the first LLM released that can consistently play tic-tac-toe well.
The summarized CoT is pretty unhinged but you can see on the right that by the end it figures it out.
The summarized CoT is pretty unhinged but you can see on the right that by the end it figures it out.