



Pietro Lesci
@pietrolesci.bsky.social
PhD student at Cambridge University. Causality & language models. Passionate musician, professional debugger.
pietrolesci.github.io
pietrolesci.github.io
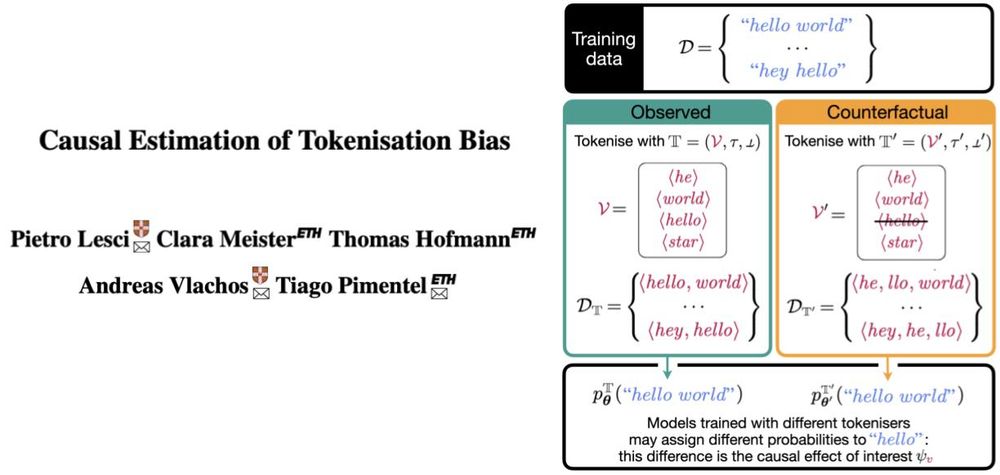
The trick: tokenisers build vocabs incrementally up to a fixed size (e.g., 32k). This defines a "cutoff": tokens near it are similar (e.g., frequency), but those inside appear as one while those outside as two symbols. Perfect setup for regression discontinuity! Details in 📄!

June 5, 2025 at 10:43 AM
The trick: tokenisers build vocabs incrementally up to a fixed size (e.g., 32k). This defines a "cutoff": tokens near it are similar (e.g., frequency), but those inside appear as one while those outside as two symbols. Perfect setup for regression discontinuity! Details in 📄!
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
June 5, 2025 at 10:43 AM
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
✈️ Headed to @iclr-conf.bsky.social — whether you’ll be there in person or tuning in remotely, I’d love to connect!
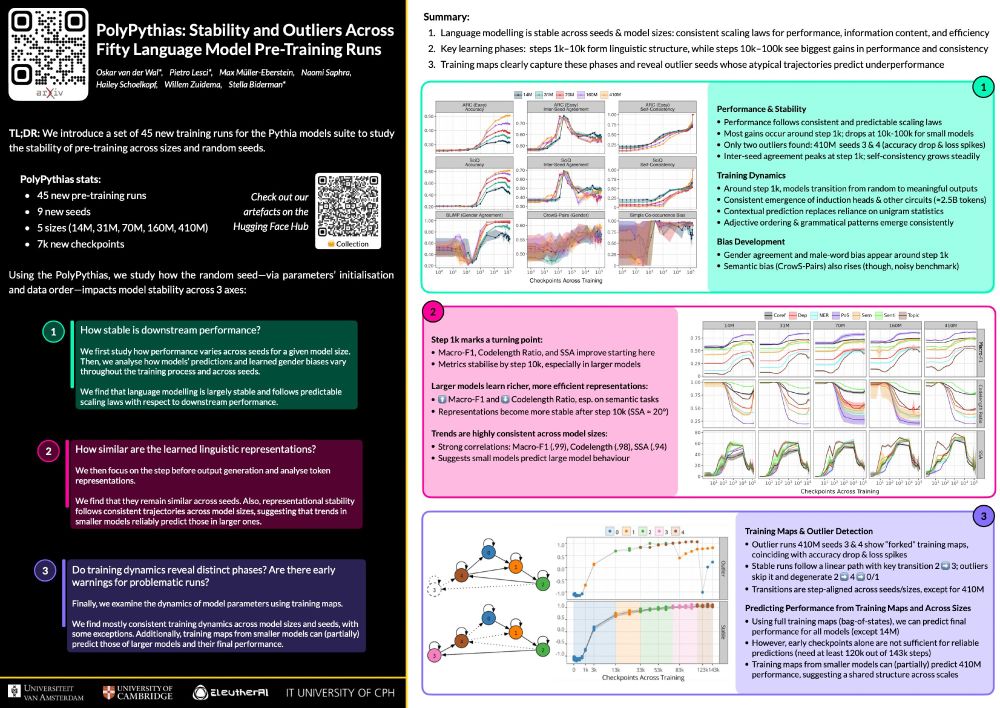
We’ll be presenting our paper on pre-training stability in language models and the PolyPythias 🧵
🔗 ArXiv: arxiv.org/abs/2503.09543
🤗 PolyPythias: huggingface.co/collections/...
We’ll be presenting our paper on pre-training stability in language models and the PolyPythias 🧵
🔗 ArXiv: arxiv.org/abs/2503.09543
🤗 PolyPythias: huggingface.co/collections/...
April 22, 2025 at 11:02 AM
✈️ Headed to @iclr-conf.bsky.social — whether you’ll be there in person or tuning in remotely, I’d love to connect!
We’ll be presenting our paper on pre-training stability in language models and the PolyPythias 🧵
🔗 ArXiv: arxiv.org/abs/2503.09543
🤗 PolyPythias: huggingface.co/collections/...
We’ll be presenting our paper on pre-training stability in language models and the PolyPythias 🧵
🔗 ArXiv: arxiv.org/abs/2503.09543
🤗 PolyPythias: huggingface.co/collections/...