



Pierre Chambon
@pierrechambon.bsky.social
PhD at FAIR (Meta) and INRIA
Former researcher at Stanford University
Former researcher at Stanford University
As they use no reasoning tokens and leverage MoE with only 17B active tokens, both Maverick and Scout are much faster compared to reasoning models 🏎️🏁.
To generate ~50% of Time Complexity Generation responses, QwQ takes ~30mn whereas Llama 4 needs only a few dozens seconds 🥳.
To generate ~50% of Time Complexity Generation responses, QwQ takes ~30mn whereas Llama 4 needs only a few dozens seconds 🥳.
April 16, 2025 at 3:05 PM
As they use no reasoning tokens and leverage MoE with only 17B active tokens, both Maverick and Scout are much faster compared to reasoning models 🏎️🏁.
To generate ~50% of Time Complexity Generation responses, QwQ takes ~30mn whereas Llama 4 needs only a few dozens seconds 🥳.
To generate ~50% of Time Complexity Generation responses, QwQ takes ~30mn whereas Llama 4 needs only a few dozens seconds 🥳.
🏡Homepage: facebookresearch.github.io/BigOBench
🏆Leaderboard: facebookresearch.github.io/BigOBench/leaderboard.html
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
🏆Leaderboard: facebookresearch.github.io/BigOBench/leaderboard.html
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
BigO(Bench)
BigOBench: Can LLMs Generate Code with Controlled Time and Space Complexity?
facebookresearch.github.io
April 16, 2025 at 3:05 PM
🏡Homepage: facebookresearch.github.io/BigOBench
🏆Leaderboard: facebookresearch.github.io/BigOBench/leaderboard.html
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
🏆Leaderboard: facebookresearch.github.io/BigOBench/leaderboard.html
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
🤲OpenHands LM is not a reasoning model, which de facto makes its inference cost way lower than the SOTA models on BigO(Bench).
It is best on Complexity Predictions tasks, where it even outperforms o1-mini!🎉 But it falls behind on Generation and Ranking tasks.
It is best on Complexity Predictions tasks, where it even outperforms o1-mini!🎉 But it falls behind on Generation and Ranking tasks.
April 10, 2025 at 4:11 PM
🤲OpenHands LM is not a reasoning model, which de facto makes its inference cost way lower than the SOTA models on BigO(Bench).
It is best on Complexity Predictions tasks, where it even outperforms o1-mini!🎉 But it falls behind on Generation and Ranking tasks.
It is best on Complexity Predictions tasks, where it even outperforms o1-mini!🎉 But it falls behind on Generation and Ranking tasks.
🧑💻DeepCoder model displays impressive performance, but suffered from limited inference compute on BigO(Bench).
Though our inference budget is large (enough for reasoning models like QwQ, R1 or Nemotron-Ultra 🥵), DeepCoder responses seemed to take even longer.
Though our inference budget is large (enough for reasoning models like QwQ, R1 or Nemotron-Ultra 🥵), DeepCoder responses seemed to take even longer.
April 10, 2025 at 4:11 PM
🧑💻DeepCoder model displays impressive performance, but suffered from limited inference compute on BigO(Bench).
Though our inference budget is large (enough for reasoning models like QwQ, R1 or Nemotron-Ultra 🥵), DeepCoder responses seemed to take even longer.
Though our inference budget is large (enough for reasoning models like QwQ, R1 or Nemotron-Ultra 🥵), DeepCoder responses seemed to take even longer.
🏆NVIDIA Nemotron include an 8B, 49B and 253B, the latter being the one benchmarked, with deep thinking on.
Nemotron-Ultra 253B displays high and consistent performance on BigO(Bench) (very often on the podium). It takes the lead on Space Complexity Generation and Ranking!🥳
Nemotron-Ultra 253B displays high and consistent performance on BigO(Bench) (very often on the podium). It takes the lead on Space Complexity Generation and Ranking!🥳
April 10, 2025 at 4:11 PM
🏆NVIDIA Nemotron include an 8B, 49B and 253B, the latter being the one benchmarked, with deep thinking on.
Nemotron-Ultra 253B displays high and consistent performance on BigO(Bench) (very often on the podium). It takes the lead on Space Complexity Generation and Ranking!🥳
Nemotron-Ultra 253B displays high and consistent performance on BigO(Bench) (very often on the podium). It takes the lead on Space Complexity Generation and Ranking!🥳
🏡Homepage: facebookresearch.github.io/BigOBench
🏆Leaderboard: facebookresearch.github.io/BigOBench/leaderboard.html
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
🏆Leaderboard: facebookresearch.github.io/BigOBench/leaderboard.html
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
BigO(Bench)
BigOBench: Can LLMs Generate Code with Controlled Time and Space Complexity?
facebookresearch.github.io
April 10, 2025 at 4:11 PM
🏡Homepage: facebookresearch.github.io/BigOBench
🏆Leaderboard: facebookresearch.github.io/BigOBench/leaderboard.html
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
🏆Leaderboard: facebookresearch.github.io/BigOBench/leaderboard.html
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
Thanks to everyone involved, Baptiste Roziere, @inriaparisnlp.bsky.social, @bensagot.bsky.social, @syhw.bsky.social!
📚ArXiv: arxiv.org/abs/2503.15242
🏡Homepage: facebookresearch.github.io/BigOBench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
🧵6/6
📚ArXiv: arxiv.org/abs/2503.15242
🏡Homepage: facebookresearch.github.io/BigOBench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
🧵6/6

BigO(Bench) -- Can LLMs Generate Code with Controlled Time and Space Complexity?
We introduce BigO(Bench), a novel coding benchmark designed to evaluate the capabilities of generative language models in understanding and generating code with specified time and space complexities. ...
arxiv.org
March 27, 2025 at 3:24 PM
Thanks to everyone involved, Baptiste Roziere, @inriaparisnlp.bsky.social, @bensagot.bsky.social, @syhw.bsky.social!
📚ArXiv: arxiv.org/abs/2503.15242
🏡Homepage: facebookresearch.github.io/BigOBench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
🧵6/6
📚ArXiv: arxiv.org/abs/2503.15242
🏡Homepage: facebookresearch.github.io/BigOBench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
🧵6/6
🤔Would you like to see any other model, newly released or more established in the LLM community, benchmarked on ✨BigO(Bench)✨?
👇Happy to provide details/help with any suggestion!
🧵5/6
👇Happy to provide details/help with any suggestion!
🧵5/6
March 27, 2025 at 3:24 PM
🤔Would you like to see any other model, newly released or more established in the LLM community, benchmarked on ✨BigO(Bench)✨?
👇Happy to provide details/help with any suggestion!
🧵5/6
👇Happy to provide details/help with any suggestion!
🧵5/6
🥈DeepseekV3-0324 performance is impressive as it uses no reasoning tokens, even outperforming DeepSeek on Time Complexity Generation by ~45% All@1.
These tasks usually require extensive reasoning skills; "thinking" steps easily take ~20k tokens.
🧵4/6
These tasks usually require extensive reasoning skills; "thinking" steps easily take ~20k tokens.
🧵4/6
March 27, 2025 at 3:24 PM
🥈DeepseekV3-0324 performance is impressive as it uses no reasoning tokens, even outperforming DeepSeek on Time Complexity Generation by ~45% All@1.
These tasks usually require extensive reasoning skills; "thinking" steps easily take ~20k tokens.
🧵4/6
These tasks usually require extensive reasoning skills; "thinking" steps easily take ~20k tokens.
🧵4/6
🥇QwQ displays impressive performance, pushing the SOTA on Time and Space Complexity Generation by 100% All@1 and 50% All@1 respectively.
On Time Complexity Ranking, QwQ also beats DeepSeekR1 distilled models by ~30% coeffFull, while being on par with DeepSeek on Space.
🧵3/6
On Time Complexity Ranking, QwQ also beats DeepSeekR1 distilled models by ~30% coeffFull, while being on par with DeepSeek on Space.
🧵3/6
March 27, 2025 at 3:24 PM
🥇QwQ displays impressive performance, pushing the SOTA on Time and Space Complexity Generation by 100% All@1 and 50% All@1 respectively.
On Time Complexity Ranking, QwQ also beats DeepSeekR1 distilled models by ~30% coeffFull, while being on par with DeepSeek on Space.
🧵3/6
On Time Complexity Ranking, QwQ also beats DeepSeekR1 distilled models by ~30% coeffFull, while being on par with DeepSeek on Space.
🧵3/6
📸Results snapshot !🏅
All these models have similar active parameters, DeepSeekV3-0324 being MoE with 37B active parameters.
Whereas DeepSeekR1 and QwQ use reasoning tokens (and therefore way more inference tokens), Gemma3 and DeepSeekV3-0324 directly output the result.
🧵2/6
All these models have similar active parameters, DeepSeekV3-0324 being MoE with 37B active parameters.
Whereas DeepSeekR1 and QwQ use reasoning tokens (and therefore way more inference tokens), Gemma3 and DeepSeekV3-0324 directly output the result.
🧵2/6

March 27, 2025 at 3:24 PM
📸Results snapshot !🏅
All these models have similar active parameters, DeepSeekV3-0324 being MoE with 37B active parameters.
Whereas DeepSeekR1 and QwQ use reasoning tokens (and therefore way more inference tokens), Gemma3 and DeepSeekV3-0324 directly output the result.
🧵2/6
All these models have similar active parameters, DeepSeekV3-0324 being MoE with 37B active parameters.
Whereas DeepSeekR1 and QwQ use reasoning tokens (and therefore way more inference tokens), Gemma3 and DeepSeekV3-0324 directly output the result.
🧵2/6
Big thanks to Baptiste Roziere, @inriaparisnlp.bsky.social, @bensagot.bsky.social and @syhw.bsky.social!
📚ArXiv: arxiv.org/abs/2503.15242
🏡🏆Homepage: facebookresearch.github.io/BigOBench
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
🏡🏆Homepage: facebookresearch.github.io/BigOBench
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
BigO(Bench) -- Can LLMs Generate Code with Controlled Time and Space Complexity?
We introduce BigO(Bench), a novel coding benchmark designed to evaluate the capabilities of generative language models in understanding and generating code with specified time and space complexities. ...
arxiv.org
March 20, 2025 at 4:48 PM
Big thanks to Baptiste Roziere, @inriaparisnlp.bsky.social, @bensagot.bsky.social and @syhw.bsky.social!
📚ArXiv: arxiv.org/abs/2503.15242
🏡🏆Homepage: facebookresearch.github.io/BigOBench
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
📚ArXiv: arxiv.org/abs/2503.15242
🏡🏆Homepage: facebookresearch.github.io/BigOBench
💻Github: github.com/facebookresearch/bigobench
🤗Huggingface: huggingface.co/datasets/facebook/BigOBench
Limitations remain, notably the complexity framework which is prone to errors, as for specific problems it can potentially miss worst-complexity edge cases. The measures it takes remain noisy, still relying on real CPU runtimes and using statistical measuring tools.
March 20, 2025 at 4:48 PM
Limitations remain, notably the complexity framework which is prone to errors, as for specific problems it can potentially miss worst-complexity edge cases. The measures it takes remain noisy, still relying on real CPU runtimes and using statistical measuring tools.
In the context of newly released benchmarks getting quickly saturated, BigO(Bench) aims at evaluating high-level reasoning skills that stay out-of-scope of current LLMs and are hard to train/reinforce upon, bringing their performance down.

March 20, 2025 at 4:48 PM
In the context of newly released benchmarks getting quickly saturated, BigO(Bench) aims at evaluating high-level reasoning skills that stay out-of-scope of current LLMs and are hard to train/reinforce upon, bringing their performance down.
Reasoning models struggle with the ambiguity of higher-level reasoning tasks, especially when there is no explicit verifier they were reinforced upon.
Do they really ‘think’ about notions they ‘know’, or do they only learn by heart patterns of ‘thoughts’ during training?
Do they really ‘think’ about notions they ‘know’, or do they only learn by heart patterns of ‘thoughts’ during training?
March 20, 2025 at 4:48 PM
Reasoning models struggle with the ambiguity of higher-level reasoning tasks, especially when there is no explicit verifier they were reinforced upon.
Do they really ‘think’ about notions they ‘know’, or do they only learn by heart patterns of ‘thoughts’ during training?
Do they really ‘think’ about notions they ‘know’, or do they only learn by heart patterns of ‘thoughts’ during training?
Models tend to under-perform on non-optimal complexity classes, compared to the most optimized class of every problem. This seems counterintuitive for
any human programmer, usually accustomed to easily
finding non-optimized solutions, but struggling at the
best ones.
any human programmer, usually accustomed to easily
finding non-optimized solutions, but struggling at the
best ones.

March 20, 2025 at 4:48 PM
Models tend to under-perform on non-optimal complexity classes, compared to the most optimized class of every problem. This seems counterintuitive for
any human programmer, usually accustomed to easily
finding non-optimized solutions, but struggling at the
best ones.
any human programmer, usually accustomed to easily
finding non-optimized solutions, but struggling at the
best ones.
LLMs struggle with Complexity Generation - generating code that meets specific complexity requirements -, underperforming in comparison to Complexity Prediction - predicting complexity of existing code - or generating code alone.
Token-space reasoning models perform best !
Token-space reasoning models perform best !
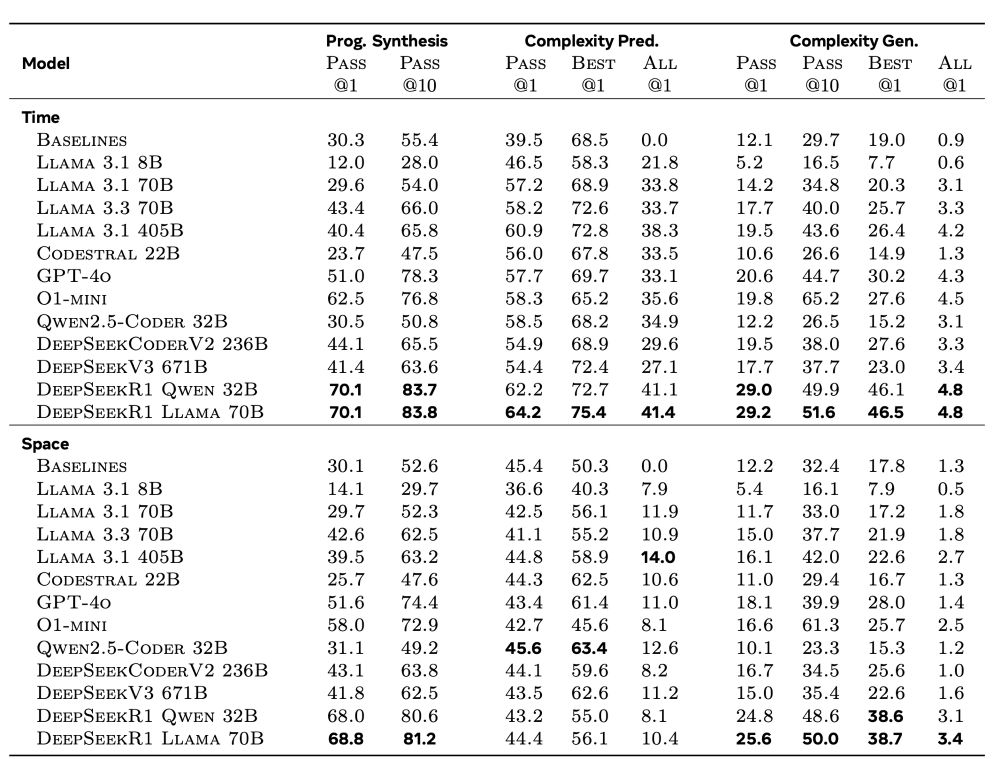
March 20, 2025 at 4:48 PM
LLMs struggle with Complexity Generation - generating code that meets specific complexity requirements -, underperforming in comparison to Complexity Prediction - predicting complexity of existing code - or generating code alone.
Token-space reasoning models perform best !
Token-space reasoning models perform best !
Utilizing 3,105 coding problems and 1,190,250 solutions from Code Contests, we applied the Complexity Framework to derive two test sets: one for Time Complexity (311 problems) and one for Space Complexity (308 problems), each problem comprising multiple complexity classes.
March 20, 2025 at 4:48 PM
Utilizing 3,105 coding problems and 1,190,250 solutions from Code Contests, we applied the Complexity Framework to derive two test sets: one for Time Complexity (311 problems) and one for Space Complexity (308 problems), each problem comprising multiple complexity classes.
Our Complexity Framework can analyze arbitrary Python code snippets, employing input generation methods to empirically measure runtime and memory footprint, thereby inferring complexity classes and corresponding curve coefficients without reliance on oracle models.
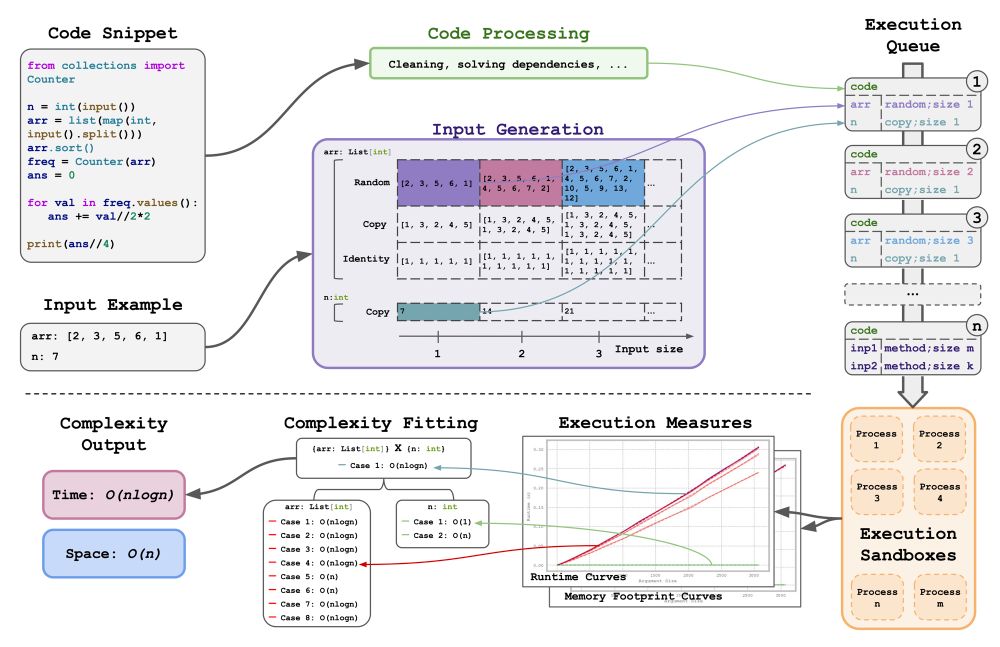
March 20, 2025 at 4:48 PM
Our Complexity Framework can analyze arbitrary Python code snippets, employing input generation methods to empirically measure runtime and memory footprint, thereby inferring complexity classes and corresponding curve coefficients without reliance on oracle models.
First, we developed a novel Dynamic Complexity Inference tool to measure Time/Space Complexity of code snippets 👉 Code is released!
The framework ran on ~1M Code Contests solutions 👉 Data is public too!
Lastly, we designed test sets and evaluated LLMs 👉 Leaderboard is out!
The framework ran on ~1M Code Contests solutions 👉 Data is public too!
Lastly, we designed test sets and evaluated LLMs 👉 Leaderboard is out!

March 20, 2025 at 4:48 PM
First, we developed a novel Dynamic Complexity Inference tool to measure Time/Space Complexity of code snippets 👉 Code is released!
The framework ran on ~1M Code Contests solutions 👉 Data is public too!
Lastly, we designed test sets and evaluated LLMs 👉 Leaderboard is out!
The framework ran on ~1M Code Contests solutions 👉 Data is public too!
Lastly, we designed test sets and evaluated LLMs 👉 Leaderboard is out!
Beyond generating code solutions, can LLMs answer the final Time/Space Complexity question of coding interviews ? 👨🏫
We investigate the performance of LLMs on 3 tasks:
✅ Time/Space Complexity Prediction
✅ Time/Space Complexity Generation
✅ Time/Space Complexity Ranking
We investigate the performance of LLMs on 3 tasks:
✅ Time/Space Complexity Prediction
✅ Time/Space Complexity Generation
✅ Time/Space Complexity Ranking

March 20, 2025 at 4:48 PM
Beyond generating code solutions, can LLMs answer the final Time/Space Complexity question of coding interviews ? 👨🏫
We investigate the performance of LLMs on 3 tasks:
✅ Time/Space Complexity Prediction
✅ Time/Space Complexity Generation
✅ Time/Space Complexity Ranking
We investigate the performance of LLMs on 3 tasks:
✅ Time/Space Complexity Prediction
✅ Time/Space Complexity Generation
✅ Time/Space Complexity Ranking