



Paul Brunzema
@pbrunzema.bsky.social
PhD student on learning-based control; interested in everything around Bayesian optimization and robotics
Our models are now also available in BoTorch - the go-to package for Bayesian optimization! This hopefully makes using VBLLs in your next project straightforward.
If you have any questions, feel free to reach out!
github.com/pytorch/boto...
If you have any questions, feel free to reach out!
github.com/pytorch/boto...

botorch/notebooks_community/vbll_thompson_sampling.ipynb at main · pytorch/botorch
Bayesian optimization in PyTorch. Contribute to pytorch/botorch development by creating an account on GitHub.
github.com
April 22, 2025 at 10:57 PM
Our models are now also available in BoTorch - the go-to package for Bayesian optimization! This hopefully makes using VBLLs in your next project straightforward.
If you have any questions, feel free to reach out!
github.com/pytorch/boto...
If you have any questions, feel free to reach out!
github.com/pytorch/boto...
This post is based on the X post from James Harrison (collaborator from DeepMind): x.com/jmes_harriso...
x.com
x.com
December 14, 2024 at 8:59 PM
This post is based on the X post from James Harrison (collaborator from DeepMind): x.com/jmes_harriso...
Our approach can be applied to a very very wide range of problems--we include multi-objective BayesOpt as an example, but we're excited about massively scaling up this approach on a ton of problems. Therefore, definitely reach out if you are interested!
Paper link here: arxiv.org/pdf/2412.09477
Paper link here: arxiv.org/pdf/2412.09477
arxiv.org
December 14, 2024 at 8:59 PM
Our approach can be applied to a very very wide range of problems--we include multi-objective BayesOpt as an example, but we're excited about massively scaling up this approach on a ton of problems. Therefore, definitely reach out if you are interested!
Paper link here: arxiv.org/pdf/2412.09477
Paper link here: arxiv.org/pdf/2412.09477
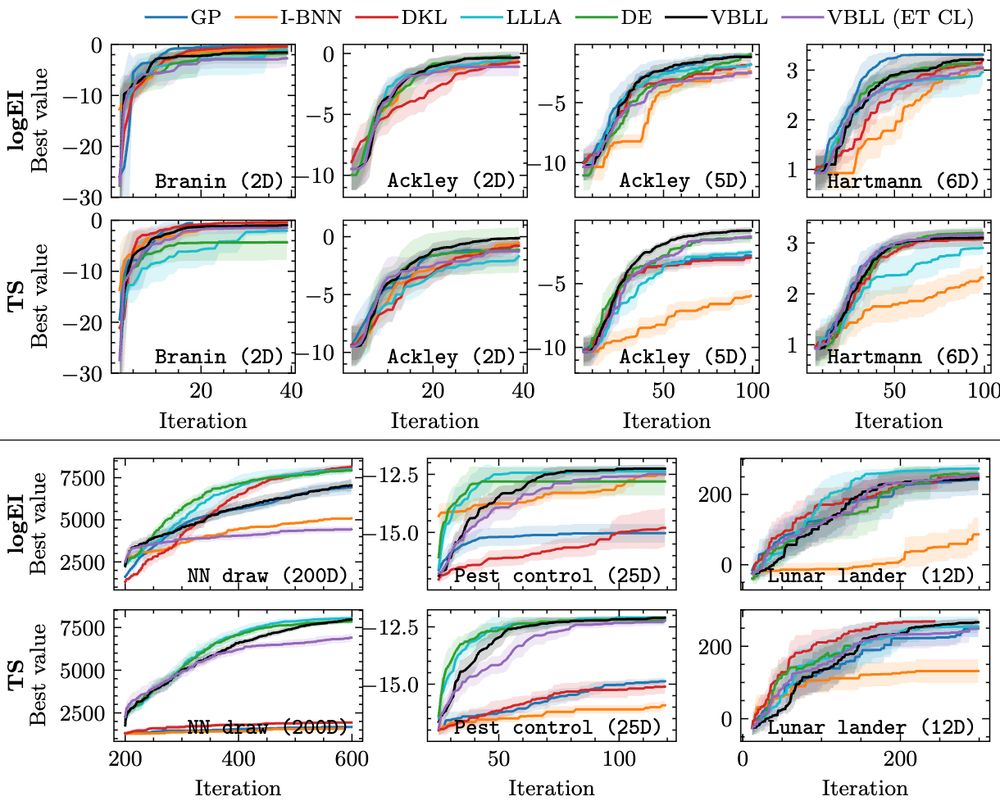
Our results show our approach of VBLLs + MLP features + our training approach yields SOTA or near-SOTA performance on a bunch of problems from classic 2D Ackley, all the way to much more challenging problems with discrete inputs and controller tuning.
December 14, 2024 at 8:59 PM
Our results show our approach of VBLLs + MLP features + our training approach yields SOTA or near-SOTA performance on a bunch of problems from classic 2D Ackley, all the way to much more challenging problems with discrete inputs and controller tuning.
To accelerate training, we combine model optimization with last-layer conditioning. This is a useful bridge between efficient Bayesian conditioning and NN optimization and massively accelerates training at (almost) no performance cost (see black vs purple or green curve in the figure).

December 14, 2024 at 8:59 PM
To accelerate training, we combine model optimization with last-layer conditioning. This is a useful bridge between efficient Bayesian conditioning and NN optimization and massively accelerates training at (almost) no performance cost (see black vs purple or green curve in the figure).
Our approach builds on variational Bayesian last layers (VBLLs, arxiv.org/abs/2404.11599). These can be applied with arbitrary NN architectures, and are highly scalable at the same cost as standard NN training. Your favorite model can painlessly do active learning!

Variational Bayesian Last Layers
We introduce a deterministic variational formulation for training Bayesian last layer neural networks. This yields a sampling-free, single-pass model and loss that effectively improves uncertainty est...
arxiv.org
December 14, 2024 at 8:59 PM
Our approach builds on variational Bayesian last layers (VBLLs, arxiv.org/abs/2404.11599). These can be applied with arbitrary NN architectures, and are highly scalable at the same cost as standard NN training. Your favorite model can painlessly do active learning!