




Olivier Grisel
@ogrisel.bsky.social
Software engineer at probabl, scikit-learn contributor.
Also at:
https://sigmoid.social/@ogrisel
https://github.com/ogrisel
Also at:
https://sigmoid.social/@ogrisel
https://github.com/ogrisel
Thanks for sharing. I would be very curious to see if LeJEPA can successfully pretrain good encoders for other input modalities with different kinds of spatial structures and signal smoothness assumptions (audio, time series, signal from robotic sensors, natural language...).
November 14, 2025 at 3:26 PM
Thanks for sharing. I would be very curious to see if LeJEPA can successfully pretrain good encoders for other input modalities with different kinds of spatial structures and signal smoothness assumptions (audio, time series, signal from robotic sensors, natural language...).
More info about free-threading here: py-free-threading.github.io
Python Free-Threading Guide
The free-threading guide is a centralized collection of documentation and trackers around compatibility with free-threaded CPython for the Python open source ecosystem
py-free-threading.github.io
September 2, 2025 at 4:51 PM
More info about free-threading here: py-free-threading.github.io
We set up some dedicated automated tests and discovered a bunch of thread-safety bugs, but they are now tracked by dedicated issues, and we have plans to fix them all, hopefully in time for 1.8.
September 2, 2025 at 4:51 PM
We set up some dedicated automated tests and discovered a bunch of thread-safety bugs, but they are now tracked by dedicated issues, and we have plans to fix them all, hopefully in time for 1.8.

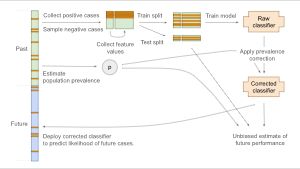
However, the Elkan 2001 post-hoc prevalence correction can be used for any (well-specified) probabilistic classifier, including gradient boosting classifiers, assuming the training set is a uniform sample of the population conditionally on the class.
August 19, 2025 at 11:58 AM
However, the Elkan 2001 post-hoc prevalence correction can be used for any (well-specified) probabilistic classifier, including gradient boosting classifiers, assuming the training set is a uniform sample of the population conditionally on the class.
Interestingly, for logistic regression, this is equivalent to shifting the intercept by the difference of the logits of the prevalence of the positive class in the population and in the training set distributions, respectively.
August 19, 2025 at 11:58 AM
Interestingly, for logistic regression, this is equivalent to shifting the intercept by the difference of the logits of the prevalence of the positive class in the population and in the training set distributions, respectively.
Equivalently, we can append a monotonic post-hoc transformation to a naively trained classifier to get a prevalence-corrected classifier as a result as show in Theorem 2 of cseweb.ucsd.edu/~elkan/resca...
cseweb.ucsd.edu
August 19, 2025 at 11:58 AM
Equivalently, we can append a monotonic post-hoc transformation to a naively trained classifier to get a prevalence-corrected classifier as a result as show in Theorem 2 of cseweb.ucsd.edu/~elkan/resca...
In this case, we can use weight-based training to correct the model's probabilistic predictions to stay well calibrated with respect to the target deployment setting.
August 19, 2025 at 11:58 AM
In this case, we can use weight-based training to correct the model's probabilistic predictions to stay well calibrated with respect to the target deployment setting.
This problem typically happens when the class of interest (positive class) is so rare (medical screening, predictive maintenance, fraud detection...) that collecting training features for the negative cases in the correct proportion would be too costly (or even illegal/unethical).
August 19, 2025 at 11:58 AM
This problem typically happens when the class of interest (positive class) is so rare (medical screening, predictive maintenance, fraud detection...) that collecting training features for the negative cases in the correct proportion would be too costly (or even illegal/unethical).
We then discussed another common related problem: how to deal with a prevalence shift between observed data and the deployment setting?
probabl-ai.github.io/calibration-...
probabl-ai.github.io/calibration-...
August 19, 2025 at 11:58 AM
We then discussed another common related problem: how to deal with a prevalence shift between observed data and the deployment setting?
probabl-ai.github.io/calibration-...
probabl-ai.github.io/calibration-...
If you can, consider defining a business specific cost function and use that to tune the decision threshold automatically for your deployment setting.
We covered that precise setting in an earlier workshop:
probabl-ai.github.io/calibration-...
We covered that precise setting in an earlier workshop:
probabl-ai.github.io/calibration-...
Cost-sensitive learning to optimize business metrics — Probabilistic calibration of cost-sensitive learning
probabl-ai.github.io
August 19, 2025 at 11:58 AM
If you can, consider defining a business specific cost function and use that to tune the decision threshold automatically for your deployment setting.
We covered that precise setting in an earlier workshop:
probabl-ai.github.io/calibration-...
We covered that precise setting in an earlier workshop:
probabl-ai.github.io/calibration-...
Instead, you should probably keep the well calibrated model and look at the influence of the decision threshold on your precision-recall trade-off. The default value of the cut-off is 0.5 in scikit-learn, but it's not necessarily meaningful to turn predicted probabilities into operational decisions.
August 19, 2025 at 11:58 AM
Instead, you should probably keep the well calibrated model and look at the influence of the decision threshold on your precision-recall trade-off. The default value of the cut-off is 0.5 in scikit-learn, but it's not necessarily meaningful to turn predicted probabilities into operational decisions.
Spoiler: rebalancing the training data is rarely the correct fix. You will break probabilistic calibration and can no longer relate the predicted class probabilities to your deployment setting.
August 19, 2025 at 11:58 AM
Spoiler: rebalancing the training data is rarely the correct fix. You will break probabilistic calibration and can no longer relate the predicted class probabilities to your deployment setting.
It's an interesting new deep learning architecture that can be somewhat successfully trained to solve challenging reasoning tasks where other methods completely fail.
July 30, 2025 at 4:30 PM
It's an interesting new deep learning architecture that can be somewhat successfully trained to solve challenging reasoning tasks where other methods completely fail.
The paper gives no evidence that it's possible to unsupervised pre-train HRM modules and then do transfer learning on other reasoning tasks.
July 30, 2025 at 4:20 PM
The paper gives no evidence that it's possible to unsupervised pre-train HRM modules and then do transfer learning on other reasoning tasks.