



Paul
@notpaulmartin.bsky.social
NLP PhD @ Cambridge Language Technology Lab
paulsbitsandbytes.com
paulsbitsandbytes.com
Reposted by Paul

🚀 By *learning* to compress the KV cache in Transformer LLMs, we can generate more tokens for the same compute budget.
This unlocks *inference-time hyper-scaling*
For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!
This unlocks *inference-time hyper-scaling*
For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!

June 6, 2025 at 12:33 PM
🚀 By *learning* to compress the KV cache in Transformer LLMs, we can generate more tokens for the same compute budget.
This unlocks *inference-time hyper-scaling*
For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!
This unlocks *inference-time hyper-scaling*
For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!
Reposted by Paul

We propose Neurosymbolic Diffusion Models! We find diffusion is especially compelling for neurosymbolic approaches, combining powerful multimodal understanding with symbolic reasoning 🚀
Read more 👇
Read more 👇
May 21, 2025 at 10:57 AM
We propose Neurosymbolic Diffusion Models! We find diffusion is especially compelling for neurosymbolic approaches, combining powerful multimodal understanding with symbolic reasoning 🚀
Read more 👇
Read more 👇
Reposted by Paul
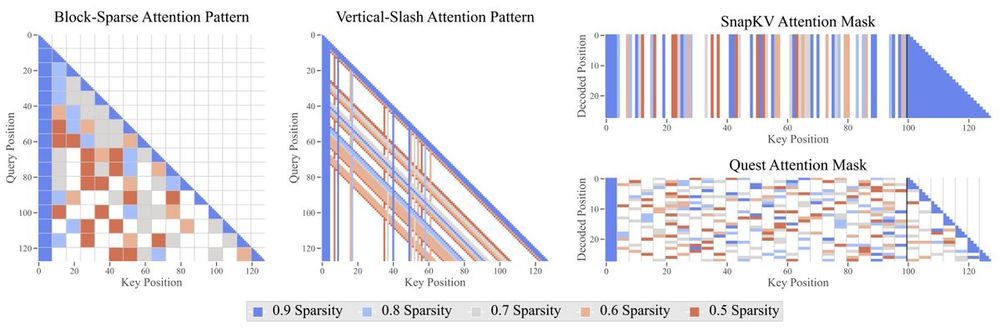
Sparse attention is one of the most promising strategies to unlock long-context processing and long-generation reasoning in LLMs.
We performed the most comprehensive study on training-free sparse attention to date.
Here is what we found:
We performed the most comprehensive study on training-free sparse attention to date.
Here is what we found:
April 25, 2025 at 3:39 PM
Sparse attention is one of the most promising strategies to unlock long-context processing and long-generation reasoning in LLMs.
We performed the most comprehensive study on training-free sparse attention to date.
Here is what we found:
We performed the most comprehensive study on training-free sparse attention to date.
Here is what we found:
Reposted by Paul

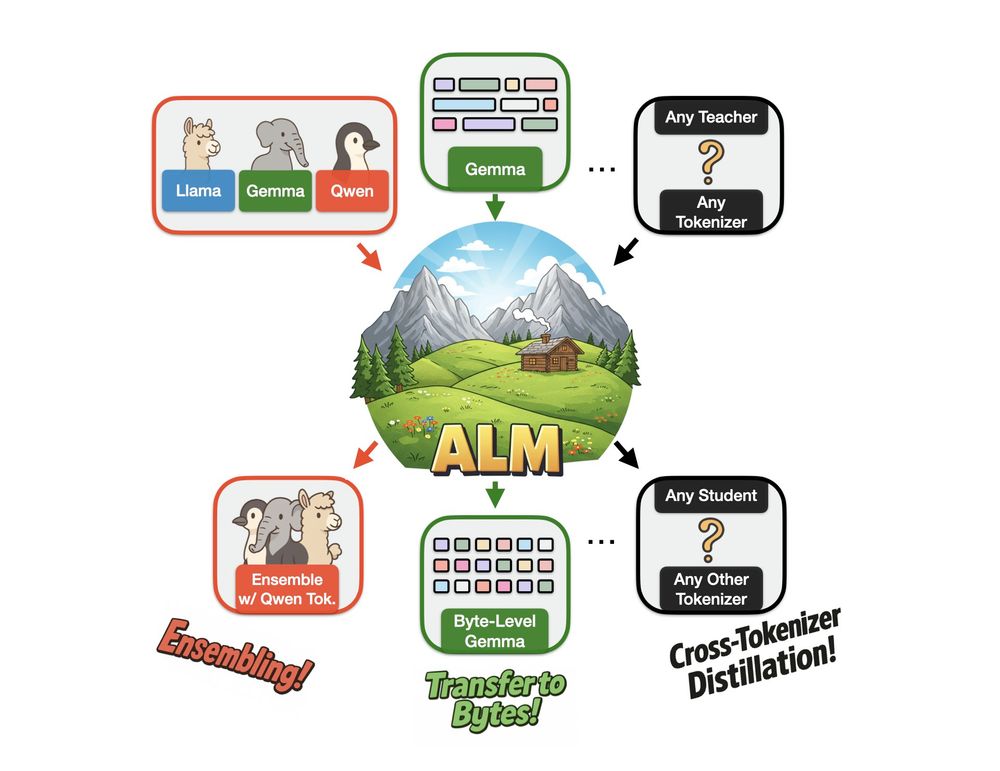
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
April 2, 2025 at 6:36 AM
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
Reposted by Paul

Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)

NeurIPS participation in Europe
We seek to understand if there is interest in being able to attend NeurIPS in Europe, i.e. without travelling to San Diego, US. In the following, assume that it is possible to present accepted papers ...
docs.google.com
March 30, 2025 at 6:04 PM
Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)