



Lex
@notesbylex.com
Senior MLE at @Canva. Full-stack developer.
Kaggle Notebook Master and collector of competition silver medals. https://www.kaggle.com/lextoumbourou
Talks about Software dev, ML, generative art, note-taking, dog photos. Mostly cross-posting from Mastodon.
Kaggle Notebook Master and collector of competition silver medals. https://www.kaggle.com/lextoumbourou
Talks about Software dev, ML, generative art, note-taking, dog photos. Mostly cross-posting from Mastodon.
This new image editing model from Black Forest Labs called **FLUX.1 Kontext** is really good. I ran some experiments on photos of Doggo, and couldn't believe how well it could maintain character consistent across multiple turns of editing.
https://notesbylex.com/absurdly-good-doggo-consistency-wit…
https://notesbylex.com/absurdly-good-doggo-consistency-wit…

June 1, 2025 at 11:25 PM
This new image editing model from Black Forest Labs called **FLUX.1 Kontext** is really good. I ran some experiments on photos of Doggo, and couldn't believe how well it could maintain character consistent across multiple turns of editing.
https://notesbylex.com/absurdly-good-doggo-consistency-wit…
https://notesbylex.com/absurdly-good-doggo-consistency-wit…
Learning to Reason without External Rewards (aka Self-confidence Is All You Need)
Turns out we can just use the LLM's internal sense of confidence as the reward signal to train a reasoning model, no reward model / ground-truth examples / self-play needed.
Amazing.
https://notesbylex.com/learning…
Turns out we can just use the LLM's internal sense of confidence as the reward signal to train a reasoning model, no reward model / ground-truth examples / self-play needed.
Amazing.
https://notesbylex.com/learning…
June 1, 2025 at 11:25 PM
Learning to Reason without External Rewards (aka Self-confidence Is All You Need)
Turns out we can just use the LLM's internal sense of confidence as the reward signal to train a reasoning model, no reward model / ground-truth examples / self-play needed.
Amazing.
https://notesbylex.com/learning…
Turns out we can just use the LLM's internal sense of confidence as the reward signal to train a reasoning model, no reward model / ground-truth examples / self-play needed.
Amazing.
https://notesbylex.com/learning…
"My new hobby: watching AI slowly drive Microsoft employees insane" https://old.reddit.com/r/ExperiencedDevs/comments/1krttqo/my_new_hobby_watching_ai_slowly_drive_microsoft/
May 22, 2025 at 6:43 AM
"My new hobby: watching AI slowly drive Microsoft employees insane" https://old.reddit.com/r/ExperiencedDevs/comments/1krttqo/my_new_hobby_watching_ai_slowly_drive_microsoft/
A cool approach to iteratively improving generated images, using o3 as an LLM-judge to generate targeted masks for improvements: https://simulate.trybezel.com/research/image_agent
May 21, 2025 at 10:34 PM
A cool approach to iteratively improving generated images, using o3 as an LLM-judge to generate targeted masks for improvements: https://simulate.trybezel.com/research/image_agent
Reposted by Lex

ARR deadline is coming up! If you're wondering how to make a beautiful full-width teaser figure on your first page, above the abstract, in LaTeX, check out this gist I made showing how I do it!
gist.github.com/michaelsaxon...
gist.github.com/michaelsaxon...

Teaser figures in ACL template papers
Teaser figures in ACL template papers. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
February 12, 2025 at 9:35 PM
ARR deadline is coming up! If you're wondering how to make a beautiful full-width teaser figure on your first page, above the abstract, in LaTeX, check out this gist I made showing how I do it!
gist.github.com/michaelsaxon...
gist.github.com/michaelsaxon...
Reposted by Lex

🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!

February 12, 2025 at 5:33 PM
🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
"As a former tech lead at Meta for 6 years... I got 'meets all' or 'exceeds' every single half except the one in which I took parental leave."
www.reddit.com/r/business/c...
www.reddit.com/r/business/c...
February 12, 2025 at 7:58 PM
"As a former tech lead at Meta for 6 years... I got 'meets all' or 'exceeds' every single half except the one in which I took parental leave."
www.reddit.com/r/business/c...
www.reddit.com/r/business/c...
A hilariously simple repro of OpenAI's test-time scaling paradigm called "Budget Scaling": end the thinking when your token budget is met, or append "Wait" to the model's generation to keep thinking, allowing the model to fix incorrect reasoning steps.
arxiv.org/abs/2501.19393
arxiv.org/abs/2501.19393

February 3, 2025 at 6:14 AM
A hilariously simple repro of OpenAI's test-time scaling paradigm called "Budget Scaling": end the thinking when your token budget is met, or append "Wait" to the model's generation to keep thinking, allowing the model to fix incorrect reasoning steps.
arxiv.org/abs/2501.19393
arxiv.org/abs/2501.19393
A method for evaluating data for preference optimisation.
Rejecting Instruction Preferences (RIP) can filter prompts from existing training sets or make high-quality synthetic datasets. They see large performance gains across various benchmarks compared to unfiltered data.
arxiv.org/abs/2501.18578
Rejecting Instruction Preferences (RIP) can filter prompts from existing training sets or make high-quality synthetic datasets. They see large performance gains across various benchmarks compared to unfiltered data.
arxiv.org/abs/2501.18578
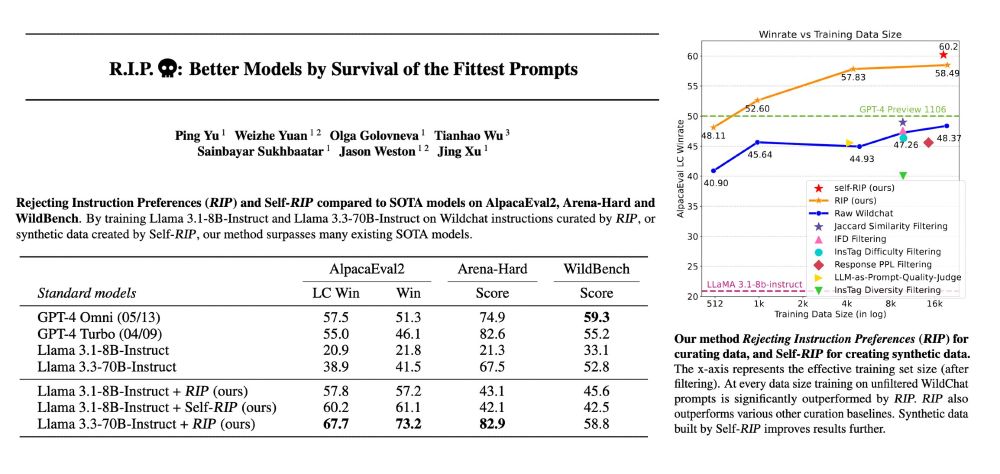
January 31, 2025 at 5:22 AM
A method for evaluating data for preference optimisation.
Rejecting Instruction Preferences (RIP) can filter prompts from existing training sets or make high-quality synthetic datasets. They see large performance gains across various benchmarks compared to unfiltered data.
arxiv.org/abs/2501.18578
Rejecting Instruction Preferences (RIP) can filter prompts from existing training sets or make high-quality synthetic datasets. They see large performance gains across various benchmarks compared to unfiltered data.
arxiv.org/abs/2501.18578
A reproduction of Deepseek R1-Zero.
"The recipe:
We follow DeepSeek R1-Zero alg -- Given a base LM, prompts and ground-truth reward, we run RL.
We apply it to CountDown: a game where players combine numbers with basic arithmetic to reach a target number."
github.com/Jiayi-Pan/Ti...
"The recipe:
We follow DeepSeek R1-Zero alg -- Given a base LM, prompts and ground-truth reward, we run RL.
We apply it to CountDown: a game where players combine numbers with basic arithmetic to reach a target number."
github.com/Jiayi-Pan/Ti...
GitHub - Jiayi-Pan/TinyZero: Clean, accessible reproduction of DeepSeek R1-Zero
Clean, accessible reproduction of DeepSeek R1-Zero - Jiayi-Pan/TinyZero
github.com
January 30, 2025 at 8:05 PM
A reproduction of Deepseek R1-Zero.
"The recipe:
We follow DeepSeek R1-Zero alg -- Given a base LM, prompts and ground-truth reward, we run RL.
We apply it to CountDown: a game where players combine numbers with basic arithmetic to reach a target number."
github.com/Jiayi-Pan/Ti...
"The recipe:
We follow DeepSeek R1-Zero alg -- Given a base LM, prompts and ground-truth reward, we run RL.
We apply it to CountDown: a game where players combine numbers with basic arithmetic to reach a target number."
github.com/Jiayi-Pan/Ti...
Reasoning models can be useful for generating high-quality few-shot examples:
1. generate 10-20 examples from criteria in different styles with r1/o1/CoT, etc
2. have a model rate for each example based on quality + adherence.
3. filter/edit top examples by hand
Repeat for each category of output.
1. generate 10-20 examples from criteria in different styles with r1/o1/CoT, etc
2. have a model rate for each example based on quality + adherence.
3. filter/edit top examples by hand
Repeat for each category of output.
January 29, 2025 at 4:32 AM
Reasoning models can be useful for generating high-quality few-shot examples:
1. generate 10-20 examples from criteria in different styles with r1/o1/CoT, etc
2. have a model rate for each example based on quality + adherence.
3. filter/edit top examples by hand
Repeat for each category of output.
1. generate 10-20 examples from criteria in different styles with r1/o1/CoT, etc
2. have a model rate for each example based on quality + adherence.
3. filter/edit top examples by hand
Repeat for each category of output.

Reposted by Lex

The Illustrated DeepSeek-R1
Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide and the main intuitions to understand the model and the process that created it.
newsletter.languagemodels.co/p/the-illust...
Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide and the main intuitions to understand the model and the process that created it.
newsletter.languagemodels.co/p/the-illust...
January 27, 2025 at 8:22 PM
The Illustrated DeepSeek-R1
Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide and the main intuitions to understand the model and the process that created it.
newsletter.languagemodels.co/p/the-illust...
Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide and the main intuitions to understand the model and the process that created it.
newsletter.languagemodels.co/p/the-illust...
The DeepSeek V3 model file in ~450 lines of code in MLX LM.
github.com/ml-explore/m...
via awnihannun on Twitter.
github.com/ml-explore/m...
via awnihannun on Twitter.
mlx-examples/llms/mlx_lm/models/deepseek_v3.py at main · ml-explore/mlx-examples
Examples in the MLX framework. Contribute to ml-explore/mlx-examples development by creating an account on GitHub.
github.com
January 28, 2025 at 5:48 AM
The DeepSeek V3 model file in ~450 lines of code in MLX LM.
github.com/ml-explore/m...
via awnihannun on Twitter.
github.com/ml-explore/m...
via awnihannun on Twitter.
So DeepSeek found a way to train a gpt4 quality model for *only* 6M worth of Nvidia hardware, and the market thinks this is bad for Nvidia?
January 27, 2025 at 7:53 PM
So DeepSeek found a way to train a gpt4 quality model for *only* 6M worth of Nvidia hardware, and the market thinks this is bad for Nvidia?
Imo the Google AI summaries are really helpful. The usefulness of an LLM increases substantially when it can reference its sources
January 24, 2025 at 12:07 AM
Imo the Google AI summaries are really helpful. The usefulness of an LLM increases substantially when it can reference its sources
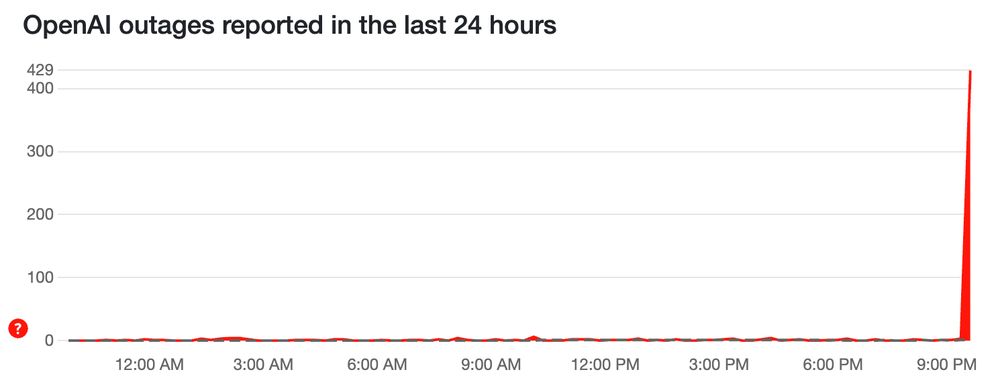
ChatGPT seems to be down.
January 23, 2025 at 11:54 AM
ChatGPT seems to be down.
"The Stargate Project is a new company which intends to invest $500 billion over the next four years building new AI infrastructure for OpenAI in the United States"
$500 billion! For comparison, the 1960s Apollo project, when adjusted for inflation, cost around $250B.
openai.com/index/announ...
$500 billion! For comparison, the 1960s Apollo project, when adjusted for inflation, cost around $250B.
openai.com/index/announ...

Announcing The Stargate Project
Announcing The Stargate Project
openai.com
January 22, 2025 at 1:30 AM
"The Stargate Project is a new company which intends to invest $500 billion over the next four years building new AI infrastructure for OpenAI in the United States"
$500 billion! For comparison, the 1960s Apollo project, when adjusted for inflation, cost around $250B.
openai.com/index/announ...
$500 billion! For comparison, the 1960s Apollo project, when adjusted for inflation, cost around $250B.
openai.com/index/announ...
"Verified DeepSeek performance on ARC-AGI's Public Eval (400 tasks) + Semi-Private (100 tasks)
DeepSeek V3:
* Semi-Private: 7.3%
* Public Eval: 14%
DeepSeek Reasoner:
* Semi-Private: 15.8%
* Public Eval: 20.5%
Performance is on par, albeit slightly lower, than o1-preview"
x.com/arcprize/sta...
DeepSeek V3:
* Semi-Private: 7.3%
* Public Eval: 14%
DeepSeek Reasoner:
* Semi-Private: 15.8%
* Public Eval: 20.5%
Performance is on par, albeit slightly lower, than o1-preview"
x.com/arcprize/sta...
x.com
x.com
January 21, 2025 at 9:28 PM
"Verified DeepSeek performance on ARC-AGI's Public Eval (400 tasks) + Semi-Private (100 tasks)
DeepSeek V3:
* Semi-Private: 7.3%
* Public Eval: 14%
DeepSeek Reasoner:
* Semi-Private: 15.8%
* Public Eval: 20.5%
Performance is on par, albeit slightly lower, than o1-preview"
x.com/arcprize/sta...
DeepSeek V3:
* Semi-Private: 7.3%
* Public Eval: 14%
DeepSeek Reasoner:
* Semi-Private: 15.8%
* Public Eval: 20.5%
Performance is on par, albeit slightly lower, than o1-preview"
x.com/arcprize/sta...
This is gold. DeepSeek-R1's thought process for "how many 'r's in strawberry."
"So positions 3, 8, and 9 are Rs? No, that can't be right because the word is spelled as S-T-R-A-W-B-E-R-R-Y, which has two Rs at the end...
Wait, maybe I'm overcomplicating it...."
gist.github.com/IAmStoxe/1a1...
"So positions 3, 8, and 9 are Rs? No, that can't be right because the word is spelled as S-T-R-A-W-B-E-R-R-Y, which has two Rs at the end...
Wait, maybe I'm overcomplicating it...."
gist.github.com/IAmStoxe/1a1...

how_many_rs.md
GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
January 21, 2025 at 4:05 AM
This is gold. DeepSeek-R1's thought process for "how many 'r's in strawberry."
"So positions 3, 8, and 9 are Rs? No, that can't be right because the word is spelled as S-T-R-A-W-B-E-R-R-Y, which has two Rs at the end...
Wait, maybe I'm overcomplicating it...."
gist.github.com/IAmStoxe/1a1...
"So positions 3, 8, and 9 are Rs? No, that can't be right because the word is spelled as S-T-R-A-W-B-E-R-R-Y, which has two Rs at the end...
Wait, maybe I'm overcomplicating it...."
gist.github.com/IAmStoxe/1a1...
I finally got around to updating my Obsidian plugin: obsidian-title-as-link-text.
1. Now support Wikilinks with a display name: `[[my-page|A Cool Page]]`
2. Also added support for aliases.
See the release notes: github.com/lextoumbouro...
1. Now support Wikilinks with a display name: `[[my-page|A Cool Page]]`
2. Also added support for aliases.
See the release notes: github.com/lextoumbouro...
January 18, 2025 at 5:50 AM
I finally got around to updating my Obsidian plugin: obsidian-title-as-link-text.
1. Now support Wikilinks with a display name: `[[my-page|A Cool Page]]`
2. Also added support for aliases.
See the release notes: github.com/lextoumbouro...
1. Now support Wikilinks with a display name: `[[my-page|A Cool Page]]`
2. Also added support for aliases.
See the release notes: github.com/lextoumbouro...
Reposted by Lex

You can finetune Phi-4 for free on Colab now!
Unsloth finetunes LLMs 2x faster, with 70% less VRAM, 12x longer context - with no accuracy loss
Documentation: docs.unsloth.ai
We also fixed 4 bugs in Phi-4: unsloth.ai/blog/phi4
Phi-4 Colab: colab.research.google.com/github/unslo...
Unsloth finetunes LLMs 2x faster, with 70% less VRAM, 12x longer context - with no accuracy loss
Documentation: docs.unsloth.ai
We also fixed 4 bugs in Phi-4: unsloth.ai/blog/phi4
Phi-4 Colab: colab.research.google.com/github/unslo...

Finetune Phi-4 with Unsloth
Fine-tune Microsoft's new Phi-4 model with Unsloth!
We've also found & fixed 4 bugs in the model.
unsloth.ai
January 10, 2025 at 7:55 PM
You can finetune Phi-4 for free on Colab now!
Unsloth finetunes LLMs 2x faster, with 70% less VRAM, 12x longer context - with no accuracy loss
Documentation: docs.unsloth.ai
We also fixed 4 bugs in Phi-4: unsloth.ai/blog/phi4
Phi-4 Colab: colab.research.google.com/github/unslo...
Unsloth finetunes LLMs 2x faster, with 70% less VRAM, 12x longer context - with no accuracy loss
Documentation: docs.unsloth.ai
We also fixed 4 bugs in Phi-4: unsloth.ai/blog/phi4
Phi-4 Colab: colab.research.google.com/github/unslo...
