



Nicolay Gerold
@nicolaygerold.com
Daytime: building ai systems & platforms @ Aisbach
Nighttime: hacking on generative ai
Host of How AI Is Built
Nighttime: hacking on generative ai
Host of How AI Is Built
OpenCode is really stepping it up. I love the sidebar stuff. Really plays well with nvim.
May 16, 2025 at 8:16 AM
OpenCode is really stepping it up. I love the sidebar stuff. Really plays well with nvim.
EU mobilizes 200 billion Euros for AI.
Unless we have a massive political change that money will just go to waste.
For innovation to happen, we don't need money first, but deregulation.
We cannot work on breakthrough technologies, when we are at constant fear of being sued.
Unless we have a massive political change that money will just go to waste.
For innovation to happen, we don't need money first, but deregulation.
We cannot work on breakthrough technologies, when we are at constant fear of being sued.

February 13, 2025 at 9:15 AM
EU mobilizes 200 billion Euros for AI.
Unless we have a massive political change that money will just go to waste.
For innovation to happen, we don't need money first, but deregulation.
We cannot work on breakthrough technologies, when we are at constant fear of being sued.
Unless we have a massive political change that money will just go to waste.
For innovation to happen, we don't need money first, but deregulation.
We cannot work on breakthrough technologies, when we are at constant fear of being sued.
RAG is dead. Long live RAG.
LLMs suck at long context.
This paper shows what I have seen in most deployments.
With longer contexts, performance degrades.
LLMs suck at long context.
This paper shows what I have seen in most deployments.
With longer contexts, performance degrades.

February 13, 2025 at 6:11 AM
RAG is dead. Long live RAG.
LLMs suck at long context.
This paper shows what I have seen in most deployments.
With longer contexts, performance degrades.
LLMs suck at long context.
This paper shows what I have seen in most deployments.
With longer contexts, performance degrades.
Dropping some new episodes on @howaiisbuilt.fm . Links below.

January 31, 2025 at 12:44 PM
Dropping some new episodes on @howaiisbuilt.fm . Links below.
New podcast with Alex Garcia on search in sqlite

January 25, 2025 at 5:29 AM
New podcast with Alex Garcia on search in sqlite
That's surprisingly on brand.

January 18, 2025 at 7:33 AM
That's surprisingly on brand.
Developers treat search as a blackbox.
Throw everything in a vector database and hope something good comes out.
Throw all ranking signals into one big ML model and hope it makes something good out of it.
You don’t want to create this witch’s cauldron.
New episode on @howaiisbuilt.fm
Throw everything in a vector database and hope something good comes out.
Throw all ranking signals into one big ML model and hope it makes something good out of it.
You don’t want to create this witch’s cauldron.
New episode on @howaiisbuilt.fm

January 9, 2025 at 1:58 PM
Developers treat search as a blackbox.
Throw everything in a vector database and hope something good comes out.
Throw all ranking signals into one big ML model and hope it makes something good out of it.
You don’t want to create this witch’s cauldron.
New episode on @howaiisbuilt.fm
Throw everything in a vector database and hope something good comes out.
Throw all ranking signals into one big ML model and hope it makes something good out of it.
You don’t want to create this witch’s cauldron.
New episode on @howaiisbuilt.fm
The biggest lie in RAG is that semantic search is simple.
The reality is that it's easy to build, it's easy to get up and running, but it's really hard to get right.
And if you don't have a good setup, it's near impossible to debug.
One of the reasons it's really hard is chunking.
The reality is that it's easy to build, it's easy to get up and running, but it's really hard to get right.
And if you don't have a good setup, it's near impossible to debug.
One of the reasons it's really hard is chunking.

January 3, 2025 at 11:28 AM
The biggest lie in RAG is that semantic search is simple.
The reality is that it's easy to build, it's easy to get up and running, but it's really hard to get right.
And if you don't have a good setup, it's near impossible to debug.
One of the reasons it's really hard is chunking.
The reality is that it's easy to build, it's easy to get up and running, but it's really hard to get right.
And if you don't have a good setup, it's near impossible to debug.
One of the reasons it's really hard is chunking.
@merve.bsky.social
Can you show the Amazon people how to use a VLM to do the handwriting recognition.
That's atrocious.
Can you show the Amazon people how to use a VLM to do the handwriting recognition.
That's atrocious.

December 23, 2024 at 6:59 PM
@merve.bsky.social
Can you show the Amazon people how to use a VLM to do the handwriting recognition.
That's atrocious.
Can you show the Amazon people how to use a VLM to do the handwriting recognition.
That's atrocious.
Getting ads for the remarkable pro while watching a review on the new Kindle Scribe. Someone got their targeting down.

December 23, 2024 at 6:57 PM
Getting ads for the remarkable pro while watching a review on the new Kindle Scribe. Someone got their targeting down.
You usually have supervisors and workers. And it is super easy to spin them up. And the workers run in "lightweight processes", which when they crash they can be spun up again super fast and since they are isolated, they don't bring down the entire system.

December 21, 2024 at 11:40 AM
You usually have supervisors and workers. And it is super easy to spin them up. And the workers run in "lightweight processes", which when they crash they can be spun up again super fast and since they are isolated, they don't bring down the entire system.
They use a large model (e.g. gpt-4o) to generate training data for a smaller one (gpt-4o-mini).
This lets you build fast, cheap models that do one thing well or that are more capable because they have (nearly) identical capabilities distilled into a smaller number of parameters.
This lets you build fast, cheap models that do one thing well or that are more capable because they have (nearly) identical capabilities distilled into a smaller number of parameters.

December 19, 2024 at 12:43 PM
They use a large model (e.g. gpt-4o) to generate training data for a smaller one (gpt-4o-mini).
This lets you build fast, cheap models that do one thing well or that are more capable because they have (nearly) identical capabilities distilled into a smaller number of parameters.
This lets you build fast, cheap models that do one thing well or that are more capable because they have (nearly) identical capabilities distilled into a smaller number of parameters.
Didn't find the on demand pricing for it. Probably around 500/h if it becomes available for it :D

December 17, 2024 at 8:38 AM
Didn't find the on demand pricing for it. Probably around 500/h if it becomes available for it :D

December 17, 2024 at 5:33 AM
If you are lost in all the fuzz around the Byte Latent Transformer by Meta, read on.
Meta has created BLT, a new AI model that works with raw bytes instead of tokens.
Current AI models split text into tokens (fixed chunks of letters) before processing it.
>>
Meta has created BLT, a new AI model that works with raw bytes instead of tokens.
Current AI models split text into tokens (fixed chunks of letters) before processing it.
>>

December 16, 2024 at 3:18 PM
If you are lost in all the fuzz around the Byte Latent Transformer by Meta, read on.
Meta has created BLT, a new AI model that works with raw bytes instead of tokens.
Current AI models split text into tokens (fixed chunks of letters) before processing it.
>>
Meta has created BLT, a new AI model that works with raw bytes instead of tokens.
Current AI models split text into tokens (fixed chunks of letters) before processing it.
>>
Claude is surprisingly good at workout programming.

December 16, 2024 at 5:57 AM
Claude is surprisingly good at workout programming.

"Instead of being a one-way pipeline, agentic RAG allows you to check, 'Am I actually answering the user's question?'"
Different questions need different approaches.
➡️ 𝗤𝘂𝗲𝗿𝘆-𝗕𝗮𝘀𝗲𝗱 𝗙𝗹𝗲𝘅𝗶𝗯𝗶𝗹𝗶𝘁𝘆:
- Structured data? Use SQL
- Context-rich query? Use vector search
- Date-specific? Apply filters first
Different questions need different approaches.
➡️ 𝗤𝘂𝗲𝗿𝘆-𝗕𝗮𝘀𝗲𝗱 𝗙𝗹𝗲𝘅𝗶𝗯𝗶𝗹𝗶𝘁𝘆:
- Structured data? Use SQL
- Context-rich query? Use vector search
- Date-specific? Apply filters first

December 14, 2024 at 2:07 PM
"Instead of being a one-way pipeline, agentic RAG allows you to check, 'Am I actually answering the user's question?'"
Different questions need different approaches.
➡️ 𝗤𝘂𝗲𝗿𝘆-𝗕𝗮𝘀𝗲𝗱 𝗙𝗹𝗲𝘅𝗶𝗯𝗶𝗹𝗶𝘁𝘆:
- Structured data? Use SQL
- Context-rich query? Use vector search
- Date-specific? Apply filters first
Different questions need different approaches.
➡️ 𝗤𝘂𝗲𝗿𝘆-𝗕𝗮𝘀𝗲𝗱 𝗙𝗹𝗲𝘅𝗶𝗯𝗶𝗹𝗶𝘁𝘆:
- Structured data? Use SQL
- Context-rich query? Use vector search
- Date-specific? Apply filters first
Inequality joins in polars is massive.

December 14, 2024 at 6:56 AM
Inequality joins in polars is massive.
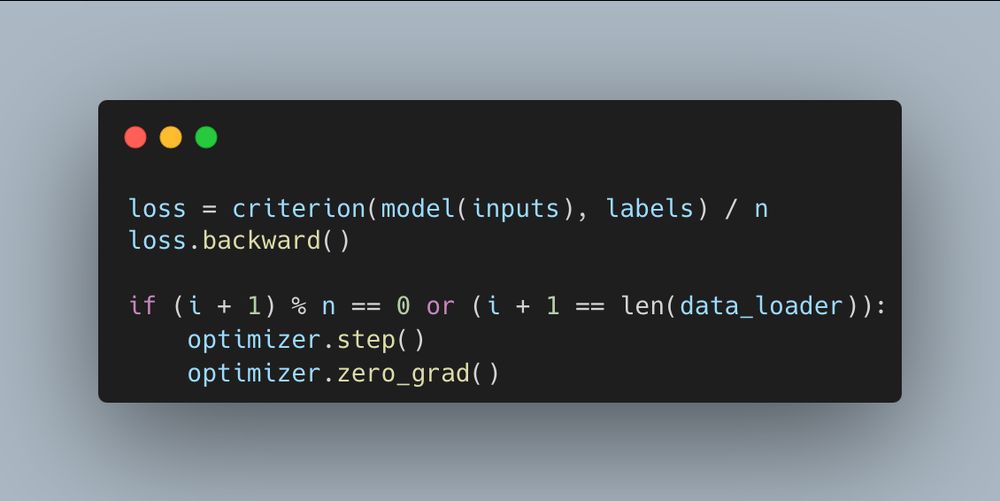
Has been a while since, I have done gradient accumulation.
I always tend to forget the last step (the check for hitting the length of the dataset) on the first implementation.
I always tend to forget the last step (the check for hitting the length of the dataset) on the first implementation.
December 11, 2024 at 5:26 AM
Has been a while since, I have done gradient accumulation.
I always tend to forget the last step (the check for hitting the length of the dataset) on the first implementation.
I always tend to forget the last step (the check for hitting the length of the dataset) on the first implementation.
Coding a project > reading articles.
Coding a project forces you to apply concepts directly. It’s a richer learning experience than just reading technical articles.
You discover gaps, solve real problems, and solidify your understanding.
Coding a project forces you to apply concepts directly. It’s a richer learning experience than just reading technical articles.
You discover gaps, solve real problems, and solidify your understanding.

December 10, 2024 at 7:24 PM
Coding a project > reading articles.
Coding a project forces you to apply concepts directly. It’s a richer learning experience than just reading technical articles.
You discover gaps, solve real problems, and solidify your understanding.
Coding a project forces you to apply concepts directly. It’s a richer learning experience than just reading technical articles.
You discover gaps, solve real problems, and solidify your understanding.
15Mio Ai Builders on Huggingface, we are still early.

December 10, 2024 at 2:24 PM
15Mio Ai Builders on Huggingface, we are still early.
Data Drift for Dummies.
Data drift happens when the real world changes but your model doesn't.
- Input drift: The data coming in changes (like cameras getting better resolution)
- Label drift: What you're predicting changes (like what counts as "spam" evolving)
>>
Data drift happens when the real world changes but your model doesn't.
- Input drift: The data coming in changes (like cameras getting better resolution)
- Label drift: What you're predicting changes (like what counts as "spam" evolving)
>>

December 10, 2024 at 2:13 PM
Data Drift for Dummies.
Data drift happens when the real world changes but your model doesn't.
- Input drift: The data coming in changes (like cameras getting better resolution)
- Label drift: What you're predicting changes (like what counts as "spam" evolving)
>>
Data drift happens when the real world changes but your model doesn't.
- Input drift: The data coming in changes (like cameras getting better resolution)
- Label drift: What you're predicting changes (like what counts as "spam" evolving)
>>