


Nicolas Yax
@nicolasyax.bsky.social
PhD student working on the cognition of LLMs | HRL team - ENS Ulm | FLOWERS - Inria Bordeaux
Curious about LLM interpretability and understanding ? We borrowed concepts from genetics to map language models, predict their capabilities, and even uncovered surprising insights about their training !
Come see my poster at #ICLR2025 3pm Hall 2B #505 !
Come see my poster at #ICLR2025 3pm Hall 2B #505 !

April 26, 2025 at 2:03 AM
Curious about LLM interpretability and understanding ? We borrowed concepts from genetics to map language models, predict their capabilities, and even uncovered surprising insights about their training !
Come see my poster at #ICLR2025 3pm Hall 2B #505 !
Come see my poster at #ICLR2025 3pm Hall 2B #505 !
By using code related contexts we can obtain a fairly different map. For example we notice that Qwen and GPT-3.5 have a very different way of coding compared to the other models which was not visible on the reasoning map. 7/10

April 24, 2025 at 1:15 PM
By using code related contexts we can obtain a fairly different map. For example we notice that Qwen and GPT-3.5 have a very different way of coding compared to the other models which was not visible on the reasoning map. 7/10
The contexts choice is important as it reflects different capabilities of LLMs. Here on a general reasoning type of context we can plot a map of models using UMAP. The larger the edge, the closer models are from each other. Models on the same cluster are even closer ! 6/10

April 24, 2025 at 1:15 PM
The contexts choice is important as it reflects different capabilities of LLMs. Here on a general reasoning type of context we can plot a map of models using UMAP. The larger the edge, the closer models are from each other. Models on the same cluster are even closer ! 6/10
It can also measure quantization efficiency by observing the behavioral distance between LLM and quantized versions. In the Qwen 1.5 release, GPTQ seems to perform best. This new concept of metric could provide additional insights to quantization efficiency. 5/10

April 24, 2025 at 1:15 PM
It can also measure quantization efficiency by observing the behavioral distance between LLM and quantized versions. In the Qwen 1.5 release, GPTQ seems to perform best. This new concept of metric could provide additional insights to quantization efficiency. 5/10
Aside from plotting trees, PhyloLM similarity matrix is very versatile. For example, running a logistic regression on the distance matrix makes it possible to predict performance of new models even from unseen families with good accuracy. Here is what we got on ARC. 4/10

April 24, 2025 at 1:15 PM
Aside from plotting trees, PhyloLM similarity matrix is very versatile. For example, running a logistic regression on the distance matrix makes it possible to predict performance of new models even from unseen families with good accuracy. Here is what we got on ARC. 4/10
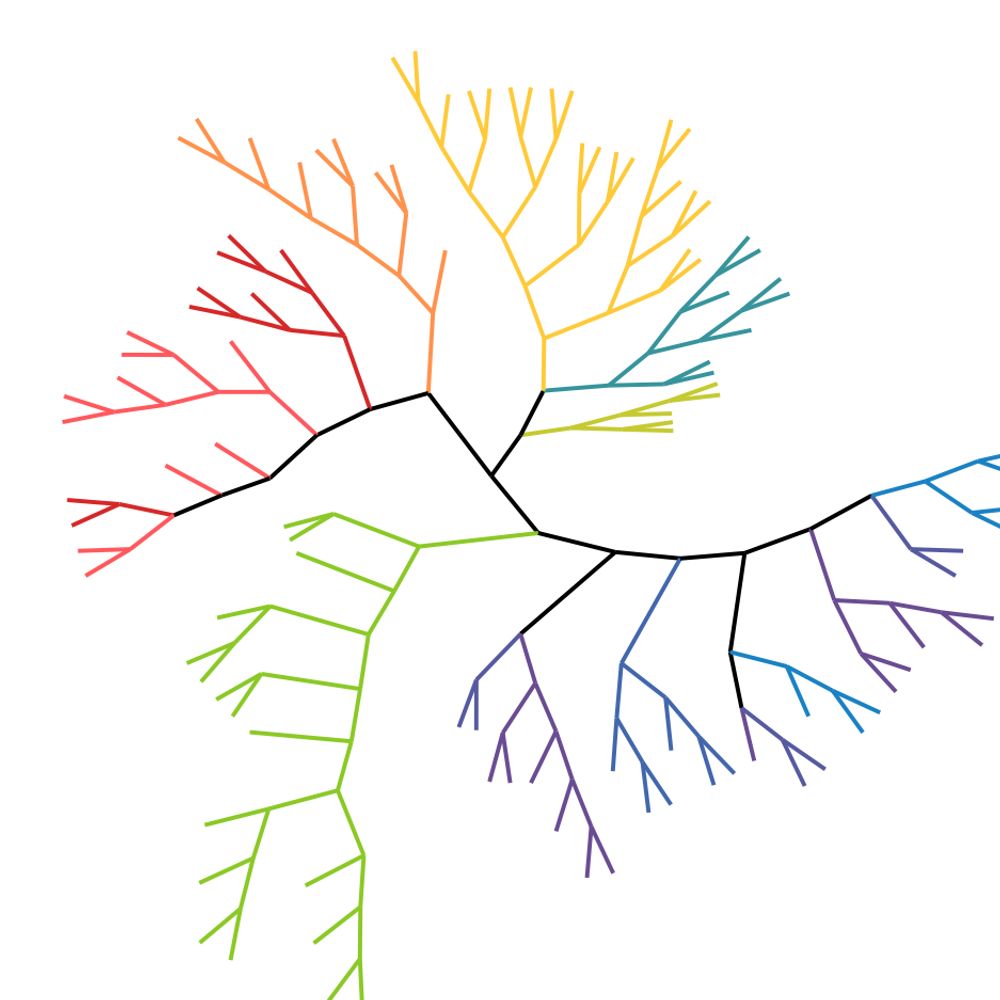
Not taking into account these requirements can still produce efficient distance vizualisation trees. However it is important to remember they do not represent evolutionary trees. Feel free to zoom in to see model names. 3/10

April 24, 2025 at 1:15 PM
Not taking into account these requirements can still produce efficient distance vizualisation trees. However it is important to remember they do not represent evolutionary trees. Feel free to zoom in to see model names. 3/10
Phylogenetic algorithms often require common ancestors to not appear in the objects studied but are clearly able to retrieve the evolution of the family. Here is an example in the richness of open-access model : @teknium.bsky.social @maximelabonne.bsky.social @mistralai.bsky.social 2/10

April 24, 2025 at 1:15 PM
Phylogenetic algorithms often require common ancestors to not appear in the objects studied but are clearly able to retrieve the evolution of the family. Here is an example in the richness of open-access model : @teknium.bsky.social @maximelabonne.bsky.social @mistralai.bsky.social 2/10
We build a distance matrix from comparing outputs of LLMs to a hundred of different contexts and build maps and trees from this distance matrix. Because PhyloLM only requires sampling very few tokens after a very short contexts the algorithm is particularly cheap to run. 1/10

April 24, 2025 at 1:15 PM
We build a distance matrix from comparing outputs of LLMs to a hundred of different contexts and build maps and trees from this distance matrix. Because PhyloLM only requires sampling very few tokens after a very short contexts the algorithm is particularly cheap to run. 1/10
🔥Our paper PhyloLM got accepted at ICLR 2025 !🔥
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️

April 24, 2025 at 1:15 PM
🔥Our paper PhyloLM got accepted at ICLR 2025 !🔥
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
On the other hand, if the score is high, both QA and Q are possible namely the model has seen the question but maybe not the answer during training. LogProber is not able to find which scenario happened but the item is suspicious. 11/15

November 15, 2024 at 1:48 PM
On the other hand, if the score is high, both QA and Q are possible namely the model has seen the question but maybe not the answer during training. LogProber is not able to find which scenario happened but the item is suspicious. 11/15
When testing a LLM on an item only one of these scenarios is possible. This means that if a model pretrained with a full language modelling method returns a low contamination score with LogProber on a given item, then the item is safe as only the STD scenario is possible. 10/15

November 15, 2024 at 1:48 PM
When testing a LLM on an item only one of these scenarios is possible. This means that if a model pretrained with a full language modelling method returns a low contamination score with LogProber on a given item, then the item is safe as only the STD scenario is possible. 10/15
Most LLMs are pretrained in a full language modelling manner meaning they fit on all tokens (both question and answer tokens) meaning A type of training is not a likely scenario. 9/15

November 15, 2024 at 1:48 PM
Most LLMs are pretrained in a full language modelling manner meaning they fit on all tokens (both question and answer tokens) meaning A type of training is not a likely scenario. 9/15
Results indicate that LogProber is able to accurately predict contamination in QA and STD scenarios, Q leading to false positives and A, to false negatives. In practice some of these scenarios are not possible depending on how the LLM is trained. 8/15
November 15, 2024 at 1:48 PM
Results indicate that LogProber is able to accurately predict contamination in QA and STD scenarios, Q leading to false positives and A, to false negatives. In practice some of these scenarios are not possible depending on how the LLM is trained. 8/15
QA is when both appear, A when both are present but the model only fits on the tokens of the answer (usually happens in some finetuning methods) and STD when neither the question nor the answer appear in the training data. 7/15

November 15, 2024 at 1:48 PM
QA is when both appear, A when both are present but the model only fits on the tokens of the answer (usually happens in some finetuning methods) and STD when neither the question nor the answer appear in the training data. 7/15
Then we provide experimental evidence by finetuning LLama ourselves and testing different scenarios to train and contaminate the models. Among these 4 scenarios, Q corresponds to pretraining on a text corpus that features the question but not the answer to this question. 6/15
November 15, 2024 at 1:48 PM
Then we provide experimental evidence by finetuning LLama ourselves and testing different scenarios to train and contaminate the models. Among these 4 scenarios, Q corresponds to pretraining on a text corpus that features the question but not the answer to this question. 6/15
We first provide observational evidence of LogProber’s ability to measure contamination. We used very classical psychology questions (Cognitive Reflection Test) and reframed versions and show that LogProber is able to easily differentiate the two groups. 5/15

November 15, 2024 at 1:48 PM
We first provide observational evidence of LogProber’s ability to measure contamination. We used very classical psychology questions (Cognitive Reflection Test) and reframed versions and show that LogProber is able to easily differentiate the two groups. 5/15
By plotting the cumulative log-probability graph of items we show that a flat graph means the model is likely contaminated on the question which is quantitatively measured by parameters of an exponential model. 4/15

November 15, 2024 at 1:48 PM
By plotting the cumulative log-probability graph of items we show that a flat graph means the model is likely contaminated on the question which is quantitatively measured by parameters of an exponential model. 4/15
We introduce LogProber, a simple algorithm that focuses on the model's familiarity with the question rather than the answer to distinguish contamination from confidence. 3/15

November 15, 2024 at 1:48 PM
We introduce LogProber, a simple algorithm that focuses on the model's familiarity with the question rather than the answer to distinguish contamination from confidence. 3/15
Detecting contamination in a model's response to a question can be difficult. Most methods assume a contaminated model will repeatedly give the same answer, but this can also happen when the model is simply confident. How can we separate contamination from confidence? 2/15

November 15, 2024 at 1:48 PM
Detecting contamination in a model's response to a question can be difficult. Most methods assume a contaminated model will repeatedly give the same answer, but this can also happen when the model is simply confident. How can we separate contamination from confidence? 2/15
Many methods for evaluating LLMs rely on benchmarks with specific questions, but this can lead to contamination. If the model has been trained on these items, its answers may reflect memorization rather than understanding, resulting in an biased assessment of its skills. 1/15

November 15, 2024 at 1:48 PM
Many methods for evaluating LLMs rely on benchmarks with specific questions, but this can lead to contamination. If the model has been trained on these items, its answers may reflect memorization rather than understanding, resulting in an biased assessment of its skills. 1/15
🚨New preprint🚨
When testing LLMs with questions, how can we know they did not see the answer in their training? In this new paper we propose a simple out of the box and fast method to spot contamination on short texts with @stepalminteri.bsky.social and Pierre-Yves Oudeyer !
When testing LLMs with questions, how can we know they did not see the answer in their training? In this new paper we propose a simple out of the box and fast method to spot contamination on short texts with @stepalminteri.bsky.social and Pierre-Yves Oudeyer !


November 15, 2024 at 1:48 PM
🚨New preprint🚨
When testing LLMs with questions, how can we know they did not see the answer in their training? In this new paper we propose a simple out of the box and fast method to spot contamination on short texts with @stepalminteri.bsky.social and Pierre-Yves Oudeyer !
When testing LLMs with questions, how can we know they did not see the answer in their training? In this new paper we propose a simple out of the box and fast method to spot contamination on short texts with @stepalminteri.bsky.social and Pierre-Yves Oudeyer !