



@nhminhle.bsky.social
Check out our dataset and findings more in details👇
🌐 github.com/emirkaan5/OWL/
📜 arxiv.org/abs/2505.22945
Work done at @UMassNLP by @alishasrivas.bsky.social, @emirdotexe.bsky.social, @nhminhle.bsky.social, @chautmpham.bsky.social, @markar.bsky.social, and @miyyer.bsky.social.
🌐 github.com/emirkaan5/OWL/
📜 arxiv.org/abs/2505.22945
Work done at @UMassNLP by @alishasrivas.bsky.social, @emirdotexe.bsky.social, @nhminhle.bsky.social, @chautmpham.bsky.social, @markar.bsky.social, and @miyyer.bsky.social.

OWL: Probing Cross-Lingual Recall of Memorized Texts via World Literature
Large language models (LLMs) are known to memorize and recall English text from their pretraining data. However, the extent to which this ability generalizes to non-English languages or transfers...
arxiv.org
May 30, 2025 at 3:37 PM
Check out our dataset and findings more in details👇
🌐 github.com/emirkaan5/OWL/
📜 arxiv.org/abs/2505.22945
Work done at @UMassNLP by @alishasrivas.bsky.social, @emirdotexe.bsky.social, @nhminhle.bsky.social, @chautmpham.bsky.social, @markar.bsky.social, and @miyyer.bsky.social.
🌐 github.com/emirkaan5/OWL/
📜 arxiv.org/abs/2505.22945
Work done at @UMassNLP by @alishasrivas.bsky.social, @emirdotexe.bsky.social, @nhminhle.bsky.social, @chautmpham.bsky.social, @markar.bsky.social, and @miyyer.bsky.social.
🧮 Does quantization (GPTQ) impact cross-lingual knowledge transfer?
LLaMA-3.1-70B: 4-bit > 8-bit ⏩ accuracy drops MORE at 8-bit (up to 25%)
LLaMA-3.1-8B: 8-bit > 4-bit ⏩ accuracy drops MORE at 4-bit (up to 8%)
🧠 Bigger models aren’t always more robust to quantization.
LLaMA-3.1-70B: 4-bit > 8-bit ⏩ accuracy drops MORE at 8-bit (up to 25%)
LLaMA-3.1-8B: 8-bit > 4-bit ⏩ accuracy drops MORE at 4-bit (up to 8%)
🧠 Bigger models aren’t always more robust to quantization.

May 30, 2025 at 3:37 PM
🧮 Does quantization (GPTQ) impact cross-lingual knowledge transfer?
LLaMA-3.1-70B: 4-bit > 8-bit ⏩ accuracy drops MORE at 8-bit (up to 25%)
LLaMA-3.1-8B: 8-bit > 4-bit ⏩ accuracy drops MORE at 4-bit (up to 8%)
🧠 Bigger models aren’t always more robust to quantization.
LLaMA-3.1-70B: 4-bit > 8-bit ⏩ accuracy drops MORE at 8-bit (up to 25%)
LLaMA-3.1-8B: 8-bit > 4-bit ⏩ accuracy drops MORE at 4-bit (up to 8%)
🧠 Bigger models aren’t always more robust to quantization.
🔊 LLMs can transfer knowledge across modalities (Text → Audio).
On GPT-4o-Audio vs Text:
📖 Direct Probing: 75.5% (vs. 92.3%)
👤 Name Cloze: 15.9% (vs. 38.6%)
✍️ Prefix Probing: 27.2% (vs. 22.6%)
Qwen-Omni shows similar trends but lower accuracy.
On GPT-4o-Audio vs Text:
📖 Direct Probing: 75.5% (vs. 92.3%)
👤 Name Cloze: 15.9% (vs. 38.6%)
✍️ Prefix Probing: 27.2% (vs. 22.6%)
Qwen-Omni shows similar trends but lower accuracy.

May 30, 2025 at 3:37 PM
🔊 LLMs can transfer knowledge across modalities (Text → Audio).
On GPT-4o-Audio vs Text:
📖 Direct Probing: 75.5% (vs. 92.3%)
👤 Name Cloze: 15.9% (vs. 38.6%)
✍️ Prefix Probing: 27.2% (vs. 22.6%)
Qwen-Omni shows similar trends but lower accuracy.
On GPT-4o-Audio vs Text:
📖 Direct Probing: 75.5% (vs. 92.3%)
👤 Name Cloze: 15.9% (vs. 38.6%)
✍️ Prefix Probing: 27.2% (vs. 22.6%)
Qwen-Omni shows similar trends but lower accuracy.
What if we perturb the text?
🧩 shuffled text
🎭 masked character names
🙅🏻♀️ passages w/o characters
🚨Reduce accuracy with the degree varying across languages BUT models can still identify the books better than newly published books (0.1%) 🚨
🧩 shuffled text
🎭 masked character names
🙅🏻♀️ passages w/o characters
🚨Reduce accuracy with the degree varying across languages BUT models can still identify the books better than newly published books (0.1%) 🚨

May 30, 2025 at 3:37 PM
What if we perturb the text?
🧩 shuffled text
🎭 masked character names
🙅🏻♀️ passages w/o characters
🚨Reduce accuracy with the degree varying across languages BUT models can still identify the books better than newly published books (0.1%) 🚨
🧩 shuffled text
🎭 masked character names
🙅🏻♀️ passages w/o characters
🚨Reduce accuracy with the degree varying across languages BUT models can still identify the books better than newly published books (0.1%) 🚨
LLMs can identify book titles and authors across languages - even those not seen during pre-training:
63.8% accuracy on English passages
47.2% on official translations (Spanish, Turkish, Vietnamese) 🇪🇸 🇹🇷 🇻🇳
36.5% on completely unseen languages like Sesotho & Maithili 🌍
63.8% accuracy on English passages
47.2% on official translations (Spanish, Turkish, Vietnamese) 🇪🇸 🇹🇷 🇻🇳
36.5% on completely unseen languages like Sesotho & Maithili 🌍

May 30, 2025 at 3:37 PM
LLMs can identify book titles and authors across languages - even those not seen during pre-training:
63.8% accuracy on English passages
47.2% on official translations (Spanish, Turkish, Vietnamese) 🇪🇸 🇹🇷 🇻🇳
36.5% on completely unseen languages like Sesotho & Maithili 🌍
63.8% accuracy on English passages
47.2% on official translations (Spanish, Turkish, Vietnamese) 🇪🇸 🇹🇷 🇻🇳
36.5% on completely unseen languages like Sesotho & Maithili 🌍
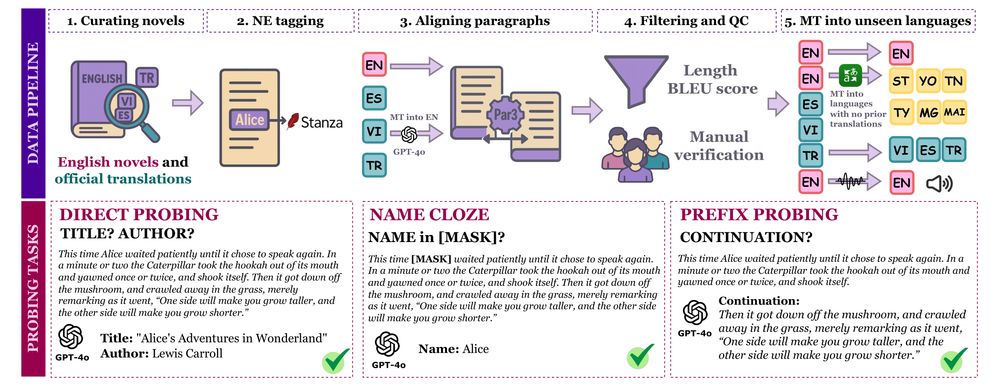
OWL has aligned excerpts from 20 EN novels, with translations in ES 🇪🇸, TR 🇹🇷, VI 🇻🇳 + 6 new low-resource languages 🌍 & EN audio 🔊
We probe LLMs to:
1️⃣ identify book/author (direct probing)
2️⃣ predict masked names (name cloze)
3️⃣ generate continuation (prefix probing)
We probe LLMs to:
1️⃣ identify book/author (direct probing)
2️⃣ predict masked names (name cloze)
3️⃣ generate continuation (prefix probing)
May 30, 2025 at 3:37 PM
OWL has aligned excerpts from 20 EN novels, with translations in ES 🇪🇸, TR 🇹🇷, VI 🇻🇳 + 6 new low-resource languages 🌍 & EN audio 🔊
We probe LLMs to:
1️⃣ identify book/author (direct probing)
2️⃣ predict masked names (name cloze)
3️⃣ generate continuation (prefix probing)
We probe LLMs to:
1️⃣ identify book/author (direct probing)
2️⃣ predict masked names (name cloze)
3️⃣ generate continuation (prefix probing)