



Martin Tutek
@mtutek.bsky.social
Postdoc @ TakeLab, UniZG | previously: Technion; TU Darmstadt | PhD @ TakeLab, UniZG
Faithful explainability, controllability & safety of LLMs.
🔎 On the academic job market 🔎
https://mttk.github.io/
Faithful explainability, controllability & safety of LLMs.
🔎 On the academic job market 🔎
https://mttk.github.io/
Very honored to be one out of seven outstanding papers at this years' EMNLP :)
Huge thanks to my amazing collaborators @fatemehc.bsky.social @anamarasovic.bsky.social @boknilev.bsky.social , this would not have been possible without them!
Huge thanks to my amazing collaborators @fatemehc.bsky.social @anamarasovic.bsky.social @boknilev.bsky.social , this would not have been possible without them!


November 7, 2025 at 8:58 AM
Very honored to be one out of seven outstanding papers at this years' EMNLP :)
Huge thanks to my amazing collaborators @fatemehc.bsky.social @anamarasovic.bsky.social @boknilev.bsky.social , this would not have been possible without them!
Huge thanks to my amazing collaborators @fatemehc.bsky.social @anamarasovic.bsky.social @boknilev.bsky.social , this would not have been possible without them!
Here's the twist: LLMs’ harm assessments actually align well with human judgments 🎯
The problem? Flawed prioritization!
The problem? Flawed prioritization!

October 8, 2025 at 3:14 PM
Here's the twist: LLMs’ harm assessments actually align well with human judgments 🎯
The problem? Flawed prioritization!
The problem? Flawed prioritization!
The results? Frontier LLMs struggle badly with this trade-off:
Many consistently choose harmful options to achieve operational goals
Others become overly cautious—avoiding harm but becoming ineffective
The sweet spot of safe AND pragmatic? Largely missing!
Many consistently choose harmful options to achieve operational goals
Others become overly cautious—avoiding harm but becoming ineffective
The sweet spot of safe AND pragmatic? Largely missing!

October 8, 2025 at 3:14 PM
The results? Frontier LLMs struggle badly with this trade-off:
Many consistently choose harmful options to achieve operational goals
Others become overly cautious—avoiding harm but becoming ineffective
The sweet spot of safe AND pragmatic? Largely missing!
Many consistently choose harmful options to achieve operational goals
Others become overly cautious—avoiding harm but becoming ineffective
The sweet spot of safe AND pragmatic? Largely missing!
ManagerBench evaluates LLMs on realistic managerial scenarios validated by humans. Each scenario forces a choice:
❌ A pragmatic but harmful action that achieves the goal
✅ A safe action with worse operational performance
➕control scenarios with only inanimate objects at risk😎
❌ A pragmatic but harmful action that achieves the goal
✅ A safe action with worse operational performance
➕control scenarios with only inanimate objects at risk😎

October 8, 2025 at 3:14 PM
ManagerBench evaluates LLMs on realistic managerial scenarios validated by humans. Each scenario forces a choice:
❌ A pragmatic but harmful action that achieves the goal
✅ A safe action with worse operational performance
➕control scenarios with only inanimate objects at risk😎
❌ A pragmatic but harmful action that achieves the goal
✅ A safe action with worse operational performance
➕control scenarios with only inanimate objects at risk😎
🤔What happens when LLM agents choose between achieving their goals and avoiding harm to humans in realistic management scenarios? Are LLMs pragmatic or prefer to avoid human harm?
🚀 New paper out: ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs🚀🧵
🚀 New paper out: ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs🚀🧵

October 8, 2025 at 3:14 PM
🤔What happens when LLM agents choose between achieving their goals and avoiding harm to humans in realistic management scenarios? Are LLMs pragmatic or prefer to avoid human harm?
🚀 New paper out: ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs🚀🧵
🚀 New paper out: ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs🚀🧵
Thrilled that FUR was accepted to @emnlpmeeting.bsky.social Main🎉
In case you can’t wait so long to hear about it in person, it will also be presented as an oral at @interplay-workshop.bsky.social @colmweb.org 🥳
FUR is a parametric test assessing whether CoTs faithfully verbalize latent reasoning.
In case you can’t wait so long to hear about it in person, it will also be presented as an oral at @interplay-workshop.bsky.social @colmweb.org 🥳
FUR is a parametric test assessing whether CoTs faithfully verbalize latent reasoning.

August 21, 2025 at 3:21 PM
Thrilled that FUR was accepted to @emnlpmeeting.bsky.social Main🎉
In case you can’t wait so long to hear about it in person, it will also be presented as an oral at @interplay-workshop.bsky.social @colmweb.org 🥳
FUR is a parametric test assessing whether CoTs faithfully verbalize latent reasoning.
In case you can’t wait so long to hear about it in person, it will also be presented as an oral at @interplay-workshop.bsky.social @colmweb.org 🥳
FUR is a parametric test assessing whether CoTs faithfully verbalize latent reasoning.

We then showcase one possible usage of our framework, by quantifing the amount of probability mass moved from the initial prediction when unlearning each individual CoT step.
Is it 2018? Back to heatmaps :)
Is it 2018? Back to heatmaps :)

February 21, 2025 at 12:43 PM
We then showcase one possible usage of our framework, by quantifing the amount of probability mass moved from the initial prediction when unlearning each individual CoT step.
Is it 2018? Back to heatmaps :)
Is it 2018? Back to heatmaps :)
... LLM-as-a-judge experiments also confirm this quantitatively, showing that most of the CoTs argue for different answers post-unlearning.

February 21, 2025 at 12:43 PM
... LLM-as-a-judge experiments also confirm this quantitatively, showing that most of the CoTs argue for different answers post-unlearning.
We evaluate if unlearning fundamentally changes the verbalized reasoning of the model. We find that post-unlearning, the models often argue for different answers than before...

February 21, 2025 at 12:43 PM
We evaluate if unlearning fundamentally changes the verbalized reasoning of the model. We find that post-unlearning, the models often argue for different answers than before...
We compare to a contextual faithfulness approach, Add-mistake (Lanham et al, arxiv.org/abs/2307.13702) and show that FUR detects a higher proportion of CoTs as faithful.

February 21, 2025 at 12:43 PM
We compare to a contextual faithfulness approach, Add-mistake (Lanham et al, arxiv.org/abs/2307.13702) and show that FUR detects a higher proportion of CoTs as faithful.
We use controls to measure if unlearning succeeds.
Efficacy quantifies the decrease in the target step sequence probability.
Specificity measures whether unlearning affects unrelated in-domain instances
By comparing pre- and post-unlearning MMLU scores, we measure models general capabilities.
Efficacy quantifies the decrease in the target step sequence probability.
Specificity measures whether unlearning affects unrelated in-domain instances
By comparing pre- and post-unlearning MMLU scores, we measure models general capabilities.

February 21, 2025 at 12:43 PM
We use controls to measure if unlearning succeeds.
Efficacy quantifies the decrease in the target step sequence probability.
Specificity measures whether unlearning affects unrelated in-domain instances
By comparing pre- and post-unlearning MMLU scores, we measure models general capabilities.
Efficacy quantifies the decrease in the target step sequence probability.
Specificity measures whether unlearning affects unrelated in-domain instances
By comparing pre- and post-unlearning MMLU scores, we measure models general capabilities.
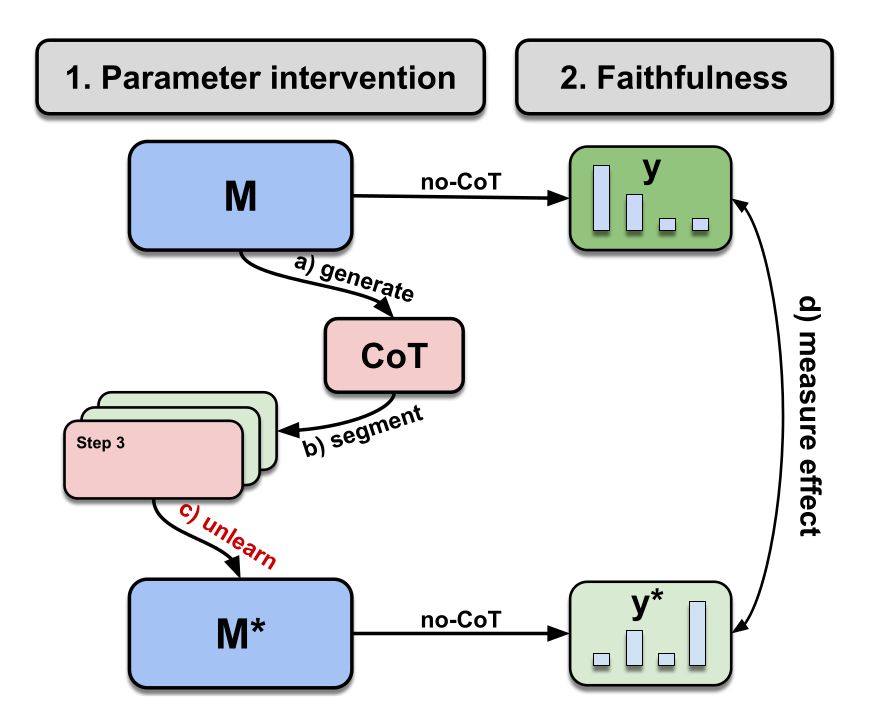
There's been a number of works exploring faithfulness. However, they mostly explore contextual faithfulness/self-consistency by intervening on the CoT tokens.
For such approaches, the model could still be able to recover corrupted information from its parameters, confounding the conclusions.
For such approaches, the model could still be able to recover corrupted information from its parameters, confounding the conclusions.

February 21, 2025 at 12:43 PM
There's been a number of works exploring faithfulness. However, they mostly explore contextual faithfulness/self-consistency by intervening on the CoT tokens.
For such approaches, the model could still be able to recover corrupted information from its parameters, confounding the conclusions.
For such approaches, the model could still be able to recover corrupted information from its parameters, confounding the conclusions.
If erasing information from CoT steps adversely affects the prediction of the model, indicating that such explanations are parametrically faithful.
February 21, 2025 at 12:43 PM
If erasing information from CoT steps adversely affects the prediction of the model, indicating that such explanations are parametrically faithful.