



Michael Tschannen
@mtschannen.bsky.social
Research Scientist @GoogleDeepMind. Representation learning for multimodal understanding and generation.
mitscha.github.io
mitscha.github.io
HF model collection for transformers:
huggingface.co/collections/...
HF model collection for OpenCLIP and timm:
huggingface.co/collections/...
And of course big_vision checkpoints:
github.com/google-resea...
huggingface.co/collections/...
HF model collection for OpenCLIP and timm:
huggingface.co/collections/...
And of course big_vision checkpoints:
github.com/google-resea...

SigLIP2 - a google Collection
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
February 22, 2025 at 3:34 PM
HF model collection for transformers:
huggingface.co/collections/...
HF model collection for OpenCLIP and timm:
huggingface.co/collections/...
And of course big_vision checkpoints:
github.com/google-resea...
huggingface.co/collections/...
HF model collection for OpenCLIP and timm:
huggingface.co/collections/...
And of course big_vision checkpoints:
github.com/google-resea...
Paper:
arxiv.org/abs/2502.14786
HF blog post from @arig23498.bsky.social et al. with a gentle intro to the training recipe and a demo:
huggingface.co/blog/siglip2
Thread with results overview from Xiaohua (only on X, sorry - these are all in the paper):
x.com/XiaohuaZhai/...
arxiv.org/abs/2502.14786
HF blog post from @arig23498.bsky.social et al. with a gentle intro to the training recipe and a demo:
huggingface.co/blog/siglip2
Thread with results overview from Xiaohua (only on X, sorry - these are all in the paper):
x.com/XiaohuaZhai/...

SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training obje...
arxiv.org
February 22, 2025 at 3:34 PM
Paper:
arxiv.org/abs/2502.14786
HF blog post from @arig23498.bsky.social et al. with a gentle intro to the training recipe and a demo:
huggingface.co/blog/siglip2
Thread with results overview from Xiaohua (only on X, sorry - these are all in the paper):
x.com/XiaohuaZhai/...
arxiv.org/abs/2502.14786
HF blog post from @arig23498.bsky.social et al. with a gentle intro to the training recipe and a demo:
huggingface.co/blog/siglip2
Thread with results overview from Xiaohua (only on X, sorry - these are all in the paper):
x.com/XiaohuaZhai/...
It’s not, good catch.
December 3, 2024 at 9:51 PM
It’s not, good catch.
Very nice! I knew some soft-token TTS papers, but none so far using AR + normalizing flows. Thanks for sharing!
December 3, 2024 at 9:44 AM
Very nice! I knew some soft-token TTS papers, but none so far using AR + normalizing flows. Thanks for sharing!
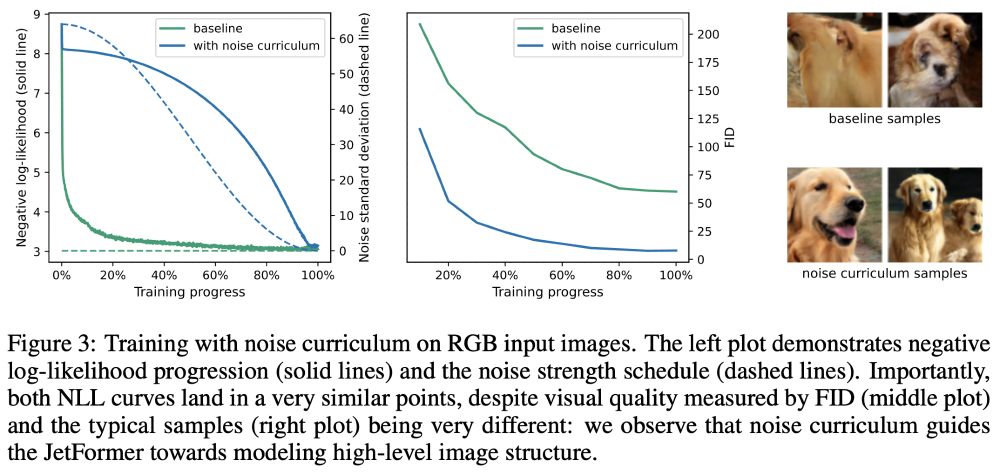
The noise curriculum guides the (image generation) learning process to first learn high-level, global structure and later low-level structure/texture. Maximum likelihood “tends to focus” mostly on the latter.
December 3, 2024 at 8:02 AM
The noise curriculum guides the (image generation) learning process to first learn high-level, global structure and later low-level structure/texture. Maximum likelihood “tends to focus” mostly on the latter.
December 2, 2024 at 4:41 PM
To our knowledge, JetFormer is the first model capable of generating high fidelity images and producing strong log-likelihood bounds.
So far we explored a simple setup (image/text pairs, no post-training), and hope JetFormer inspires more (visual) tokenizer-free models!
7/
So far we explored a simple setup (image/text pairs, no post-training), and hope JetFormer inspires more (visual) tokenizer-free models!
7/
December 2, 2024 at 4:41 PM
To our knowledge, JetFormer is the first model capable of generating high fidelity images and producing strong log-likelihood bounds.
So far we explored a simple setup (image/text pairs, no post-training), and hope JetFormer inspires more (visual) tokenizer-free models!
7/
So far we explored a simple setup (image/text pairs, no post-training), and hope JetFormer inspires more (visual) tokenizer-free models!
7/
Finally, why getting rid of visual tokenizers/VQ-VAEs?
- They can induce information loss (e.g. small text)
- Removing specialized components was a key driver of recent progress (bitter lesson)
- Raw likelihoods are comparable across models (for hill climbing, scaling laws)
6/
- They can induce information loss (e.g. small text)
- Removing specialized components was a key driver of recent progress (bitter lesson)
- Raw likelihoods are comparable across models (for hill climbing, scaling laws)
6/
December 2, 2024 at 4:41 PM
Finally, why getting rid of visual tokenizers/VQ-VAEs?
- They can induce information loss (e.g. small text)
- Removing specialized components was a key driver of recent progress (bitter lesson)
- Raw likelihoods are comparable across models (for hill climbing, scaling laws)
6/
- They can induce information loss (e.g. small text)
- Removing specialized components was a key driver of recent progress (bitter lesson)
- Raw likelihoods are comparable across models (for hill climbing, scaling laws)
6/
Importantly, this is simple additive Gaussian noise on the training images (i.e. a data augmentation). JetFormer does neither depend on it (or its parameters), nor is it trained for denoising like diffusion models.
5/
5/
December 2, 2024 at 4:41 PM
Importantly, this is simple additive Gaussian noise on the training images (i.e. a data augmentation). JetFormer does neither depend on it (or its parameters), nor is it trained for denoising like diffusion models.
5/
5/
Learning to generate high-fidelity images with maximum likelihood is tricky. To bias the model towards nicer-looking images we introduce a noise curriculum: Gaussian noise added to the input image and annealed to 0 during training, s.t. high-level details are learned first.
4/
4/
December 2, 2024 at 4:41 PM
Learning to generate high-fidelity images with maximum likelihood is tricky. To bias the model towards nicer-looking images we introduce a noise curriculum: Gaussian noise added to the input image and annealed to 0 during training, s.t. high-level details are learned first.
4/
4/
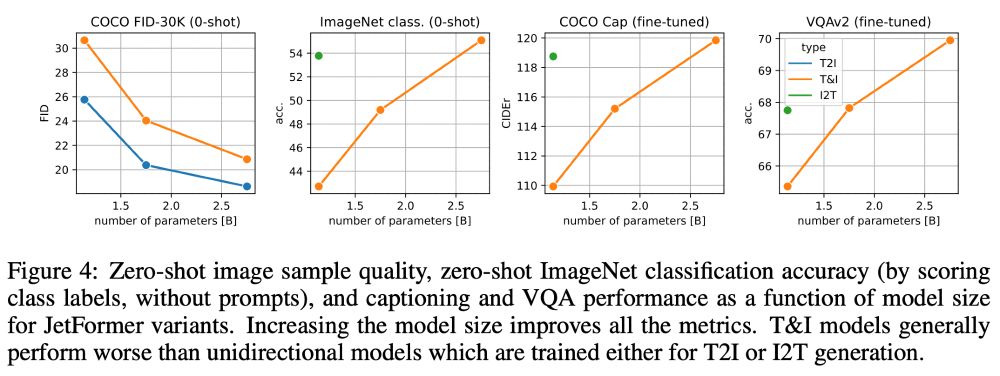
Conceptually, the normalizing flow serves as both an image encoder for perception tasks and an image decoder for image generation tasks during inference.
We train JetFormer to maximize the likelihood of the multimodal data, without auxiliary losses (perceptual or similar).
3/
We train JetFormer to maximize the likelihood of the multimodal data, without auxiliary losses (perceptual or similar).
3/
December 2, 2024 at 4:41 PM
Conceptually, the normalizing flow serves as both an image encoder for perception tasks and an image decoder for image generation tasks during inference.
We train JetFormer to maximize the likelihood of the multimodal data, without auxiliary losses (perceptual or similar).
3/
We train JetFormer to maximize the likelihood of the multimodal data, without auxiliary losses (perceptual or similar).
3/
We leverage a normalizing flow (“jet”) to obtain a soft-token image representation that is end-to-end trained with a multimodal transformer for next-token prediction. The soft token distribution is modeled with a GMM à la GIVT.
arxiv.org/abs/2312.02116
2/
arxiv.org/abs/2312.02116
2/
GIVT: Generative Infinite-Vocabulary Transformers
We introduce Generative Infinite-Vocabulary Transformers (GIVT) which generate vector sequences with real-valued entries, instead of discrete tokens from a finite vocabulary. To this end, we propose t...
arxiv.org
December 2, 2024 at 4:41 PM
We leverage a normalizing flow (“jet”) to obtain a soft-token image representation that is end-to-end trained with a multimodal transformer for next-token prediction. The soft token distribution is modeled with a GMM à la GIVT.
arxiv.org/abs/2312.02116
2/
arxiv.org/abs/2312.02116
2/