



Martin Schrimpf
@mschrimpf.bsky.social
NeuroAI Prof @EPFL 🇨🇭. ML + Neuro 🤖🧠. Brain-Score, CORnet, Vision, Language. Previously: PhD @MIT, ML @Salesforce, Neuro @HarvardMed, & co-founder @Integreat. go.epfl.ch/NeuroAI
To expand on this: When we built our stimulation->neural predictor (www.biorxiv.org/content/10.1...), we didn't find much experimental data to constrain the model. The best we found was data from @markhisted.org and biophysical modeling by Kumaravelu et al.

October 9, 2025 at 11:00 AM
To expand on this: When we built our stimulation->neural predictor (www.biorxiv.org/content/10.1...), we didn't find much experimental data to constrain the model. The best we found was data from @markhisted.org and biophysical modeling by Kumaravelu et al.
A glimpse at what #NeuroAI brain models might enable: a topographic vision model predicts stimulation patterns that steer complex object recognition behavior in primates. This could be a key 'software' component for visual prosthetic hardware 🧠🤖🧪

October 8, 2025 at 11:11 AM
A glimpse at what #NeuroAI brain models might enable: a topographic vision model predicts stimulation patterns that steer complex object recognition behavior in primates. This could be a key 'software' component for visual prosthetic hardware 🧠🤖🧪
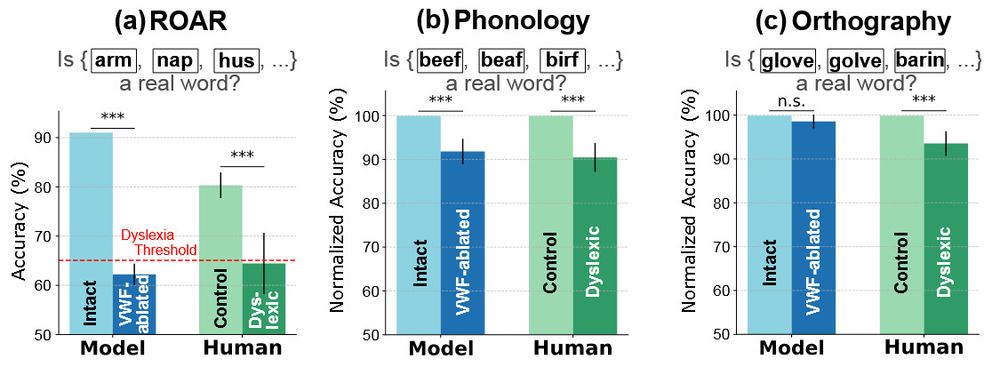
Digging deeper into the ablated model, we found that its behavioral patterns mirror phonological deficits of dyslexic humans, without a significant deficit in orthographic processing. This connects to experimental work suggesting that phonological and orthographic deficits have distinct origins.
October 2, 2025 at 12:10 PM
Digging deeper into the ablated model, we found that its behavioral patterns mirror phonological deficits of dyslexic humans, without a significant deficit in orthographic processing. This connects to experimental work suggesting that phonological and orthographic deficits have distinct origins.
It turns out that the ablation of these units has a very specific effect: it reduced reading performance to dyslexia levels *but* keeps visual reasoning performance intact. This does not happen with random units, so localization is key.

October 2, 2025 at 12:10 PM
It turns out that the ablation of these units has a very specific effect: it reduced reading performance to dyslexia levels *but* keeps visual reasoning performance intact. This does not happen with random units, so localization is key.
We achieve this via the localization and subsequent ablation of units that are "visual-word-form selective" i.e. are more active for the visual presentation of words over other images. After ablating the units we test the effect on behavior in benchmarks testing reading and other control tasks


October 2, 2025 at 12:10 PM
We achieve this via the localization and subsequent ablation of units that are "visual-word-form selective" i.e. are more active for the visual presentation of words over other images. After ablating the units we test the effect on behavior in benchmarks testing reading and other control tasks
I've been arguing that #NeuroAI should model the brain in health *and* in disease -- very excited to share a first step from Melika Honarmand: inducing dyslexia in vision-language-models via targeted perturbations of visual-word-form units (analogous to human VWFA) 🧠🤖🧪 arxiv.org/abs/2509.24597

October 2, 2025 at 12:10 PM
I've been arguing that #NeuroAI should model the brain in health *and* in disease -- very excited to share a first step from Melika Honarmand: inducing dyslexia in vision-language-models via targeted perturbations of visual-word-form units (analogous to human VWFA) 🧠🤖🧪 arxiv.org/abs/2509.24597
Digging deeper into the ablated model, we found that its behavioral patterns mirror phonological deficits of dyslexic humans, without a significant deficit in orthographic processing. This connects to experimental work suggesting that phonological and orthographic deficits have distinct origins.

October 2, 2025 at 12:04 PM
Digging deeper into the ablated model, we found that its behavioral patterns mirror phonological deficits of dyslexic humans, without a significant deficit in orthographic processing. This connects to experimental work suggesting that phonological and orthographic deficits have distinct origins.
It turns out that the ablation of these units has a very specific effect: it reduced reading performance to dyslexia levels *but* keeps visual reasoning performance intact. This does not happen with random units, so localization is key.

October 2, 2025 at 12:04 PM
It turns out that the ablation of these units has a very specific effect: it reduced reading performance to dyslexia levels *but* keeps visual reasoning performance intact. This does not happen with random units, so localization is key.
We achieve this via the localization and subsequent ablation of units that are "visual-word-form selective" i.e. are more active for the visual presentation of words over other images. After ablating the units we test the effect on behavior in benchmarks testing reading and other control tasks


October 2, 2025 at 12:04 PM
We achieve this via the localization and subsequent ablation of units that are "visual-word-form selective" i.e. are more active for the visual presentation of words over other images. After ablating the units we test the effect on behavior in benchmarks testing reading and other control tasks
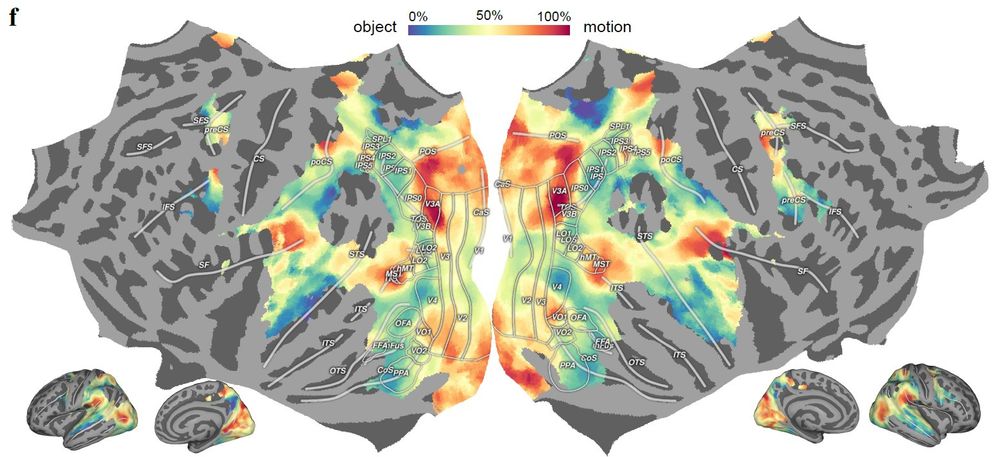
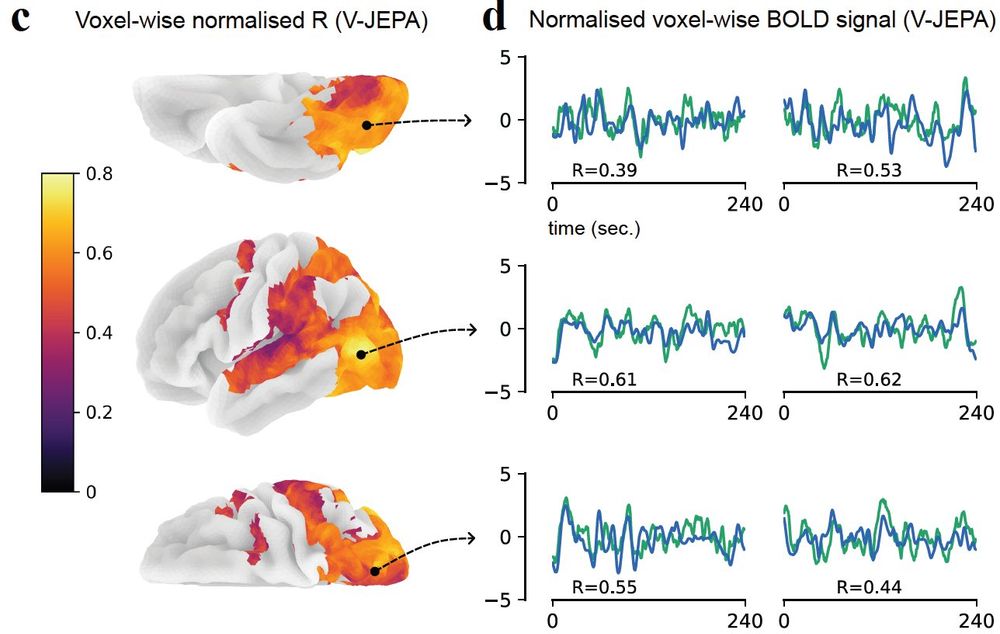
which enables a fine-grain mapping of cortical space with a new multi-task relevance analysis; the accurate (R~0.5) prediction of second-by-second human brain activity, which makes us more confident in the characterization of action understanding pathways; and a couple more
August 1, 2025 at 7:59 AM
which enables a fine-grain mapping of cortical space with a new multi-task relevance analysis; the accurate (R~0.5) prediction of second-by-second human brain activity, which makes us more confident in the characterization of action understanding pathways; and a couple more
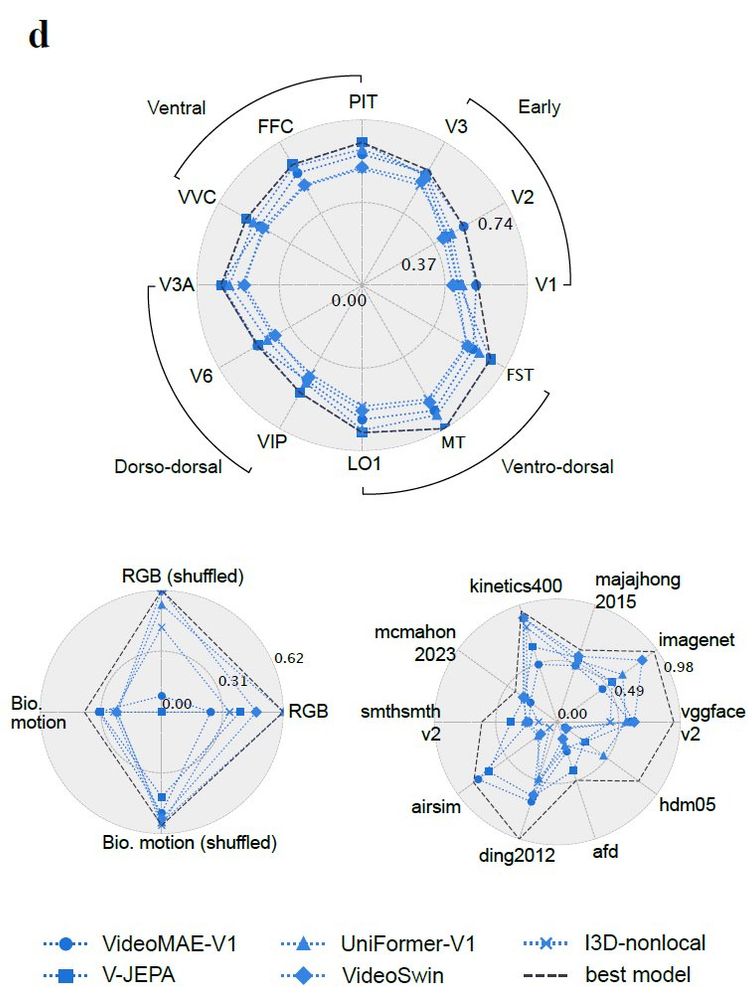
The mouse work is definitely relevant, will make sure to reference (apologies for the oversight). I do think there are substantial novelties that have only been made possible with more recent powerful video models: the tight relation to behavior and a variety of tasks,
August 1, 2025 at 7:59 AM
The mouse work is definitely relevant, will make sure to reference (apologies for the oversight). I do think there are substantial novelties that have only been made possible with more recent powerful video models: the tight relation to behavior and a variety of tasks,
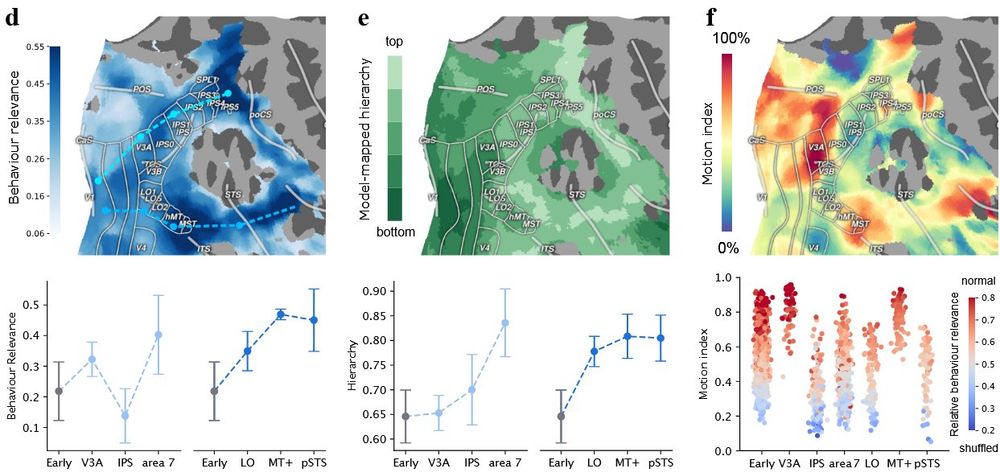
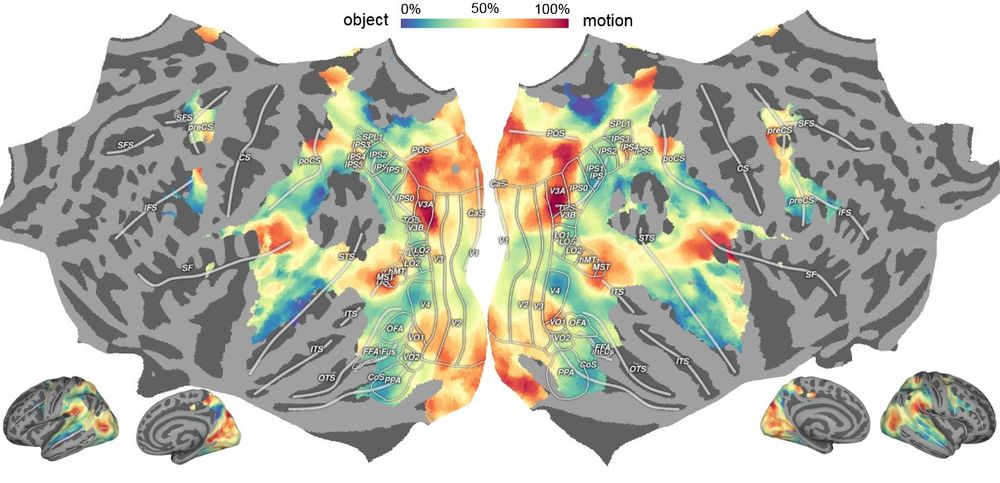
Where models really shine is their ability to integrate disparate findings. Our findings not only recapitulate known brain structures, they also characterize action understanding pathways. The models help us make sense of hierarchy, behavioral relevance, and functional processing
July 30, 2025 at 3:42 PM
Where models really shine is their ability to integrate disparate findings. Our findings not only recapitulate known brain structures, they also characterize action understanding pathways. The models help us make sense of hierarchy, behavioral relevance, and functional processing
Brain-like computations support object and motion recognition that map onto classic visual ventral and dorsal streams. But looking deeper, we found a much more distributed computational landscape -- which may emerge from a single computational goal: modeling the visual world
July 30, 2025 at 3:42 PM
Brain-like computations support object and motion recognition that map onto classic visual ventral and dorsal streams. But looking deeper, we found a much more distributed computational landscape -- which may emerge from a single computational goal: modeling the visual world
What makes visual processing in the brain so powerful and flexible? Very excited to share our new work where we started from SOTA models that accurately predict dynamic brain activity during hours of video watching, and investigated core computations underlying visual perception

July 30, 2025 at 3:42 PM
What makes visual processing in the brain so powerful and flexible? Very excited to share our new work where we started from SOTA models that accurately predict dynamic brain activity during hours of video watching, and investigated core computations underlying visual perception
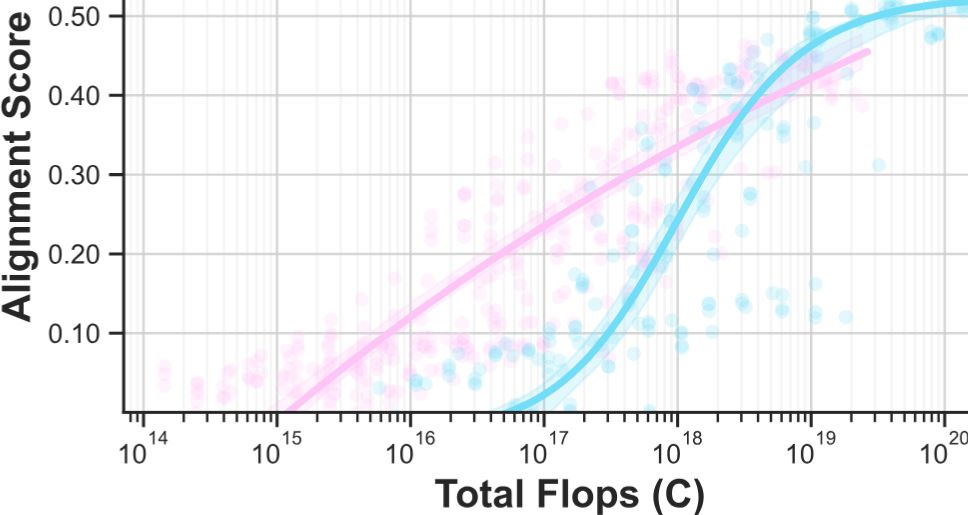
Have you by any chance tested recent larger models? Would they be more similar? At least for alignment with human classification choices, it seems that scale is really key in closely matching human behavior (plot from arxiv.org/abs/2411.05712)
June 27, 2025 at 9:34 AM
Have you by any chance tested recent larger models? Would they be more similar? At least for alignment with human classification choices, it seems that scale is really key in closely matching human behavior (plot from arxiv.org/abs/2411.05712)
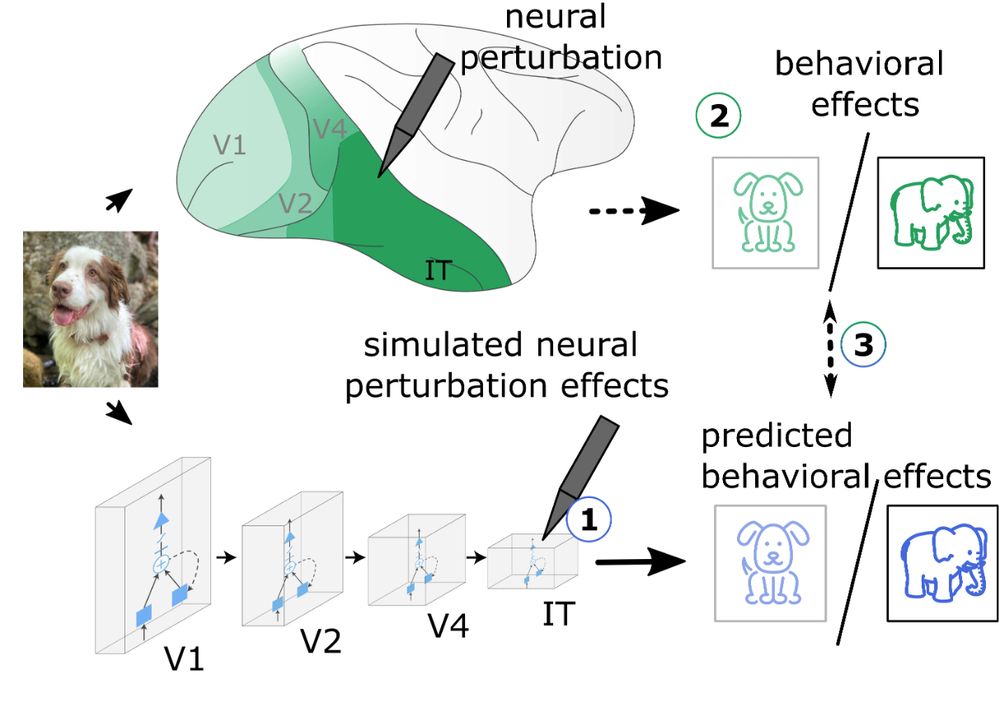
It depends on how extensive you think "*training* on interventional data" will have to be. Eg, topographic models with a simple "perturbation module" to describe the change in neural activity from interventions were quite powerful in predicting behavioral effects www.biorxiv.org/content/10.1...
May 5, 2025 at 5:09 PM
It depends on how extensive you think "*training* on interventional data" will have to be. Eg, topographic models with a simple "perturbation module" to describe the change in neural activity from interventions were quite powerful in predicting behavioral effects www.biorxiv.org/content/10.1...
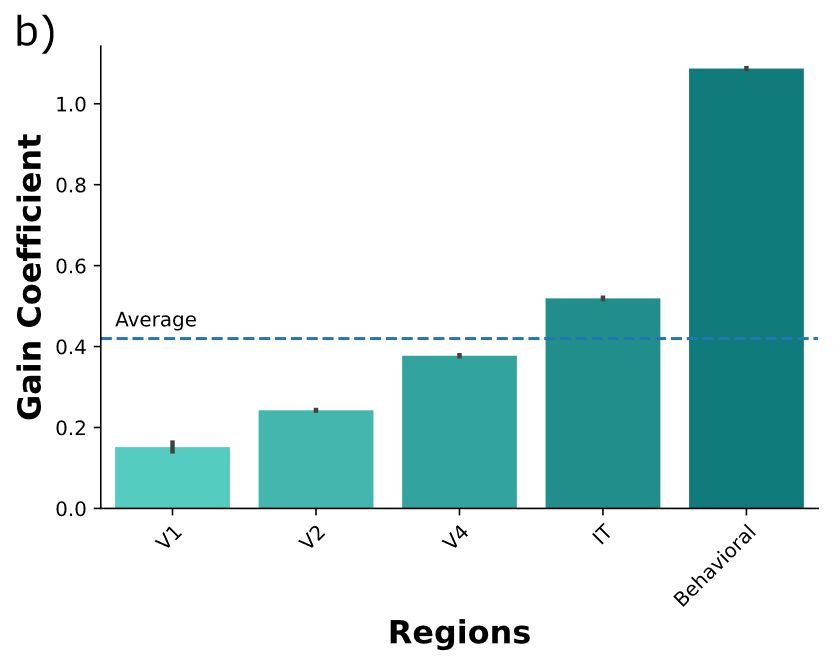
Beyond the distinction of behavioral and neural alignment, there is actually a striking gradient: scaling helps more for higher-level visual regions but only barely for early visual areas.
November 12, 2024 at 1:51 PM
Beyond the distinction of behavioral and neural alignment, there is actually a striking gradient: scaling helps more for higher-level visual regions but only barely for early visual areas.
Across over 600 models that we trained under comparable conditions, we identify increases in *data* size as a stronger driver of alignment over increases in *model* size

November 12, 2024 at 1:51 PM
Across over 600 models that we trained under comparable conditions, we identify increases in *data* size as a stronger driver of alignment over increases in *model* size
This finding is true across different model types, with strong or weak priors (e.g. transformers or conv nets) -- they all converge to the same alignment, with neural alignment saturating

November 12, 2024 at 1:51 PM
This finding is true across different model types, with strong or weak priors (e.g. transformers or conv nets) -- they all converge to the same alignment, with neural alignment saturating
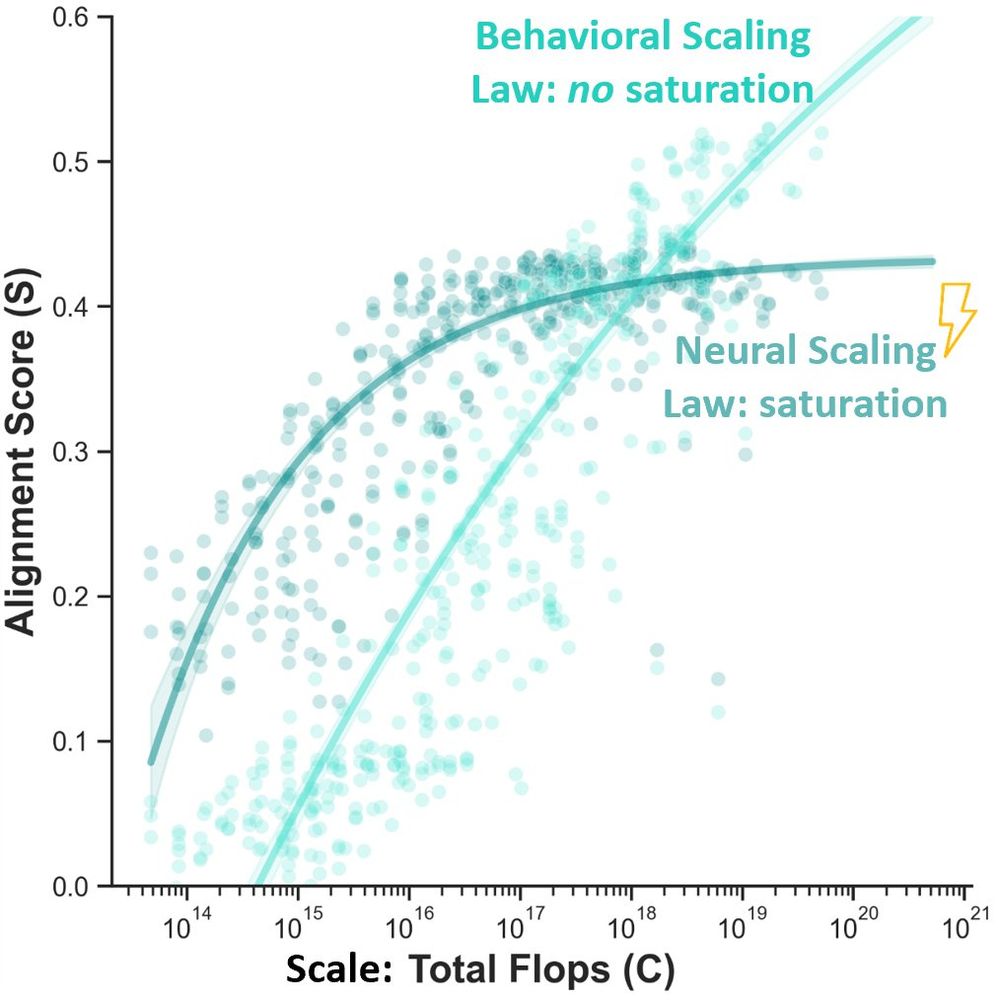
For a while, gains in AI have translated into gains in modeling the brain. We test if that will continue to be the case with recent advances in scaling. Surprisingly we get mixed results: while increased scale advances model alignment to behavior, neural alignment saturates: arxiv.org/abs/2411.05712
November 12, 2024 at 1:51 PM
For a while, gains in AI have translated into gains in modeling the brain. We test if that will continue to be the case with recent advances in scaling. Surprisingly we get mixed results: while increased scale advances model alignment to behavior, neural alignment saturates: arxiv.org/abs/2411.05712
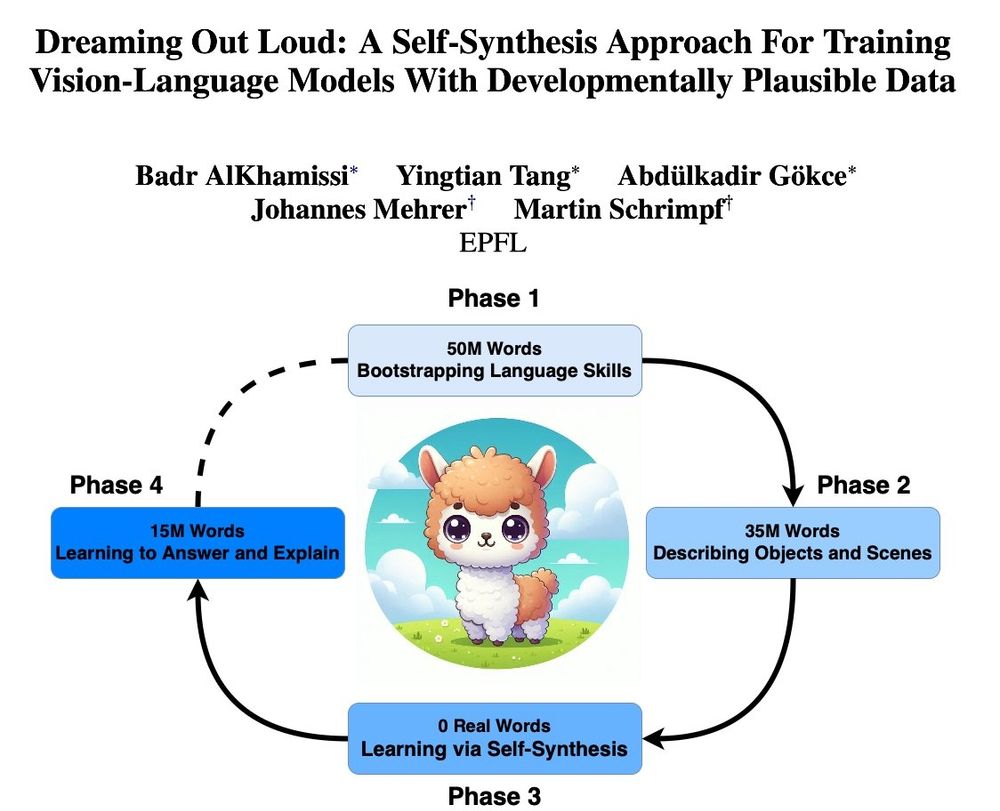
How can we train LLMs with <100M words? In our #BabyLM paper, we introduce a new language+vision self-synthesis training recipe to tackle this question:
Our model learns over 4 phases -- most crucially self-captioning unseen images to generate synthetic language data
arxiv.org/abs/2411.00828
Our model learns over 4 phases -- most crucially self-captioning unseen images to generate synthetic language data
arxiv.org/abs/2411.00828
November 12, 2024 at 1:43 AM
How can we train LLMs with <100M words? In our #BabyLM paper, we introduce a new language+vision self-synthesis training recipe to tackle this question:
Our model learns over 4 phases -- most crucially self-captioning unseen images to generate synthetic language data
arxiv.org/abs/2411.00828
Our model learns over 4 phases -- most crucially self-captioning unseen images to generate synthetic language data
arxiv.org/abs/2411.00828
We actually just rolled out a revamp of the model page so it now more prominently shows the reference. Although this particular submission doesn't seem to have one stored. Based on the name and architecture I'm guessing it's a Convolutional Vision Transformer huggingface.co/docs/transfo...

November 12, 2024 at 12:56 AM
We actually just rolled out a revamp of the model page so it now more prominently shows the reference. Although this particular submission doesn't seem to have one stored. Based on the name and architecture I'm guessing it's a Convolutional Vision Transformer huggingface.co/docs/transfo...
Applications now open for the Summer@EPFL program summer.epfl.ch -- 3-month fellowship for Bachelor/Master students to immerse yourself in research

November 5, 2024 at 9:21 AM
Applications now open for the Summer@EPFL program summer.epfl.ch -- 3-month fellowship for Bachelor/Master students to immerse yourself in research
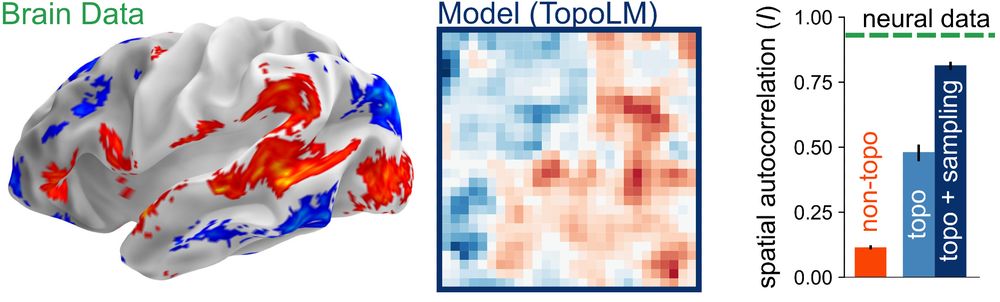
Functional responses in the brain to linguistic inputs are spatially organized -- but why? We show that a simple smoothness loss added to language model training explains a range of topographic phenomena in neuroscience: arxiv.org/abs/2410.11516
#NeuroAI #neuroscience #language
#NeuroAI #neuroscience #language
October 17, 2024 at 7:51 PM
Functional responses in the brain to linguistic inputs are spatially organized -- but why? We show that a simple smoothness loss added to language model training explains a range of topographic phenomena in neuroscience: arxiv.org/abs/2410.11516
#NeuroAI #neuroscience #language
#NeuroAI #neuroscience #language
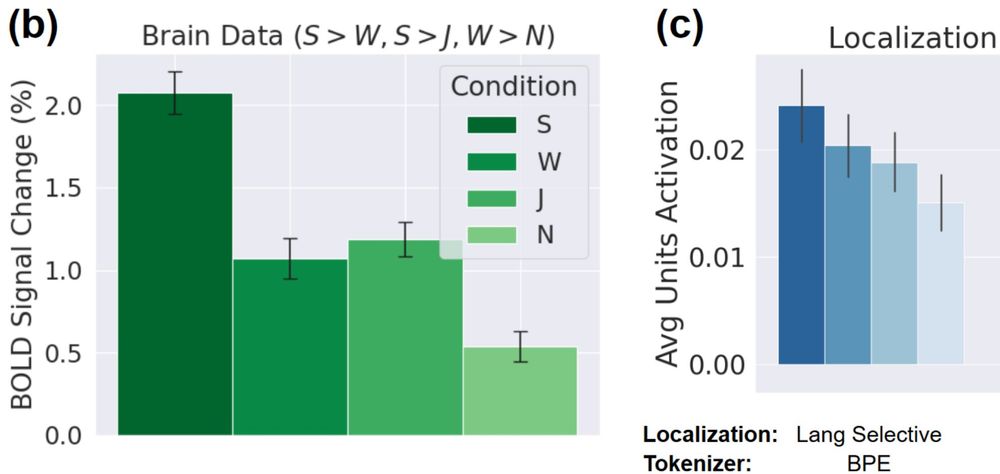
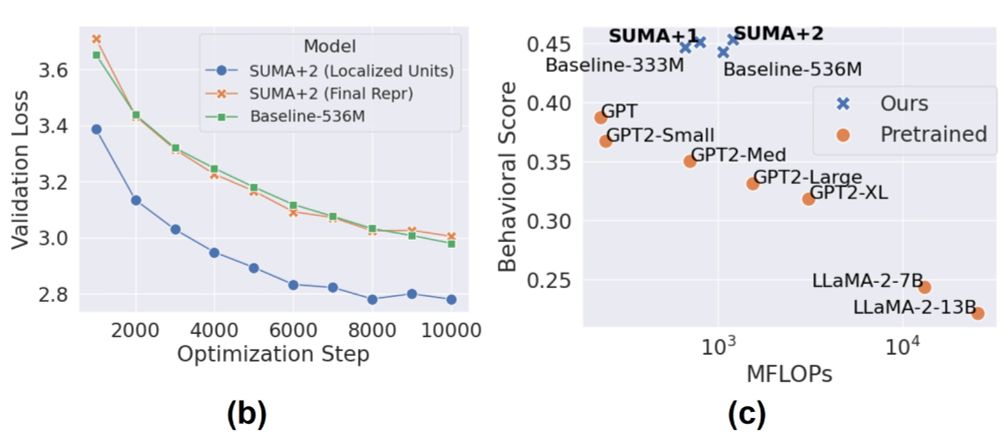
With these findings, we built a simple untrained network "SUMA" with state-of-the-art alignment to brain and behavioral data -- this feature encoder provides representations that are then useful for efficient language modeling 2/
June 25, 2024 at 1:51 PM
With these findings, we built a simple untrained network "SUMA" with state-of-the-art alignment to brain and behavioral data -- this feature encoder provides representations that are then useful for efficient language modeling 2/