




Michael Kirchhof (ICML)
@mkirchhof.bsky.social
Research Scientist at Apple for uncertainty quantification.
Memories complement RAG and can be combined for enhanced results. Post-hoc memory learning is possible (for Qwen, Gemma, etc), with more ablations in the paper.
This was spearheaded by Hadi Pouransari, with David Grangier, C Thomas, me, and Oncel Tuzel at the Apple Machine Learning Research team :)
This was spearheaded by Hadi Pouransari, with David Grangier, C Thomas, me, and Oncel Tuzel at the Apple Machine Learning Research team :)
October 6, 2025 at 4:06 PM
Memories complement RAG and can be combined for enhanced results. Post-hoc memory learning is possible (for Qwen, Gemma, etc), with more ablations in the paper.
This was spearheaded by Hadi Pouransari, with David Grangier, C Thomas, me, and Oncel Tuzel at the Apple Machine Learning Research team :)
This was spearheaded by Hadi Pouransari, with David Grangier, C Thomas, me, and Oncel Tuzel at the Apple Machine Learning Research team :)
🚀 Consider a hypothetical hardware storing a bank with three memory levels:
Anchor model: 0.8GB @ RAM
Level 1: 39GB @ Flash
Level 2: 155GB @ External Disk
Level 3: 618GB @ Cloud
Total fetch time: 38ms (vs. 198ms for a single-level flat memory bank). [9/10]
Anchor model: 0.8GB @ RAM
Level 1: 39GB @ Flash
Level 2: 155GB @ External Disk
Level 3: 618GB @ Cloud
Total fetch time: 38ms (vs. 198ms for a single-level flat memory bank). [9/10]

October 6, 2025 at 4:06 PM
🚀 Consider a hypothetical hardware storing a bank with three memory levels:
Anchor model: 0.8GB @ RAM
Level 1: 39GB @ Flash
Level 2: 155GB @ External Disk
Level 3: 618GB @ Cloud
Total fetch time: 38ms (vs. 198ms for a single-level flat memory bank). [9/10]
Anchor model: 0.8GB @ RAM
Level 1: 39GB @ Flash
Level 2: 155GB @ External Disk
Level 3: 618GB @ Cloud
Total fetch time: 38ms (vs. 198ms for a single-level flat memory bank). [9/10]
💡With hierarchical memories, deeper memories (capturing details) need a larger bank size but require fetching only a few parameters during inference—a great fit for Von Neumann architecture with small-fast to large-slow storage hierarchy. See👇. [8/10]
October 6, 2025 at 4:06 PM
💡With hierarchical memories, deeper memories (capturing details) need a larger bank size but require fetching only a few parameters during inference—a great fit for Von Neumann architecture with small-fast to large-slow storage hierarchy. See👇. [8/10]
💡Information access is controllable with memories.
Unlike typical architectures, the proposed memory bank setup enables controlled parametric knowledge access (e.g., for training data privacy). See the impact of memory bank blocking on performance here: [7/10]
Unlike typical architectures, the proposed memory bank setup enables controlled parametric knowledge access (e.g., for training data privacy). See the impact of memory bank blocking on performance here: [7/10]

October 6, 2025 at 4:06 PM
💡Information access is controllable with memories.
Unlike typical architectures, the proposed memory bank setup enables controlled parametric knowledge access (e.g., for training data privacy). See the impact of memory bank blocking on performance here: [7/10]
Unlike typical architectures, the proposed memory bank setup enables controlled parametric knowledge access (e.g., for training data privacy). See the impact of memory bank blocking on performance here: [7/10]
💡Memories capture long-tail knowledge.
For the text completion task "Atomic number of [element-name] is...", the baseline model (purple) has 17% accuracy for the least frequent elements in DCLM (last bucket). With only 10% added memory, accuracy improves to 83%. [6/10]
For the text completion task "Atomic number of [element-name] is...", the baseline model (purple) has 17% accuracy for the least frequent elements in DCLM (last bucket). With only 10% added memory, accuracy improves to 83%. [6/10]

October 6, 2025 at 4:06 PM
💡Memories capture long-tail knowledge.
For the text completion task "Atomic number of [element-name] is...", the baseline model (purple) has 17% accuracy for the least frequent elements in DCLM (last bucket). With only 10% added memory, accuracy improves to 83%. [6/10]
For the text completion task "Atomic number of [element-name] is...", the baseline model (purple) has 17% accuracy for the least frequent elements in DCLM (last bucket). With only 10% added memory, accuracy improves to 83%. [6/10]
🤔 Which tasks benefit more from memory?
💡 Tasks requiring specific knowledge, like ARC and TriviaQA. Below are categorizations of common pretraining benchmarks based on their knowledge specificity and accuracy improvement when a 410M model is augmented with 10% memory. [5/10]
💡 Tasks requiring specific knowledge, like ARC and TriviaQA. Below are categorizations of common pretraining benchmarks based on their knowledge specificity and accuracy improvement when a 410M model is augmented with 10% memory. [5/10]

October 6, 2025 at 4:06 PM
🤔 Which tasks benefit more from memory?
💡 Tasks requiring specific knowledge, like ARC and TriviaQA. Below are categorizations of common pretraining benchmarks based on their knowledge specificity and accuracy improvement when a 410M model is augmented with 10% memory. [5/10]
💡 Tasks requiring specific knowledge, like ARC and TriviaQA. Below are categorizations of common pretraining benchmarks based on their knowledge specificity and accuracy improvement when a 410M model is augmented with 10% memory. [5/10]
💡Accuracy improves with larger fetched memory and total memory bank sizes.
👇A 160M anchor model, augmented with memories from 1M to 300M parameters, gains over 10 points in accuracy. Two curves show memory bank sizes of 4.6B and 18.7B parameters. [4/10]
👇A 160M anchor model, augmented with memories from 1M to 300M parameters, gains over 10 points in accuracy. Two curves show memory bank sizes of 4.6B and 18.7B parameters. [4/10]

October 6, 2025 at 4:06 PM
💡Accuracy improves with larger fetched memory and total memory bank sizes.
👇A 160M anchor model, augmented with memories from 1M to 300M parameters, gains over 10 points in accuracy. Two curves show memory bank sizes of 4.6B and 18.7B parameters. [4/10]
👇A 160M anchor model, augmented with memories from 1M to 300M parameters, gains over 10 points in accuracy. Two curves show memory bank sizes of 4.6B and 18.7B parameters. [4/10]
🤔 Which parametric memories work best?
💡 We evaluate 1) FFN-memories (extending SwiGLU's internal dimension), 2) LoRA applied to various layers, and 3) Learnable KV. Larger memories perform better, with FFN-memories significantly outperforming others of the same size. [3/10]
💡 We evaluate 1) FFN-memories (extending SwiGLU's internal dimension), 2) LoRA applied to various layers, and 3) Learnable KV. Larger memories perform better, with FFN-memories significantly outperforming others of the same size. [3/10]

October 6, 2025 at 4:06 PM
🤔 Which parametric memories work best?
💡 We evaluate 1) FFN-memories (extending SwiGLU's internal dimension), 2) LoRA applied to various layers, and 3) Learnable KV. Larger memories perform better, with FFN-memories significantly outperforming others of the same size. [3/10]
💡 We evaluate 1) FFN-memories (extending SwiGLU's internal dimension), 2) LoRA applied to various layers, and 3) Learnable KV. Larger memories perform better, with FFN-memories significantly outperforming others of the same size. [3/10]
🤔 How to learn memories?
💡 We cluster the pretraining dataset into thousands of nested clusters, each assigned a memory block. During training, for a document, we optimize anchor model parameters and memory bank parameters for the document's matched clusters. [2/10]
💡 We cluster the pretraining dataset into thousands of nested clusters, each assigned a memory block. During training, for a document, we optimize anchor model parameters and memory bank parameters for the document's matched clusters. [2/10]
October 6, 2025 at 4:06 PM
🤔 How to learn memories?
💡 We cluster the pretraining dataset into thousands of nested clusters, each assigned a memory block. During training, for a document, we optimize anchor model parameters and memory bank parameters for the document's matched clusters. [2/10]
💡 We cluster the pretraining dataset into thousands of nested clusters, each assigned a memory block. During training, for a document, we optimize anchor model parameters and memory bank parameters for the document's matched clusters. [2/10]
But it does not seem impossible. Releasing this benchmark (+ code) to let you take a shot at this new avenue for uncertainty communication. This is a missing building block to enable agentic reasoning in uncertain environments, user trust, conformal calibration. Let’s solve it :)
October 1, 2025 at 9:53 AM
But it does not seem impossible. Releasing this benchmark (+ code) to let you take a shot at this new avenue for uncertainty communication. This is a missing building block to enable agentic reasoning in uncertain environments, user trust, conformal calibration. Let’s solve it :)
Second, we attempted hill-climbing along the benchmark. We already knew Reasoning and CoT can’t do it, now we’ve tried to explicitly SFT/DPO. Result: LLMs can get the format right, but what they output is not what they are actually uncertain about, information-theoretically.
October 1, 2025 at 9:53 AM
Second, we attempted hill-climbing along the benchmark. We already knew Reasoning and CoT can’t do it, now we’ve tried to explicitly SFT/DPO. Result: LLMs can get the format right, but what they output is not what they are actually uncertain about, information-theoretically.
Since its initial release, we didn’t stop cooking: First, we continued validating whether the scores that the SelfReflect benchmarks assigns are robust signals of quality. Across more LLMs and datasets, it works. I have more confidence in the benchmark than ever.
October 1, 2025 at 9:53 AM
Since its initial release, we didn’t stop cooking: First, we continued validating whether the scores that the SelfReflect benchmarks assigns are robust signals of quality. Across more LLMs and datasets, it works. I have more confidence in the benchmark than ever.
This is my first larger project at Apple MLR. 🍏 My collaborators did great things here: Luca Füger, @adamgol.bsky.social , Eeshan Gunesh Dhekane, Arno Blaas, and @sineadwilliamson.bsky.social PS: If you wanna learn more, just let me know, happy to give presentations and chat :)
July 3, 2025 at 9:08 AM
This is my first larger project at Apple MLR. 🍏 My collaborators did great things here: Luca Füger, @adamgol.bsky.social , Eeshan Gunesh Dhekane, Arno Blaas, and @sineadwilliamson.bsky.social PS: If you wanna learn more, just let me know, happy to give presentations and chat :)
If the LLM could do that, it would give users absolute honesty about subjective uncertainties. It could even use it itself to gain clarity about which follow-up questions to ask. We invite you to develop such strategies. Here’s a repo to get started: github.com/apple/ml-sel... 🧵9/9

GitHub - apple/ml-selfreflect
Contribute to apple/ml-selfreflect development by creating an account on GitHub.
github.com
July 3, 2025 at 9:08 AM
If the LLM could do that, it would give users absolute honesty about subjective uncertainties. It could even use it itself to gain clarity about which follow-up questions to ask. We invite you to develop such strategies. Here’s a repo to get started: github.com/apple/ml-sel... 🧵9/9
But it’s not impossible per se. Sampling i.i.d. responses and asking the LLMs to summarize them consistently produces self-reflective strings. This technique is expensive and not elegant. Ideally, an LLM should have a mechanism to do this self-reflection inherently. 🧵8/9
July 3, 2025 at 9:08 AM
But it’s not impossible per se. Sampling i.i.d. responses and asking the LLMs to summarize them consistently produces self-reflective strings. This technique is expensive and not elegant. Ideally, an LLM should have a mechanism to do this self-reflection inherently. 🧵8/9
RQ2: Can LLMs produce such strings that describe their own distributions? We test the most recent LLMs of various sizes, with and without reasoning, with different prompts and CoT. None of them is able to honestly reveal the LLM’s internal distribution. 🧵7/9
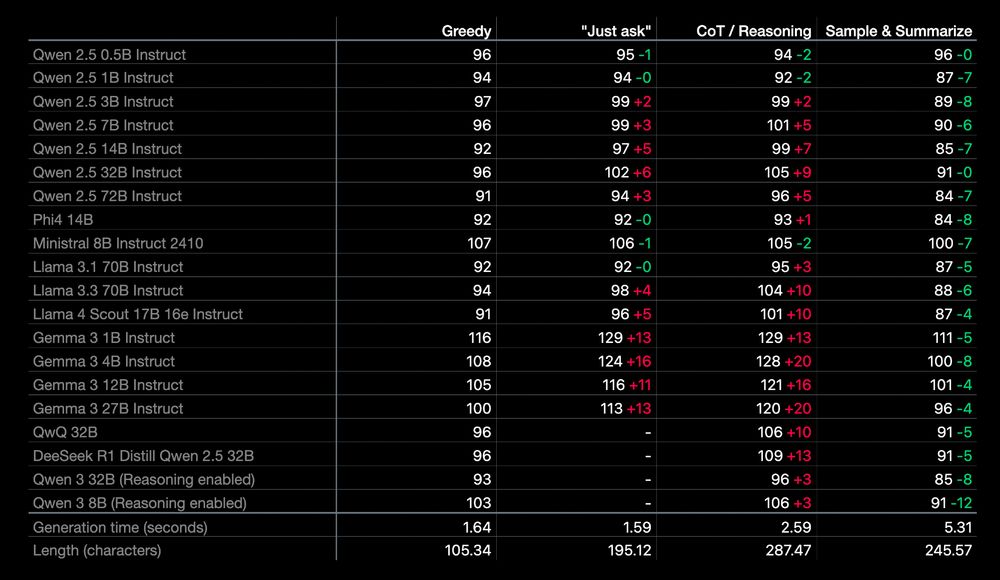
July 3, 2025 at 9:08 AM
RQ2: Can LLMs produce such strings that describe their own distributions? We test the most recent LLMs of various sizes, with and without reasoning, with different prompts and CoT. None of them is able to honestly reveal the LLM’s internal distribution. 🧵7/9